 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Efficient Mixture-of-Experts for Remote Sensing Modality-Missing Classification
Nov 14, 2025Multimodal classification in remote sensing often suffers from missing modalities caused by environmental interference, sensor failures, or atmospheric effects, which severely degrade classification performance. Existing two-stage adaptation methods are computationally expensive and assume complete multimodal data during training, limiting their generalization to real-world incompleteness. To overcome these issues, we propose a Missing-aware Mixture-of-Loras (MaMOL) framework that reformulates modality missing as a multi-task learning problem. MaMOL introduces a dual-routing mechanism: a task-oriented dynamic router that adaptively activates experts for different missing patterns, and a modality-specific-shared static router that maintains stable cross-modal knowledge sharing. Unlike prior methods that train separate networks for each missing configuration, MaMOL achieves parameter-efficient adaptation via lightweight expert updates and shared expert reuse. Experiments on multiple remote sensing benchmarks demonstrate superior robustness and generalization under varying missing rates, with minimal computational overhead. Moreover, transfer experiments on natural image datasets validate its scalability and cross-domain applicability, highlighting MaMOL as a general and efficient solution for incomplete multimodal learning.
Hyperspectral Mamba for Hyperspectral Object Tracking
Sep 10, 2025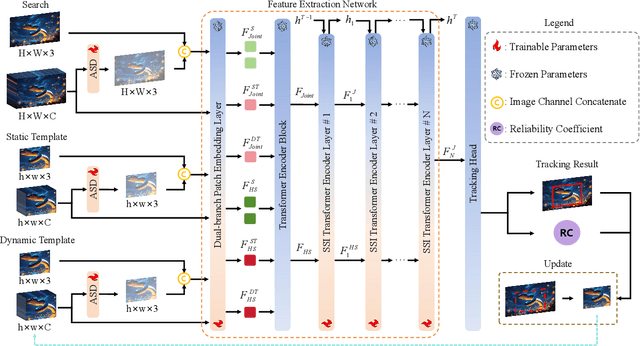
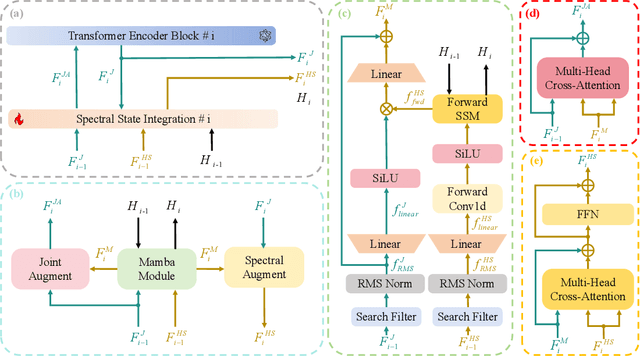
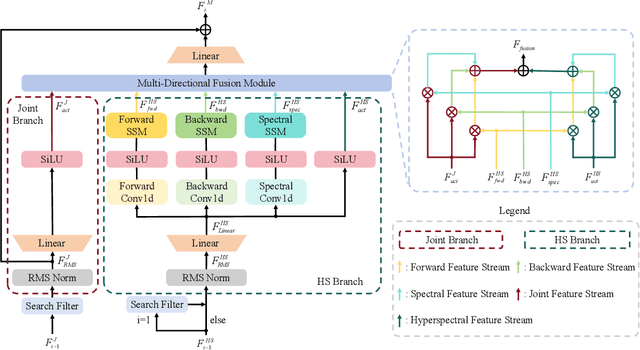
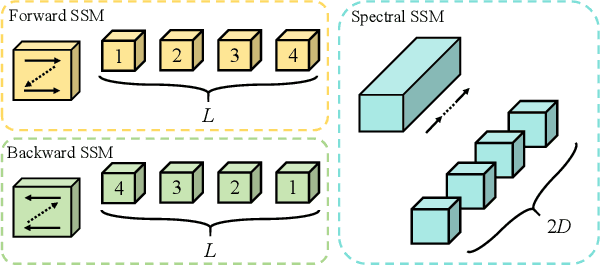
Hyperspectral object tracking holds great promise due to the rich spectral information and fine-grained material distinctions in hyperspectral images, which are beneficial in challenging scenarios. While existing hyperspectral trackers have made progress by either transforming hyperspectral data into false-color images or incorporating modality fusion strategies, they often fail to capture the intrinsic spectral information, temporal dependencies, and cross-depth interactions. To address these limitations, a new hyperspectral object tracking network equipped with Mamba (HyMamba), is proposed. It unifies spectral, cross-depth, and temporal modeling through state space modules (SSMs). The core of HyMamba lies in the Spectral State Integration (SSI) module, which enables progressive refinement and propagation of spectral features with cross-depth and temporal spectral information. Embedded within each SSI, the Hyperspectral Mamba (HSM) module is introduced to learn spatial and spectral information synchronously via three directional scanning SSMs. Based on SSI and HSM, HyMamba constructs joint features from false-color and hyperspectral inputs, and enhances them through interaction with original spectral features extracted from raw hyperspectral images. Extensive experiments conducted on seven benchmark datasets demonstrate that HyMamba achieves state-of-the-art performance. For instance, it achieves 73.0\% of the AUC score and 96.3\% of the DP@20 score on the HOTC2020 dataset. The code will be released at https://github.com/lgao001/HyMamba.
