 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDesc3D: Towards Layout-Aware 3D Indoor Scene Generation from Short Descriptions
Apr 02, 20263D indoor scene generation conditioned on short textual descriptions provides a promising avenue for interactive 3D environment construction without the need for labor-intensive layout specification. Despite recent progress in text-conditioned 3D scene generation, existing works suffer from poor physical plausibility and insufficient detail richness in such semantic condensation cases, largely due to their reliance on explicit semantic cues about compositional objects and their spatial relationships. This limitation highlights the need for enhanced 3D reasoning capabilities, particularly in terms of prior integration and spatial anchoring.Motivated by this, we propose SDesc3D, a short-text conditioned 3D indoor scene generation framework, that leverages multi-view structural priors and regional functionality implications to enable 3D layout reasoning under sparse textual guidance.Specifically, we introduce a Multi-view scene prior augmentation that enriches underspecified textual inputs with aggregated multi-view structural knowledge, shifting from inaccessible semantic relation cues to multi-view relational prior aggregation. Building on this, we design a Functionality-aware layout grounding, employing regional functionality grounding for implicit spatial anchors and conducting hierarchical layout reasoning to enhance scene organization and semantic plausibility.Furthermore, an Iterative reflection-rectification scheme is employed for progressive structural plausibility refinement via self-rectification.Extensive experiments show that our method outperforms existing approaches on short-text conditioned 3D indoor scene generation.Code will be publicly available.
SeqAffordSplat: Scene-level Sequential Affordance Reasoning on 3D Gaussian Splatting
Jul 31, 20253D affordance reasoning, the task of associating human instructions with the functional regions of 3D objects, is a critical capability for embodied agents. Current methods based on 3D Gaussian Splatting (3DGS) are fundamentally limited to single-object, single-step interactions, a paradigm that falls short of addressing the long-horizon, multi-object tasks required for complex real-world applications. To bridge this gap, we introduce the novel task of Sequential 3D Gaussian Affordance Reasoning and establish SeqAffordSplat, a large-scale benchmark featuring 1800+ scenes to support research on long-horizon affordance understanding in complex 3DGS environments. We then propose SeqSplatNet, an end-to-end framework that directly maps an instruction to a sequence of 3D affordance masks. SeqSplatNet employs a large language model that autoregressively generates text interleaved with special segmentation tokens, guiding a conditional decoder to produce the corresponding 3D mask. To handle complex scene geometry, we introduce a pre-training strategy, Conditional Geometric Reconstruction, where the model learns to reconstruct complete affordance region masks from known geometric observations, thereby building a robust geometric prior. Furthermore, to resolve semantic ambiguities, we design a feature injection mechanism that lifts rich semantic features from 2D Vision Foundation Models (VFM) and fuses them into the 3D decoder at multiple scales. Extensive experiments demonstrate that our method sets a new state-of-the-art on our challenging benchmark, effectively advancing affordance reasoning from single-step interactions to complex, sequential tasks at the scene level.
Controlled Data Rebalancing in Multi-Task Learning for Real-World Image Super-Resolution
Jun 05, 2025Real-world image super-resolution (Real-SR) is a challenging problem due to the complex degradation patterns in low-resolution images. Unlike approaches that assume a broadly encompassing degradation space, we focus specifically on achieving an optimal balance in how SR networks handle different degradation patterns within a fixed degradation space. We propose an improved paradigm that frames Real-SR as a data-heterogeneous multi-task learning problem, our work addresses task imbalance in the paradigm through coordinated advancements in task definition, imbalance quantification, and adaptive data rebalancing. Specifically, we introduce a novel task definition framework that segments the degradation space by setting parameter-specific boundaries for degradation operators, effectively reducing the task quantity while maintaining task discrimination. We then develop a focal loss based multi-task weighting mechanism that precisely quantifies task imbalance dynamics during model training. Furthermore, to prevent sporadic outlier samples from dominating the gradient optimization of the shared multi-task SR model, we strategically convert the quantified task imbalance into controlled data rebalancing through deliberate regulation of task-specific training volumes. Extensive quantitative and qualitative experiments demonstrate that our method achieves consistent superiority across all degradation tasks.
PointDiffuse: A Dual-Conditional Diffusion Model for Enhanced Point Cloud Semantic Segmentation
Mar 11, 2025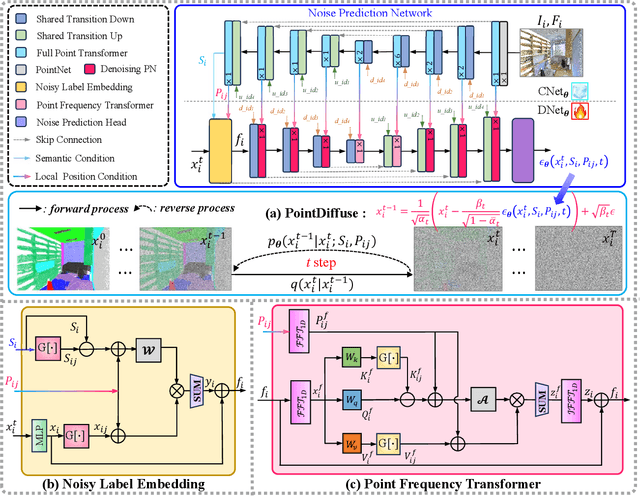



