 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD^3ETOR: Debate-Enhanced Pseudo Labeling and Frequency-Aware Progressive Debiasing for Weakly-Supervised Camouflaged Object Detection with Scribble Annotations
Jan 06, 2026Weakly-Supervised Camouflaged Object Detection (WSCOD) aims to locate and segment objects that are visually concealed within their surrounding scenes, relying solely on sparse supervision such as scribble annotations. Despite recent progress, existing WSCOD methods still lag far behind fully supervised ones due to two major limitations: (1) the pseudo masks generated by general-purpose segmentation models (e.g., SAM) and filtered via rules are often unreliable, as these models lack the task-specific semantic understanding required for effective pseudo labeling in COD; and (2) the neglect of inherent annotation bias in scribbles, which hinders the model from capturing the global structure of camouflaged objects. To overcome these challenges, we propose ${D}^{3}$ETOR, a two-stage WSCOD framework consisting of Debate-Enhanced Pseudo Labeling and Frequency-Aware Progressive Debiasing. In the first stage, we introduce an adaptive entropy-driven point sampling method and a multi-agent debate mechanism to enhance the capability of SAM for COD, improving the interpretability and precision of pseudo masks. In the second stage, we design FADeNet, which progressively fuses multi-level frequency-aware features to balance global semantic understanding with local detail modeling, while dynamically reweighting supervision strength across regions to alleviate scribble bias. By jointly exploiting the supervision signals from both the pseudo masks and scribble semantics, ${D}^{3}$ETOR significantly narrows the gap between weakly and fully supervised COD, achieving state-of-the-art performance on multiple benchmarks.
${D}^{3}${ETOR}: ${D}$ebate-Enhanced Pseudo Labeling and Frequency-Aware Progressive ${D}$ebiasing for Weakly-Supervised Camouflaged Object ${D}$etection with Scribble Annotations
Dec 23, 2025Weakly-Supervised Camouflaged Object Detection (WSCOD) aims to locate and segment objects that are visually concealed within their surrounding scenes, relying solely on sparse supervision such as scribble annotations. Despite recent progress, existing WSCOD methods still lag far behind fully supervised ones due to two major limitations: (1) the pseudo masks generated by general-purpose segmentation models (e.g., SAM) and filtered via rules are often unreliable, as these models lack the task-specific semantic understanding required for effective pseudo labeling in COD; and (2) the neglect of inherent annotation bias in scribbles, which hinders the model from capturing the global structure of camouflaged objects. To overcome these challenges, we propose ${D}^{3}$ETOR, a two-stage WSCOD framework consisting of Debate-Enhanced Pseudo Labeling and Frequency-Aware Progressive Debiasing. In the first stage, we introduce an adaptive entropy-driven point sampling method and a multi-agent debate mechanism to enhance the capability of SAM for COD, improving the interpretability and precision of pseudo masks. In the second stage, we design FADeNet, which progressively fuses multi-level frequency-aware features to balance global semantic understanding with local detail modeling, while dynamically reweighting supervision strength across regions to alleviate scribble bias. By jointly exploiting the supervision signals from both the pseudo masks and scribble semantics, ${D}^{3}$ETOR significantly narrows the gap between weakly and fully supervised COD, achieving state-of-the-art performance on multiple benchmarks.
MSCI: Addressing CLIP's Inherent Limitations for Compositional Zero-Shot Learning
May 15, 2025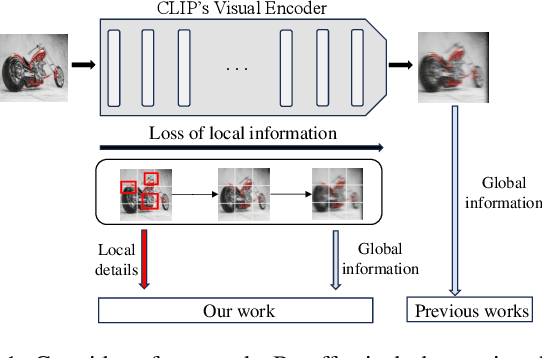
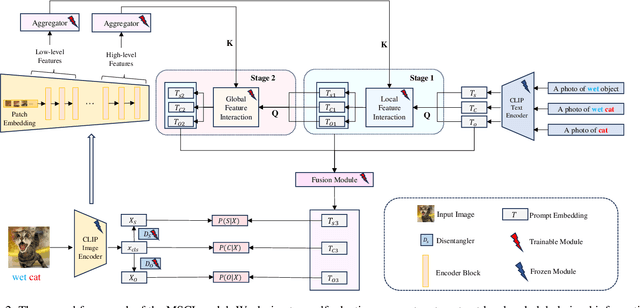
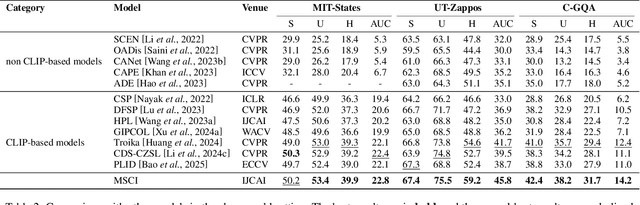
Compositional Zero-Shot Learning (CZSL) aims to recognize unseen state-object combinations by leveraging known combinations. Existing studies basically rely on the cross-modal alignment capabilities of CLIP but tend to overlook its limitations in capturing fine-grained local features, which arise from its architectural and training paradigm. To address this issue, we propose a Multi-Stage Cross-modal Interaction (MSCI) model that effectively explores and utilizes intermediate-layer information from CLIP's visual encoder. Specifically, we design two self-adaptive aggregators to extract local information from low-level visual features and integrate global information from high-level visual features, respectively. These key information are progressively incorporated into textual representations through a stage-by-stage interaction mechanism, significantly enhancing the model's perception capability for fine-grained local visual information. Additionally, MSCI dynamically adjusts the attention weights between global and local visual information based on different combinations, as well as different elements within the same combination, allowing it to flexibly adapt to diverse scenarios. Experiments on three widely used datasets fully validate the effectiveness and superiority of the proposed model. Data and code are available at https://github.com/ltpwy/MSCI.
