 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Smooth Sea Never Made a Skilled $\texttt{SAILOR}$: Robust Imitation via Learning to Search
Jun 05, 2025



The fundamental limitation of the behavioral cloning (BC) approach to imitation learning is that it only teaches an agent what the expert did at states the expert visited. This means that when a BC agent makes a mistake which takes them out of the support of the demonstrations, they often don't know how to recover from it. In this sense, BC is akin to giving the agent the fish -- giving them dense supervision across a narrow set of states -- rather than teaching them to fish: to be able to reason independently about achieving the expert's outcome even when faced with unseen situations at test-time. In response, we explore learning to search (L2S) from expert demonstrations, i.e. learning the components required to, at test time, plan to match expert outcomes, even after making a mistake. These include (1) a world model and (2) a reward model. We carefully ablate the set of algorithmic and design decisions required to combine these and other components for stable and sample/interaction-efficient learning of recovery behavior without additional human corrections. Across a dozen visual manipulation tasks from three benchmarks, our approach $\texttt{SAILOR}$ consistently out-performs state-of-the-art Diffusion Policies trained via BC on the same data. Furthermore, scaling up the amount of demonstrations used for BC by 5-10$\times$ still leaves a performance gap. We find that $\texttt{SAILOR}$ can identify nuanced failures and is robust to reward hacking. Our code is available at https://github.com/arnavkj1995/SAILOR .
Reflective Planning: Vision-Language Models for Multi-Stage Long-Horizon Robotic Manipulation
Feb 23, 2025



Solving complex long-horizon robotic manipulation problems requires sophisticated high-level planning capabilities, the ability to reason about the physical world, and reactively choose appropriate motor skills. Vision-language models (VLMs) pretrained on Internet data could in principle offer a framework for tackling such problems. However, in their current form, VLMs lack both the nuanced understanding of intricate physics required for robotic manipulation and the ability to reason over long horizons to address error compounding issues. In this paper, we introduce a novel test-time computation framework that enhances VLMs' physical reasoning capabilities for multi-stage manipulation tasks. At its core, our approach iteratively improves a pretrained VLM with a "reflection" mechanism - it uses a generative model to imagine future world states, leverages these predictions to guide action selection, and critically reflects on potential suboptimalities to refine its reasoning. Experimental results demonstrate that our method significantly outperforms several state-of-the-art commercial VLMs as well as other post-training approaches such as Monte Carlo Tree Search (MCTS). Videos are available at https://reflect-vlm.github.io.
Finetuning Offline World Models in the Real World
Oct 24, 2023
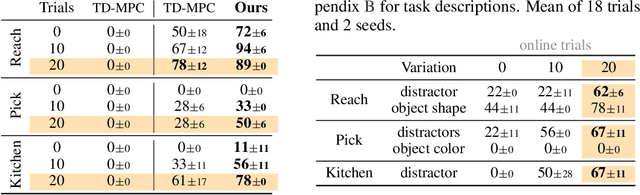


Reinforcement Learning (RL) is notoriously data-inefficient, which makes training on a real robot difficult. While model-based RL algorithms (world models) improve data-efficiency to some extent, they still require hours or days of interaction to learn skills. Recently, offline RL has been proposed as a framework for training RL policies on pre-existing datasets without any online interaction. However, constraining an algorithm to a fixed dataset induces a state-action distribution shift between training and inference, and limits its applicability to new tasks. In this work, we seek to get the best of both worlds: we consider the problem of pretraining a world model with offline data collected on a real robot, and then finetuning the model on online data collected by planning with the learned model. To mitigate extrapolation errors during online interaction, we propose to regularize the planner at test-time by balancing estimated returns and (epistemic) model uncertainty. We evaluate our method on a variety of visuo-motor control tasks in simulation and on a real robot, and find that our method enables few-shot finetuning to seen and unseen tasks even when offline data is limited. Videos, code, and data are available at https://yunhaifeng.com/FOWM .
Exploring Visual Pre-training for Robot Manipulation: Datasets, Models and Methods
Aug 07, 2023