Hyperspectral Adapter for Object Tracking based on Hyperspectral Video
Mar 28, 2025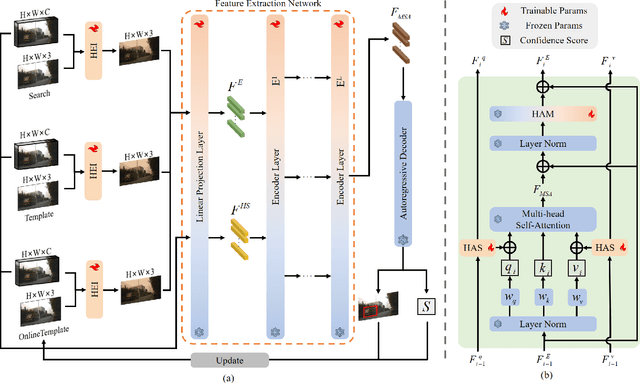
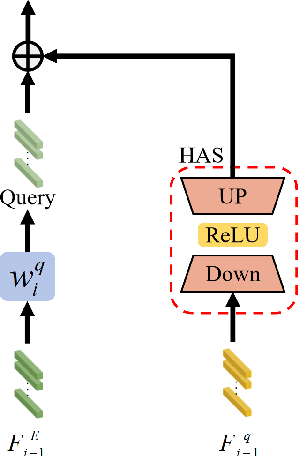
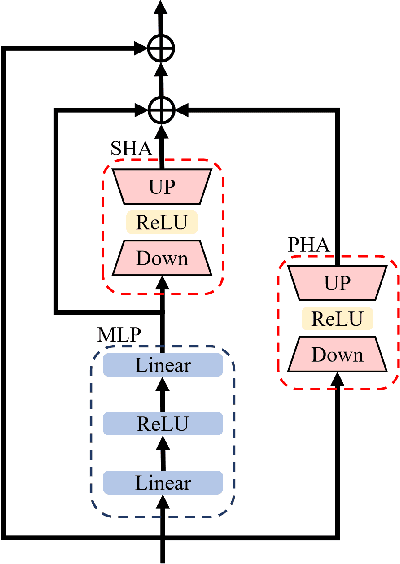
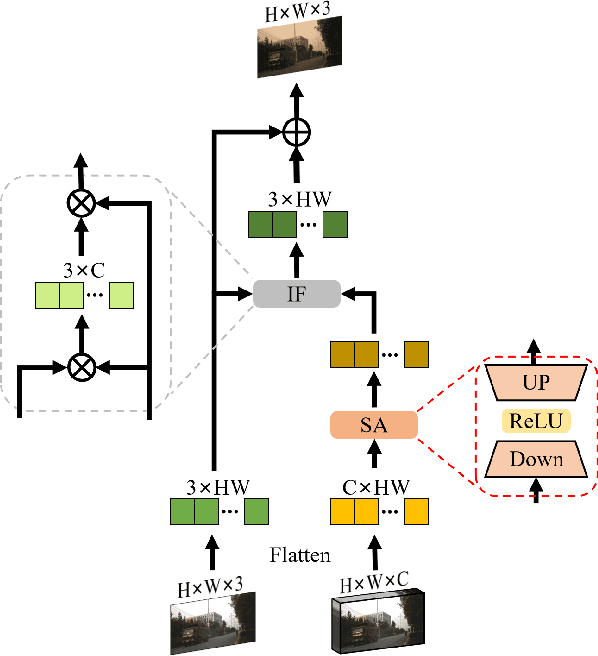
Object tracking based on hyperspectral video attracts increasing attention to the rich material and motion information in the hyperspectral videos. The prevailing hyperspectral methods adapt pretrained RGB-based object tracking networks for hyperspectral tasks by fine-tuning the entire network on hyperspectral datasets, which achieves impressive results in challenging scenarios. However, the performance of hyperspectral trackers is limited by the loss of spectral information during the transformation, and fine-tuning the entire pretrained network is inefficient for practical applications. To address the issues, a new hyperspectral object tracking method, hyperspectral adapter for tracking (HyA-T), is proposed in this work. The hyperspectral adapter for the self-attention (HAS) and the hyperspectral adapter for the multilayer perceptron (HAM) are proposed to generate the adaption information and to transfer the multi-head self-attention (MSA) module and the multilayer perceptron (MLP) in pretrained network for the hyperspectral object tracking task by augmenting the adaption information into the calculation of the MSA and MLP. Additionally, the hyperspectral enhancement of input (HEI) is proposed to augment the original spectral information into the input of the tracking network. The proposed methods extract spectral information directly from the hyperspectral images, which prevent the loss of the spectral information. Moreover, only the parameters in the proposed methods are fine-tuned, which is more efficient than the existing methods. Extensive experiments were conducted on four datasets with various spectral bands, verifing the effectiveness of the proposed methods. The HyA-T achieves state-of-the-art performance on all the datasets.
