 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Frequency Matters: Uncertainty Guided Image Compression with Wavelet Diffusion
Jul 17, 2024



Diffusion probabilistic models have recently achieved remarkable success in generating high-quality images. However, balancing high perceptual quality and low distortion remains challenging in image compression applications. To address this issue, we propose an efficient Uncertainty-Guided image compression approach with wavelet Diffusion (UGDiff). Our approach focuses on high frequency compression via the wavelet transform, since high frequency components are crucial for reconstructing image details. We introduce a wavelet conditional diffusion model for high frequency prediction, followed by a residual codec that compresses and transmits prediction residuals to the decoder. This diffusion prediction-then-residual compression paradigm effectively addresses the low fidelity issue common in direct reconstructions by existing diffusion models. Considering the uncertainty from the random sampling of the diffusion model, we further design an uncertainty-weighted rate-distortion (R-D) loss tailored for residual compression, providing a more rational trade-off between rate and distortion. Comprehensive experiments on two benchmark datasets validate the effectiveness of UGDiff, surpassing state-of-the-art image compression methods in R-D performance, perceptual quality, subjective quality, and inference time. Our code is available at: https://github.com/hejiaxiang1/Wavelet-Diffusion/tree/main
Contrastive Semi-supervised Learning for Underwater Image Restoration via Reliable Bank
Apr 04, 2023
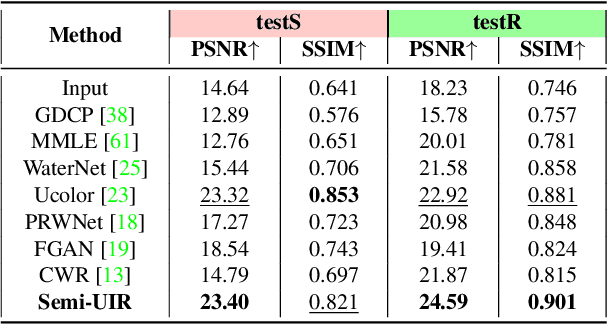

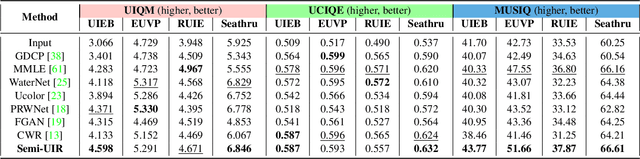
Despite the remarkable achievement of recent underwater image restoration techniques, the lack of labeled data has become a major hurdle for further progress. In this work, we propose a mean-teacher based Semi-supervised Underwater Image Restoration (Semi-UIR) framework to incorporate the unlabeled data into network training. However, the naive mean-teacher method suffers from two main problems: (1) The consistency loss used in training might become ineffective when the teacher's prediction is wrong. (2) Using L1 distance may cause the network to overfit wrong labels, resulting in confirmation bias. To address the above problems, we first