Diffusion probabilistic models are traditionally used to generate colors at fixed pixel positions in 2D images. Building on this, we extend diffusion models to point cloud semantic segmentation, where point positions also remain fixed, and the diffusion model generates point labels instead of colors. To accelerate the denoising process in reverse diffusion, we introduce a noisy label embedding mechanism. This approach integrates semantic information into the noisy label, providing an initial semantic reference that improves the reverse diffusion efficiency. Additionally, we propose a point frequency transformer that enhances the adjustment of high-level context in point clouds. To reduce computational complexity, we introduce the position condition into MLP and propose denoising PointNet to process the high-resolution point cloud without sacrificing geometric details. Finally, we integrate the proposed noisy label embedding, point frequency transformer and denoising PointNet in our proposed dual conditional diffusion model-based network (PointDiffuse) to perform large-scale point cloud semantic segmentation. Extensive experiments on five benchmarks demonstrate the superiority of PointDiffuse, achieving the state-of-the-art mIoU of 74.2\% on S3DIS Area 5, 81.2\% on S3DIS 6-fold and 64.8\% on SWAN dataset.
Multiview Point Cloud Registration Based on Minimum Potential Energy for Free-Form Blade Measurement
Feb 11, 2025Point cloud registration is an essential step for free-form blade reconstruction in industrial measurement. Nonetheless, measuring defects of the 3D acquisition system unavoidably result in noisy and incomplete point cloud data, which renders efficient and accurate registration challenging. In this paper, we propose a novel global registration method that is based on the minimum potential energy (MPE) method to address these problems. The basic strategy is that the objective function is defined as the minimum potential energy optimization function of the physical registration system. The function distributes more weight to the majority of inlier points and less weight to the noise and outliers, which essentially reduces the influence of perturbations in the mathematical formulation. We decompose the solution into a globally optimal approximation procedure and a fine registration process with the trimmed iterative closest point algorithm to boost convergence. The approximation procedure consists of two main steps. First, according to the construction of the force traction operator, we can simply compute the position of the potential energy minimum. Second, to find the MPE point, we propose a new theory that employs two flags to observe the status of the registration procedure. We demonstrate the performance of the proposed algorithm on four types of blades. The proposed method outperforms the other global methods in terms of both accuracy and noise resistance.
Decoupled Sparse Priors Guided Diffusion Compression Model for Point Clouds
Nov 21, 2024



Lossy compression methods rely on an autoencoder to transform a point cloud into latent points for storage, leaving the inherent redundancy of latent representations unexplored. To reduce redundancy in latent points, we propose a sparse priors guided method that achieves high reconstruction quality, especially at high compression ratios. This is accomplished by a dual-density scheme separately processing the latent points (intended for reconstruction) and the decoupled sparse priors (intended for storage). Our approach features an efficient dual-density data flow that relaxes size constraints on latent points, and hybridizes a progressive conditional diffusion model to encapsulate essential details for reconstruction within the conditions, which are decoupled hierarchically to intra-point and inter-point priors. Specifically, our method encodes the original point cloud into latent points and decoupled sparse priors through separate encoders. Latent points serve as intermediates, while sparse priors act as adaptive conditions. We then employ a progressive attention-based conditional denoiser to generate latent points conditioned on the decoupled priors, allowing the denoiser to dynamically attend to geometric and semantic cues from the priors at each encoding and decoding layer. Additionally, we integrate the local distribution into the arithmetic encoder and decoder to enhance local context modeling of the sparse points. The original point cloud is reconstructed through a point decoder. Compared to state-of-the-art, our method obtains superior rate-distortion trade-off, evidenced by extensive evaluations on the ShapeNet dataset and standard test datasets from MPEG group including 8iVFB, and Owlii.
Referring Human Pose and Mask Estimation in the Wild
Oct 27, 2024We introduce Referring Human Pose and Mask Estimation (R-HPM) in the wild, where either a text or positional prompt specifies the person of interest in an image. This new task holds significant potential for human-centric applications such as assistive robotics and sports analysis. In contrast to previous works, R-HPM (i) ensures high-quality, identity-aware results corresponding to the referred person, and (ii) simultaneously predicts human pose and mask for a comprehensive representation. To achieve this, we introduce a large-scale dataset named RefHuman, which substantially extends the MS COCO dataset with additional text and positional prompt annotations. RefHuman includes over 50,000 annotated instances in the wild, each equipped with keypoint, mask, and prompt annotations. To enable prompt-conditioned estimation, we propose the first end-to-end promptable approach named UniPHD for R-HPM. UniPHD extracts multimodal representations and employs a proposed pose-centric hierarchical decoder to process (text or positional) instance queries and keypoint queries, producing results specific to the referred person. Extensive experiments demonstrate that UniPHD produces quality results based on user-friendly prompts and achieves top-tier performance on RefHuman val and MS COCO val2017. Data and Code: https://github.com/bo-miao/RefHuman
High Frequency Matters: Uncertainty Guided Image Compression with Wavelet Diffusion
Jul 17, 2024



