 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangMap: A Hierarchical Benchmark for Open-Vocabulary Goal Navigation
Feb 02, 2026The relationships between objects and language are fundamental to meaningful communication between humans and AI, and to practically useful embodied intelligence. We introduce HieraNav, a multi-granularity, open-vocabulary goal navigation task where agents interpret natural language instructions to reach targets at four semantic levels: scene, room, region, and instance. To this end, we present Language as a Map (LangMap), a large-scale benchmark built on real-world 3D indoor scans with comprehensive human-verified annotations and tasks spanning these levels. LangMap provides region labels, discriminative region descriptions, discriminative instance descriptions covering 414 object categories, and over 18K navigation tasks. Each target features both concise and detailed descriptions, enabling evaluation across different instruction styles. LangMap achieves superior annotation quality, outperforming GOAT-Bench by 23.8% in discriminative accuracy using four times fewer words. Comprehensive evaluations of zero-shot and supervised models on LangMap reveal that richer context and memory improve success, while long-tailed, small, context-dependent, and distant goals, as well as multi-goal completion, remain challenging. HieraNav and LangMap establish a rigorous testbed for advancing language-driven embodied navigation. Project: https://bo-miao.github.io/LangMap
Referring Human Pose and Mask Estimation in the Wild
Oct 27, 2024We introduce Referring Human Pose and Mask Estimation (R-HPM) in the wild, where either a text or positional prompt specifies the person of interest in an image. This new task holds significant potential for human-centric applications such as assistive robotics and sports analysis. In contrast to previous works, R-HPM (i) ensures high-quality, identity-aware results corresponding to the referred person, and (ii) simultaneously predicts human pose and mask for a comprehensive representation. To achieve this, we introduce a large-scale dataset named RefHuman, which substantially extends the MS COCO dataset with additional text and positional prompt annotations. RefHuman includes over 50,000 annotated instances in the wild, each equipped with keypoint, mask, and prompt annotations. To enable prompt-conditioned estimation, we propose the first end-to-end promptable approach named UniPHD for R-HPM. UniPHD extracts multimodal representations and employs a proposed pose-centric hierarchical decoder to process (text or positional) instance queries and keypoint queries, producing results specific to the referred person. Extensive experiments demonstrate that UniPHD produces quality results based on user-friendly prompts and achieves top-tier performance on RefHuman val and MS COCO val2017. Data and Code: https://github.com/bo-miao/RefHuman
Context-Enhanced Video Moment Retrieval with Large Language Models
May 21, 2024Current methods for Video Moment Retrieval (VMR) struggle to align complex situations involving specific environmental details, character descriptions, and action narratives. To tackle this issue, we propose a Large Language Model-guided Moment Retrieval (LMR) approach that employs the extensive knowledge of Large Language Models (LLMs) to improve video context representation as well as cross-modal alignment, facilitating accurate localization of target moments. Specifically, LMR introduces a context enhancement technique with LLMs to generate crucial target-related context semantics. These semantics are integrated with visual features for producing discriminative video representations. Finally, a language-conditioned transformer is designed to decode free-form language queries, on the fly, using aligned video representations for moment retrieval. Extensive experiments demonstrate that LMR achieves state-of-the-art results, outperforming the nearest competitor by up to 3.28\% and 4.06\% on the challenging QVHighlights and Charades-STA benchmarks, respectively. More importantly, the performance gains are significantly higher for localization of complex queries.
Towards Temporally Consistent Referring Video Object Segmentation
Mar 28, 2024
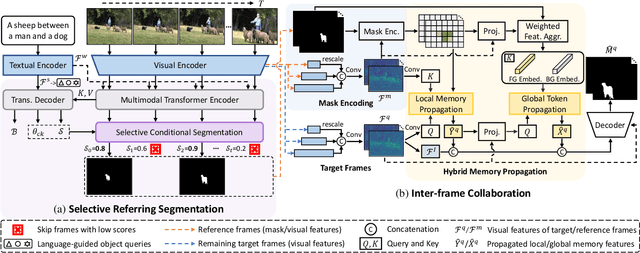


Referring Video Object Segmentation (R-VOS) methods face challenges in maintaining consistent object segmentation due to temporal context variability and the presence of other visually similar objects. We propose an end-to-end R-VOS paradigm that explicitly models temporal instance consistency alongside the referring segmentation. Specifically, we introduce a novel hybrid memory that facilitates inter-frame collaboration for robust spatio-temporal matching and propagation. Features of frames with automatically generated high-quality reference masks are propagated to segment the remaining frames based on multi-granularity association to achieve temporally consistent R-VOS. Furthermore, we propose a new Mask Consistency Score (MCS) metric to evaluate the temporal consistency of video segmentation. Extensive experiments demonstrate that our approach enhances temporal consistency by a significant margin, leading to top-ranked performance on popular R-VOS benchmarks, i.e., Ref-YouTube-VOS (67.1%) and Ref-DAVIS17 (65.6%).