introduce a reliable bank to store the "best-ever" outputs as pseudo ground truth. To assess the quality of outputs, we conduct an empirical analysis based on the monotonicity property to select the most trustworthy NR-IQA method. Besides, in view of the confirmation bias problem, we incorporate contrastive regularization to prevent the overfitting on wrong labels. Experimental results on both full-reference and non-reference underwater benchmarks demonstrate that our algorithm has obvious improvement over SOTA methods quantitatively and qualitatively. Code has been released at https://github.com/Huang-ShiRui/Semi-UIR.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022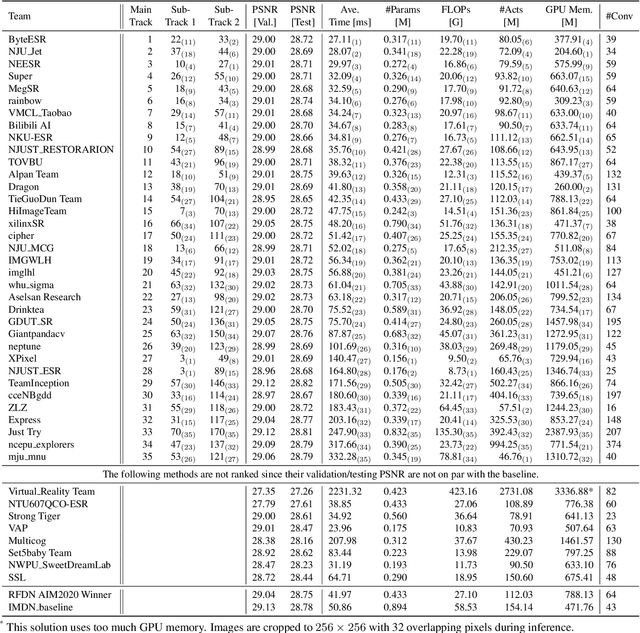
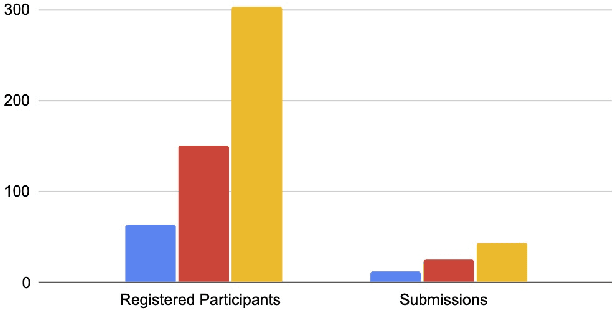
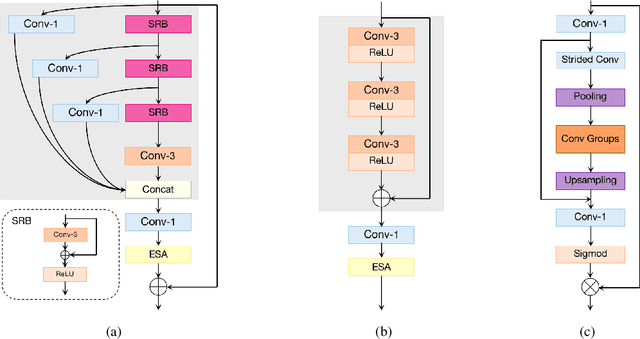
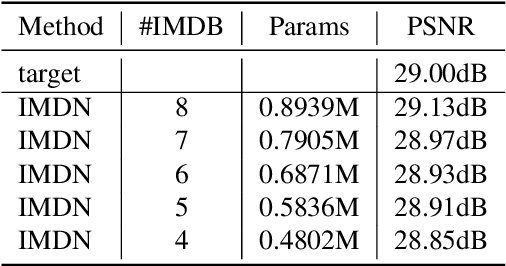
This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
DW-GAN: A Discrete Wavelet Transform GAN for NonHomogeneous Dehazing
Apr 18, 2021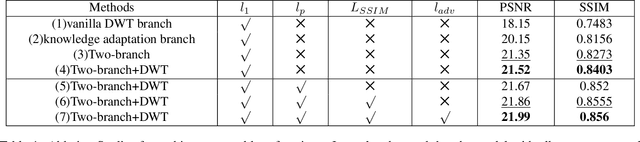
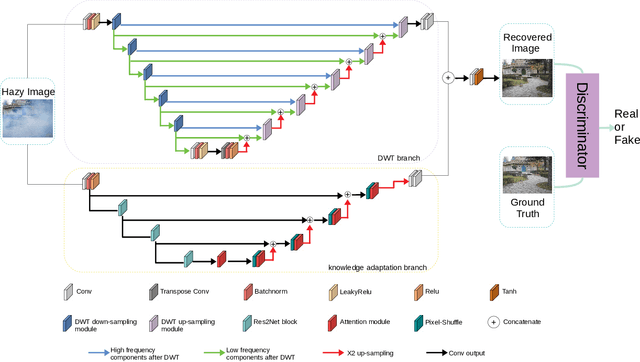


Hazy images are often subject to color distortion, blurring, and other visible quality degradation. Some existing CNN-based methods have great performance on removing homogeneous haze, but they are not robust in non-homogeneous case. The reasons are mainly in two folds. Firstly, due to the complicated haze distribution, texture details are easy to be lost during the dehazing process. Secondly, since the training pairs are hard to be collected, training on limited data can easily lead to over-fitting problem. To tackle these two issues, we introduce a novel dehazing network using 2D discrete wavelet transform, namely DW-GAN. Specifically, we propose a two-branch network to deal with the aforementioned problems. By utilizing wavelet transform in DWT branch, our proposed method can retain more high-frequency knowledge in feature maps. In order to prevent over-fitting, ImageNet pre-trained Res2Net is adopted in the knowledge adaptation branch. Owing to the robust feature representations of ImageNet pre-training, the generalization ability of our network is improved dramatically. Finally, a patch-based discriminator is used to reduce artifacts of the restored images. Extensive experimental results demonstrate that the proposed method outperforms the state-of-the-arts quantitatively and qualitatively.