Visual pre-training with large-scale real-world data has made great progress in recent years, showing great potential in robot learning with pixel observations. However, the recipes of visual pre-training for robot manipulation tasks are yet to be built. In this paper, we thoroughly investigate the effects of visual pre-training strategies on robot manipulation tasks from three fundamental perspectives: pre-training datasets, model architectures and training methods. Several significant experimental findings are provided that are beneficial for robot learning. Further, we propose a visual pre-training scheme for robot manipulation termed Vi-PRoM, which combines self-supervised learning and supervised learning. Concretely, the former employs contrastive learning to acquire underlying patterns from large-scale unlabeled data, while the latter aims learning visual semantics and temporal dynamics. Extensive experiments on robot manipulations in various simulation environments and the real robot demonstrate the superiority of the proposed scheme. Videos and more details can be found on \url{https://explore-pretrain-robot.github.io}.
SAM-RL: Sensing-Aware Model-Based Reinforcement Learning via Differentiable Physics-Based Simulation and Rendering
Oct 27, 2022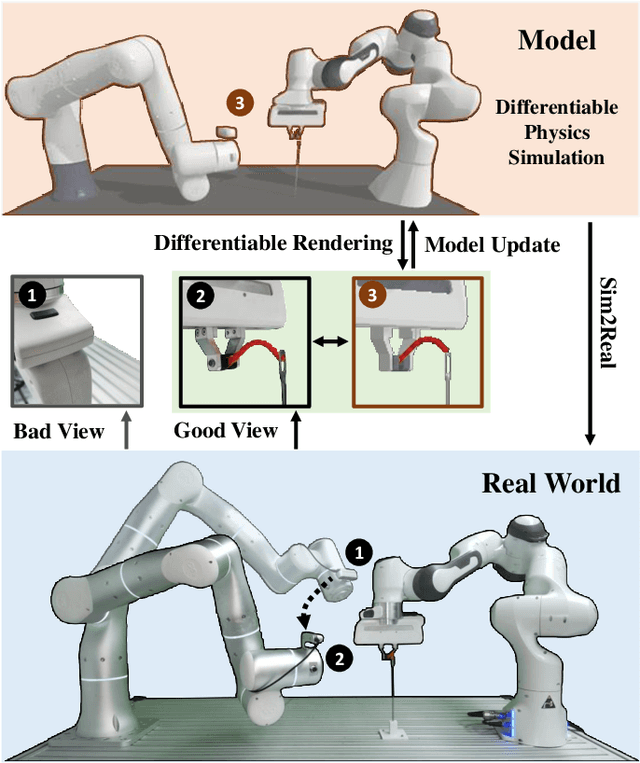


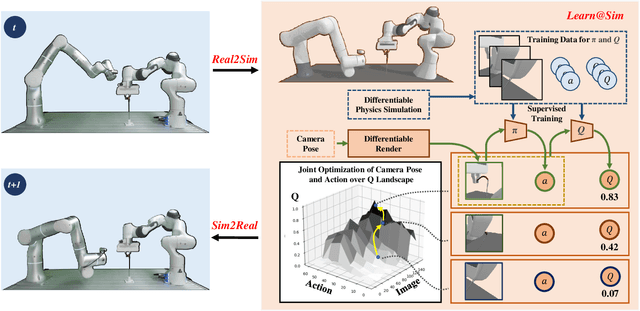
Model-based reinforcement learning (MBRL) is recognized with the potential to be significantly more sample efficient than model-free RL. How an accurate model can be developed automatically and efficiently from raw sensory inputs (such as images), especially for complex environments and tasks, is a challenging problem that hinders the broad application of MBRL in the real world. In this work, we propose a sensing-aware model-based reinforcement learning system called SAM-RL. Leveraging the differentiable physics-based simulation and rendering, SAM-RL automatically updates the model by comparing rendered images with real raw images and produces the policy efficiently. With the sensing-aware learning pipeline, SAM-RL allows a robot to select an informative viewpoint to monitor the task process. We apply our framework to real-world experiments for accomplishing three manipulation tasks: robotic assembly, tool manipulation, and deformable object manipulation. We demonstrate the effectiveness of SAM-RL via extensive experiments. Supplemental materials and videos are available on our project webpage at https://sites.google.com/view/sam-rl.