Context-Enhanced Video Moment Retrieval with Large Language Models
May 21, 2024Current methods for Video Moment Retrieval (VMR) struggle to align complex situations involving specific environmental details, character descriptions, and action narratives. To tackle this issue, we propose a Large Language Model-guided Moment Retrieval (LMR) approach that employs the extensive knowledge of Large Language Models (LLMs) to improve video context representation as well as cross-modal alignment, facilitating accurate localization of target moments. Specifically, LMR introduces a context enhancement technique with LLMs to generate crucial target-related context semantics. These semantics are integrated with visual features for producing discriminative video representations. Finally, a language-conditioned transformer is designed to decode free-form language queries, on the fly, using aligned video representations for moment retrieval. Extensive experiments demonstrate that LMR achieves state-of-the-art results, outperforming the nearest competitor by up to 3.28\% and 4.06\% on the challenging QVHighlights and Charades-STA benchmarks, respectively. More importantly, the performance gains are significantly higher for localization of complex queries.
Query-Based Knowledge Sharing for Open-Vocabulary Multi-Label Classification
Jan 02, 2024Identifying labels that did not appear during training, known as multi-label zero-shot learning, is a non-trivial task in computer vision. To this end, recent studies have attempted to explore the multi-modal knowledge of vision-language pre-training (VLP) models by knowledge distillation, allowing to recognize unseen labels in an open-vocabulary manner. However, experimental evidence shows that knowledge distillation is suboptimal and provides limited performance gain in unseen label prediction. In this paper, a novel query-based knowledge sharing paradigm is proposed to explore the multi-modal knowledge from the pretrained VLP model for open-vocabulary multi-label classification. Specifically, a set of learnable label-agnostic query tokens is trained to extract critical vision knowledge from the input image, and further shared across all labels, allowing them to select tokens of interest as visual clues for recognition. Besides, we propose an effective prompt pool for robust label embedding, and reformulate the standard ranking learning into a form of classification to allow the magnitude of feature vectors for matching, which both significantly benefit label recognition. Experimental results show that our framework significantly outperforms state-of-the-art methods on zero-shot task by 5.9% and 4.5% in mAP on the NUS-WIDE and Open Images, respectively.
Text as Image: Learning Transferable Adapter for Multi-Label Classification
Dec 07, 2023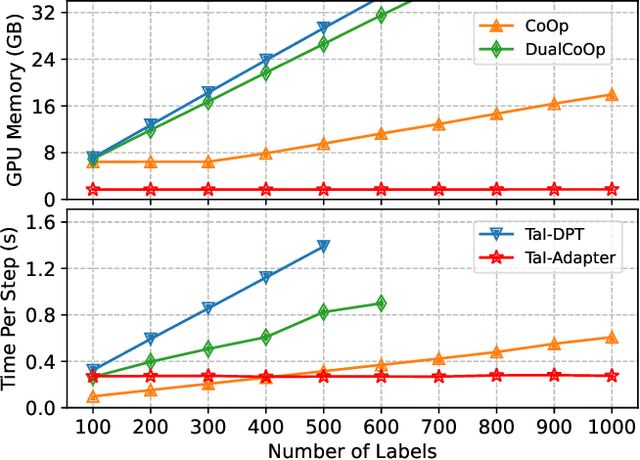



Pre-trained vision-language models have notably accelerated progress of open-world concept recognition. Their impressive zero-shot ability has recently been transferred to multi-label image classification via prompt tuning, enabling to discover novel labels in an open-vocabulary manner. However, this paradigm suffers from non-trivial training costs, and becomes computationally prohibitive for a large number of candidate labels. To address this issue, we note that vision-language pre-training aligns images and texts in a unified embedding space, making it potential for an adapter network to identify labels in visual modality while be trained in text modality. To enhance such cross-modal transfer ability, a simple yet effective method termed random perturbation is proposed, which enables the adapter to search for potential visual embeddings by perturbing text embeddings with noise during training, resulting in better performance in visual modality. Furthermore, we introduce an effective approach to employ large language models for multi-label instruction-following text generation. In this way, a fully automated pipeline for visual label recognition is developed without relying on any manual data. Extensive experiments on public benchmarks show the superiority of our method in various multi-label classification tasks.