A Two-branch Neural Network for Non-homogeneous Dehazing via Ensemble Learning
Apr 18, 2021
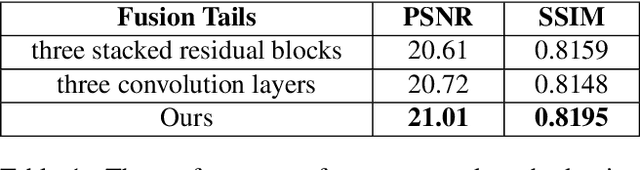
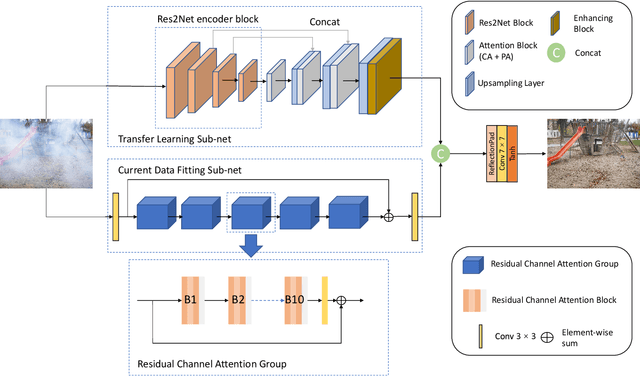
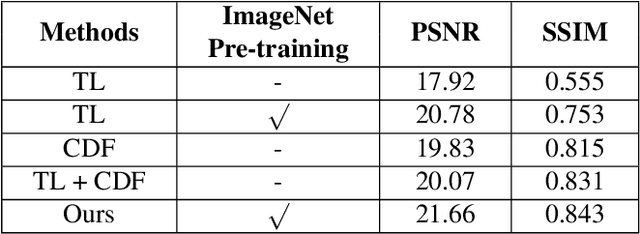
Recently, there has been rapid and significant progress on image dehazing. Many deep learning based methods have shown their superb performance in handling homogeneous dehazing problems. However, we observe that even if a carefully designed convolutional neural network (CNN) can perform well on large-scaled dehazing benchmarks, the network usually fails on the non-homogeneous dehazing datasets introduced by NTIRE challenges. The reasons are mainly in two folds. Firstly, due to its non-homogeneous nature, the non-uniformly distributed haze is harder to be removed than the homogeneous haze. Secondly, the research challenge only provides limited data (there are only 25 training pairs in NH-Haze 2021 dataset). Thus, learning the mapping from the domain of hazy images to that of clear ones based on very limited data is extremely hard. To this end, we propose a simple but effective approach for non-homogeneous dehazing via ensemble learning. To be specific, we introduce a two-branch neural network to separately deal with the aforementioned problems and then map their distinct features by a learnable fusion tail. We show extensive experimental results to illustrate the effectiveness of our proposed method.