Diffusion probabilistic models have recently achieved remarkable success in generating high-quality images. However, balancing high perceptual quality and low distortion remains challenging in image compression applications. To address this issue, we propose an efficient Uncertainty-Guided image compression approach with wavelet Diffusion (UGDiff). Our approach focuses on high frequency compression via the wavelet transform, since high frequency components are crucial for reconstructing image details. We introduce a wavelet conditional diffusion model for high frequency prediction, followed by a residual codec that compresses and transmits prediction residuals to the decoder. This diffusion prediction-then-residual compression paradigm effectively addresses the low fidelity issue common in direct reconstructions by existing diffusion models. Considering the uncertainty from the random sampling of the diffusion model, we further design an uncertainty-weighted rate-distortion (R-D) loss tailored for residual compression, providing a more rational trade-off between rate and distortion. Comprehensive experiments on two benchmark datasets validate the effectiveness of UGDiff, surpassing state-of-the-art image compression methods in R-D performance, perceptual quality, subjective quality, and inference time. Our code is available at: https://github.com/hejiaxiang1/Wavelet-Diffusion/tree/main
Back to the Color: Learning Depth to Specific Color Transformation for Unsupervised Depth Estimation
Jun 11, 2024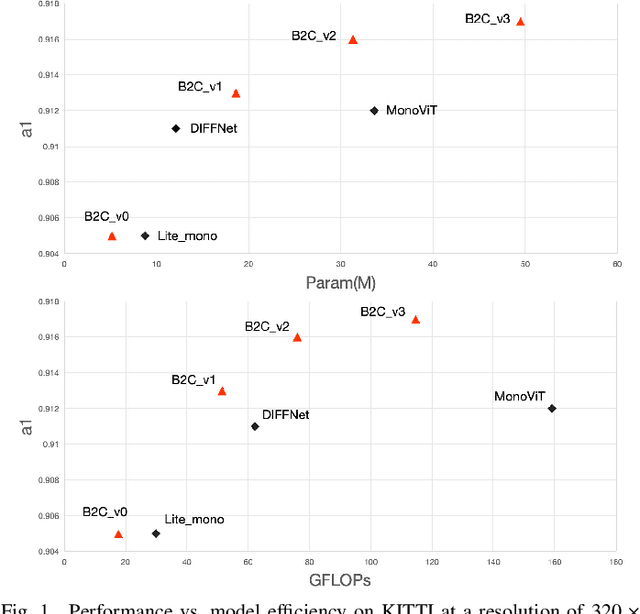



Virtual engines have the capability to generate dense depth maps for various synthetic scenes, making them invaluable for training depth estimation models. However, synthetic colors often exhibit significant discrepancies compared to real-world colors, thereby posing challenges for depth estimation in real-world scenes, particularly in complex and uncertain environments encountered in unsupervised monocular depth estimation tasks. To address this issue, we propose Back2Color, a framework that predicts realistic colors from depth utilizing a model trained on real-world data, thus facilitating the transformation of synthetic colors into real-world counterparts. Additionally, by employing the Syn-Real CutMix method for joint training with both real-world unsupervised and synthetic supervised depth samples, we achieve improved performance in monocular depth estimation for real-world scenes. Moreover, to comprehensively address the impact of non-rigid motions on depth estimation, we propose an auto-learning uncertainty temporal-spatial fusion method (Auto-UTSF), which integrates the benefits of unsupervised learning in both temporal and spatial dimensions. Furthermore, we design a depth estimation network (VADepth) based on the Vision Attention Network. Our Back2Color framework demonstrates state-of-the-art performance, as evidenced by improvements in performance metrics and the production of fine-grained details in our predictions, particularly on challenging datasets such as Cityscapes for unsupervised depth estimation.
External Knowledge Enhanced 3D Scene Generation from Sketch
Mar 21, 2024



Generating realistic 3D scenes is challenging due to the complexity of room layouts and object geometries.We propose a sketch based knowledge enhanced diffusion architecture (SEK) for generating customized, diverse, and plausible 3D scenes. SEK conditions the denoising process with a hand-drawn sketch of the target scene and cues from an object relationship knowledge base. We first construct an external knowledge base containing object relationships and then leverage knowledge enhanced graph reasoning to assist our model in understanding hand-drawn sketches. A scene is represented as a combination of 3D objects and their relationships, and then incrementally diffused to reach a Gaussian distribution.We propose a 3D denoising scene transformer that learns to reverse the diffusion process, conditioned by a hand-drawn sketch along with knowledge cues, to regressively generate the scene including the 3D object instances as well as their layout. Experiments on the 3D-FRONT dataset show that our model improves FID, CKL by 17.41%, 37.18% in 3D scene generation and FID, KID by 19.12%, 20.06% in 3D scene completion compared to the nearest competitor DiffuScene.