Beyond Visual Cues: Synchronously Exploring Target-Centric Semantics for Vision-Language Tracking
Nov 28, 2023
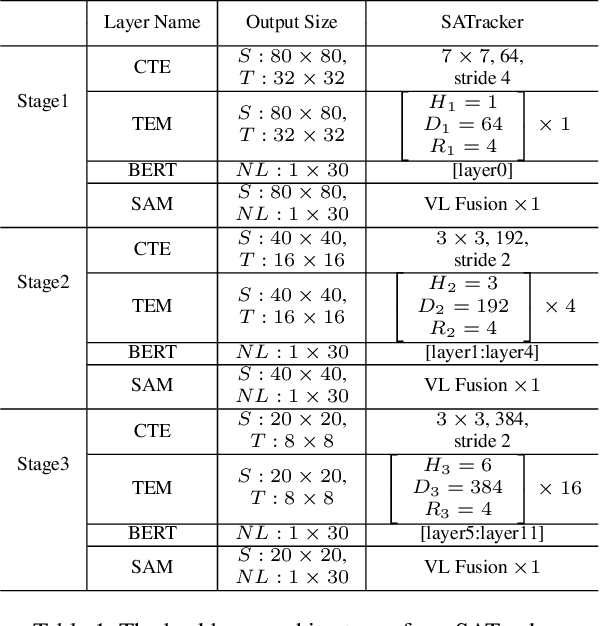


Single object tracking aims to locate one specific target in video sequences, given its initial state. Classical trackers rely solely on visual cues, restricting their ability to handle challenges such as appearance variations, ambiguity, and distractions. Hence, Vision-Language (VL) tracking has emerged as a promising approach, incorporating language descriptions to directly provide high-level semantics and enhance tracking performance. However, current VL trackers have not fully exploited the power of VL learning, as they suffer from limitations such as heavily relying on off-the-shelf backbones for feature extraction, ineffective VL fusion designs, and the absence of VL-related loss functions. Consequently, we present a novel tracker that progressively explores target-centric semantics for VL tracking. Specifically, we propose the first Synchronous Learning Backbone (SLB) for VL tracking, which consists of two novel modules: the Target Enhance Module (TEM) and the Semantic Aware Module (SAM). These modules enable the tracker to perceive target-related semantics and comprehend the context of both visual and textual modalities at the same pace, facilitating VL feature extraction and fusion at different semantic levels. Moreover, we devise the dense matching loss to further strengthen multi-modal representation learning. Extensive experiments on VL tracking datasets demonstrate the superiority and effectiveness of our methods.
Exploring Visual Pre-training for Robot Manipulation: Datasets, Models and Methods
Aug 07, 2023



Visual pre-training with large-scale real-world data has made great progress in recent years, showing great potential in robot learning with pixel observations. However, the recipes of visual pre-training for robot manipulation tasks are yet to be built. In this paper, we thoroughly investigate the effects of visual pre-training strategies on robot manipulation tasks from three fundamental perspectives: pre-training datasets, model architectures and training methods. Several significant experimental findings are provided that are beneficial for robot learning. Further, we propose a visual pre-training scheme for robot manipulation termed Vi-PRoM, which combines self-supervised learning and supervised learning. Concretely, the former employs contrastive learning to acquire underlying patterns from large-scale unlabeled data, while the latter aims learning visual semantics and temporal dynamics. Extensive experiments on robot manipulations in various simulation environments and the real robot demonstrate the superiority of the proposed scheme. Videos and more details can be found on \url{https://explore-pretrain-robot.github.io}.
Balanced Symmetric Cross Entropy for Large Scale Imbalanced and Noisy Data
Jul 03, 2020



Deep convolution neural network has attracted many attentions in large-scale visual classification task, and achieves significant performance improvement compared to traditional visual analysis methods. In this paper, we explore many kinds of deep convolution neural network architectures for large-scale product recognition task, which is heavily class-imbalanced and noisy labeled data, making it more challenged. Extensive experiments show that PNASNet achieves best performance among a variety of convolutional architectures. Together with ensemble technology and negative learning loss for noisy labeled data, we further improve the model performance on online test data. Finally, our proposed method achieves 0.1515 mean top-1 error on online test data.