 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Temporally Consistent Referring Video Object Segmentation
Paper and Code
Mar 28, 2024
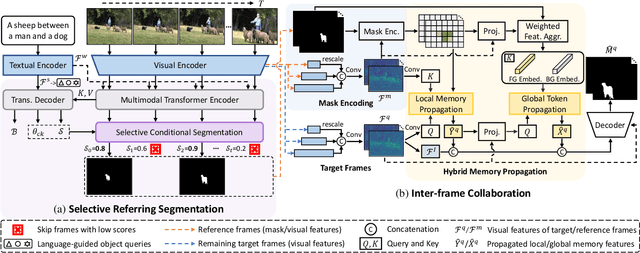


Referring Video Object Segmentation (R-VOS) methods face challenges in maintaining consistent object segmentation due to temporal context variability and the presence of other visually similar objects. We propose an end-to-end R-VOS paradigm that explicitly models temporal instance consistency alongside the referring segmentation. Specifically, we introduce a novel hybrid memory that facilitates inter-frame collaboration for robust spatio-temporal matching and propagation. Features of frames with automatically generated high-quality reference masks are propagated to segment the remaining frames based on multi-granularity association to achieve temporally consistent R-VOS. Furthermore, we propose a new Mask Consistency Score (MCS) metric to evaluate the temporal consistency of video segmentation. Extensive experiments demonstrate that our approach enhances temporal consistency by a significant margin, leading to top-ranked performance on popular R-VOS benchmarks, i.e., Ref-YouTube-VOS (67.1%) and Ref-DAVIS17 (65.6%).