External Knowledge Enhanced 3D Scene Generation from Sketch
Mar 21, 2024



Generating realistic 3D scenes is challenging due to the complexity of room layouts and object geometries.We propose a sketch based knowledge enhanced diffusion architecture (SEK) for generating customized, diverse, and plausible 3D scenes. SEK conditions the denoising process with a hand-drawn sketch of the target scene and cues from an object relationship knowledge base. We first construct an external knowledge base containing object relationships and then leverage knowledge enhanced graph reasoning to assist our model in understanding hand-drawn sketches. A scene is represented as a combination of 3D objects and their relationships, and then incrementally diffused to reach a Gaussian distribution.We propose a 3D denoising scene transformer that learns to reverse the diffusion process, conditioned by a hand-drawn sketch along with knowledge cues, to regressively generate the scene including the 3D object instances as well as their layout. Experiments on the 3D-FRONT dataset show that our model improves FID, CKL by 17.41%, 37.18% in 3D scene generation and FID, KID by 19.12%, 20.06% in 3D scene completion compared to the nearest competitor DiffuScene.
Spectrum-guided Multi-granularity Referring Video Object Segmentation
Jul 25, 2023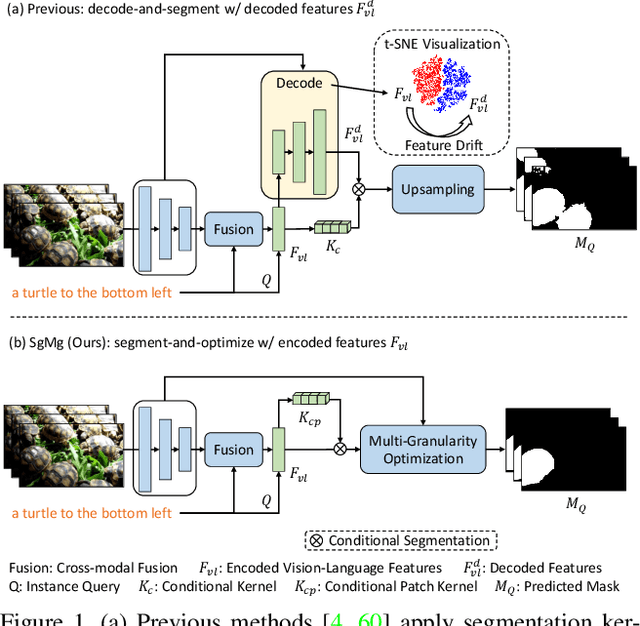


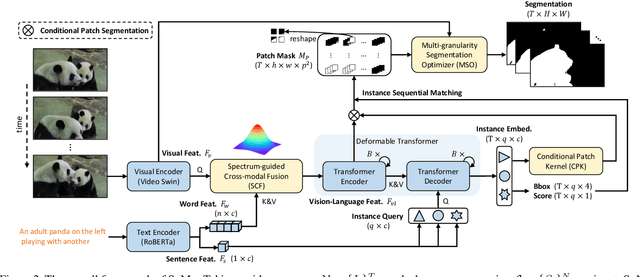
Current referring video object segmentation (R-VOS) techniques extract conditional kernels from encoded (low-resolution) vision-language features to segment the decoded high-resolution features. We discovered that this causes significant feature drift, which the segmentation kernels struggle to perceive during the forward computation. This negatively affects the ability of segmentation kernels. To address the drift problem, we propose a Spectrum-guided Multi-granularity (SgMg) approach, which performs direct segmentation on the encoded features and employs visual details to further optimize the masks. In addition, we propose Spectrum-guided Cross-modal Fusion (SCF) to perform intra-frame global interactions in the spectral domain for effective multimodal representation. Finally, we extend SgMg to perform multi-object R-VOS, a new paradigm that enables simultaneous segmentation of multiple referred objects in a video. This not only makes R-VOS faster, but also more practical. Extensive experiments show that SgMg achieves state-of-the-art performance on four video benchmark datasets, outperforming the nearest competitor by 2.8% points on Ref-YouTube-VOS. Our extended SgMg enables multi-object R-VOS, runs about 3 times faster while maintaining satisfactory performance. Code is available at https://github.com/bo-miao/SgMg.
Region Aware Video Object Segmentation with Deep Motion Modeling
Jul 21, 2022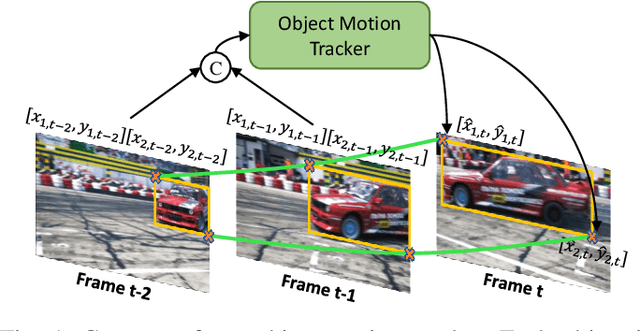
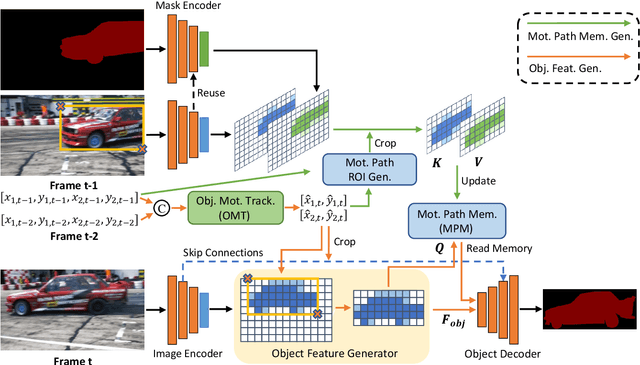

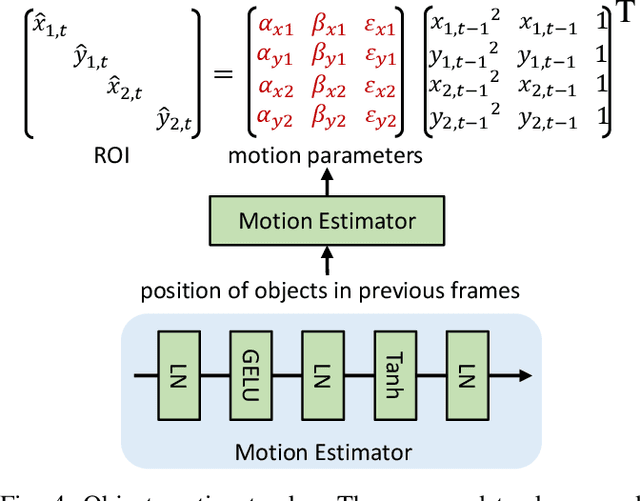
Current semi-supervised video object segmentation (VOS) methods usually leverage the entire features of one frame to predict object masks and update memory. This introduces significant redundant computations. To reduce redundancy, we present a Region Aware Video Object Segmentation (RAVOS) approach that predicts regions of interest (ROIs) for efficient object segmentation and memory storage. RAVOS includes a fast object motion tracker to predict their ROIs in the next frame. For efficient segmentation, object features are extracted according to the ROIs, and an object decoder is designed for object-level segmentation. For efficient memory storage, we propose motion path memory to filter out redundant context by memorizing the features within the motion path of objects between two frames. Besides RAVOS, we also propose a large-scale dataset, dubbed OVOS, to benchmark the performance of VOS models under occlusions. Evaluation on DAVIS and YouTube-VOS benchmarks and our new OVOS dataset show that our method achieves state-of-the-art performance with significantly faster inference time, e.g., 86.1 J&F at 42 FPS on DAVIS and 84.4 J&F at 23 FPS on YouTube-VOS.
Object-to-Scene: Learning to Transfer Object Knowledge to Indoor Scene Recognition
Aug 01, 2021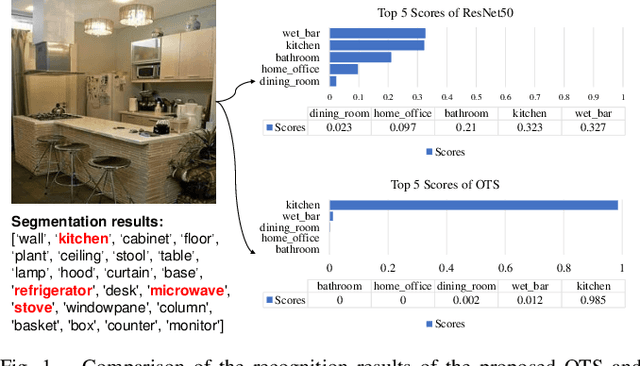
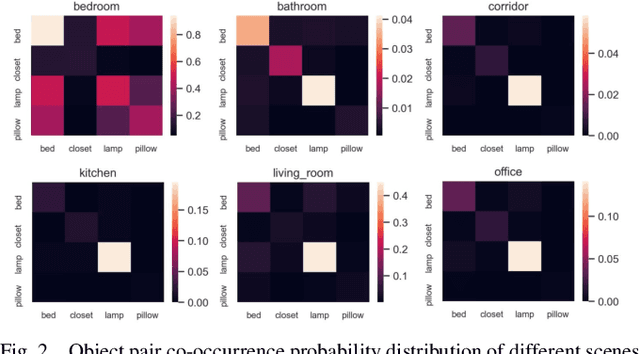
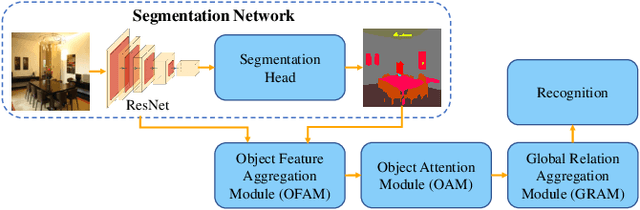
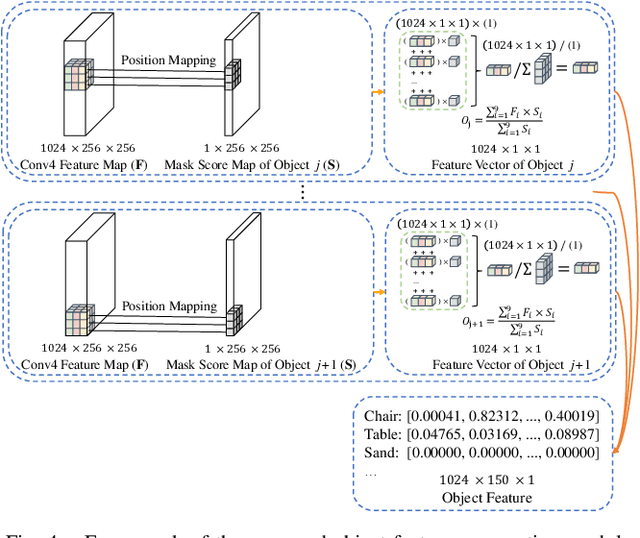
Accurate perception of the surrounding scene is helpful for robots to make reasonable judgments and behaviours. Therefore, developing effective scene representation and recognition methods are of significant importance in robotics. Currently, a large body of research focuses on developing novel auxiliary features and networks to improve indoor scene recognition ability. However, few of them focus on directly constructing object features and relations for indoor scene recognition. In this paper, we analyze the weaknesses of current methods and propose an Object-to-Scene (OTS) method, which extracts object features and learns object relations to recognize indoor scenes. The proposed OTS first extracts object features based on the segmentation network and the proposed object feature aggregation module (OFAM). Afterwards, the object relations are calculated and the scene representation is constructed based on the proposed object attention module (OAM) and global relation aggregation module (GRAM). The final results in this work show that OTS successfully extracts object features and learns object relations from the segmentation network. Moreover, OTS outperforms the state-of-the-art methods by more than 2\% on indoor scene recognition without using any additional streams. Code is publicly available at: https://github.com/FreeformRobotics/OTS.
Self-Supervised Video Object Segmentation by Motion-Aware Mask Propagation
Jul 27, 2021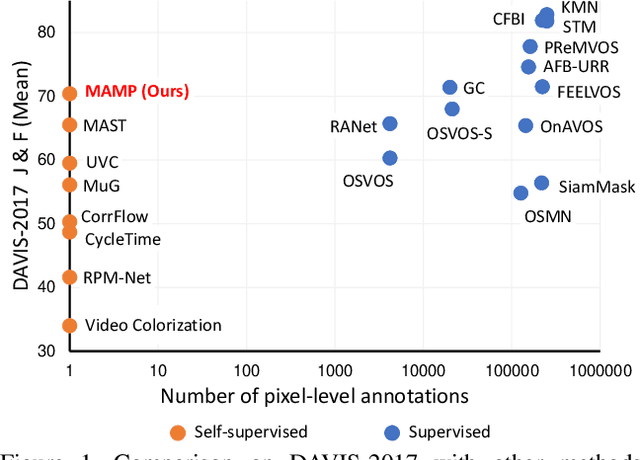

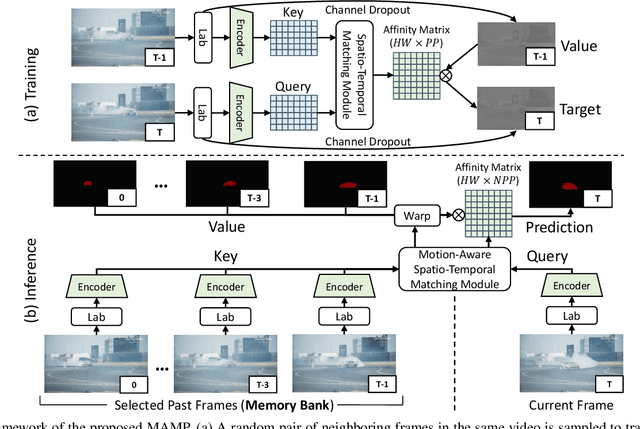
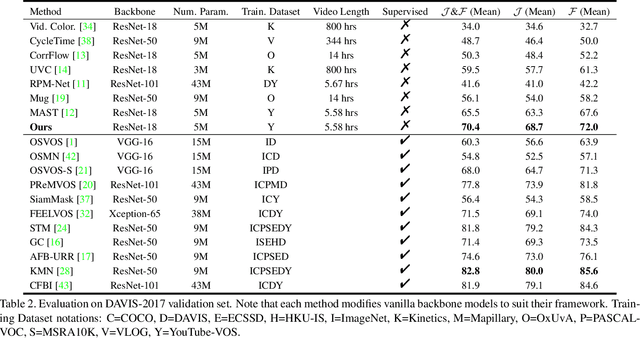
We propose a self-supervised spatio-temporal matching method coined Motion-Aware Mask Propagation (MAMP) for semi-supervised video object segmentation. During training, MAMP leverages the frame reconstruction task to train the model without the need for annotations. During inference, MAMP extracts high-resolution features from each frame to build a memory bank from the features as well as the predicted masks of selected past frames. MAMP then propagates the masks from the memory bank to subsequent frames according to our motion-aware spatio-temporal matching module, also proposed in this paper. Evaluation on DAVIS-2017 and YouTube-VOS datasets show that MAMP achieves state-of-the-art performance with stronger generalization ability compared to existing self-supervised methods, i.e. 4.9\% higher mean $\mathcal{J}\&\mathcal{F}$ on DAVIS-2017 and 4.85\% higher mean $\mathcal{J}\&\mathcal{F}$ on the unseen categories of YouTube-VOS than the nearest competitor. Moreover, MAMP performs on par with many supervised video object segmentation methods. Our code is available at: \url{https://github.com/bo-miao/MAMP}.