M$^3$amba: CLIP-driven Mamba Model for Multi-modal Remote Sensing Classification
Mar 09, 2025Multi-modal fusion holds great promise for integrating information from different modalities. However, due to a lack of consideration for modal consistency, existing multi-modal fusion methods in the field of remote sensing still face challenges of incomplete semantic information and low computational efficiency in their fusion designs. Inspired by the observation that the visual language pre-training model CLIP can effectively extract strong semantic information from visual features, we propose M$^3$amba, a novel end-to-end CLIP-driven Mamba model for multi-modal fusion to address these challenges. Specifically, we introduce CLIP-driven modality-specific adapters in the fusion architecture to avoid the bias of understanding specific domains caused by direct inference, making the original CLIP encoder modality-specific perception. This unified framework enables minimal training to achieve a comprehensive semantic understanding of different modalities, thereby guiding cross-modal feature fusion. To further enhance the consistent association between modality mappings, a multi-modal Mamba fusion architecture with linear complexity and a cross-attention module Cross-SS2D are designed, which fully considers effective and efficient information interaction to achieve complete fusion. Extensive experiments have shown that M$^3$amba has an average performance improvement of at least 5.98\% compared with the state-of-the-art methods in multi-modal hyperspectral image classification tasks in the remote sensing field, while also demonstrating excellent training efficiency, achieving a double improvement in accuracy and efficiency. The code is released at https://github.com/kaka-Cao/M3amba.
DiffCLIP: Few-shot Language-driven Multimodal Classifier
Dec 10, 2024



Visual language models like Contrastive Language-Image Pretraining (CLIP) have shown impressive performance in analyzing natural images with language information. However, these models often encounter challenges when applied to specialized domains such as remote sensing due to the limited availability of image-text pairs for training. To tackle this issue, we introduce DiffCLIP, a novel framework that extends CLIP to effectively convey comprehensive language-driven semantic information for accurate classification of high-dimensional multimodal remote sensing images. DiffCLIP is a few-shot learning method that leverages unlabeled images for pretraining. It employs unsupervised mask diffusion learning to capture the distribution of diverse modalities without requiring labels. The modality-shared image encoder maps multimodal data into a unified subspace, extracting shared features with consistent parameters across modalities. A well-trained image encoder further enhances learning by aligning visual representations with class-label text information from CLIP. By integrating these approaches, DiffCLIP significantly boosts CLIP performance using a minimal number of image-text pairs. We evaluate DiffCLIP on widely used high-dimensional multimodal datasets, demonstrating its effectiveness in addressing few-shot annotated classification tasks. DiffCLIP achieves an overall accuracy improvement of 10.65% across three remote sensing datasets compared with CLIP, while utilizing only 2-shot image-text pairs. The code has been released at https://github.com/icey-zhang/DiffCLIP.
Towards Accurate and Efficient Sub-8-Bit Integer Training
Nov 17, 2024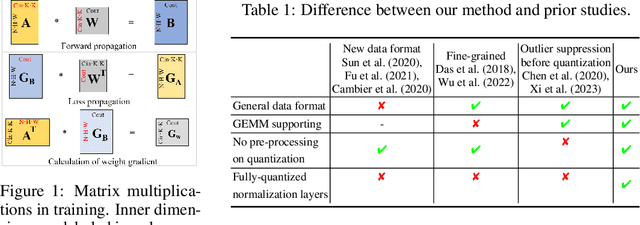
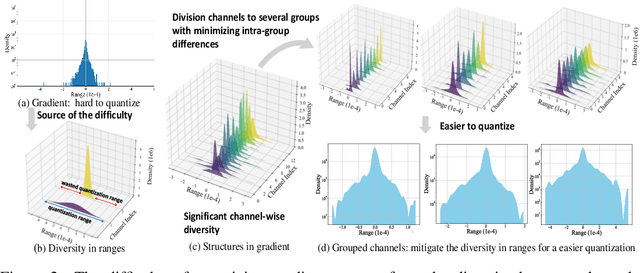
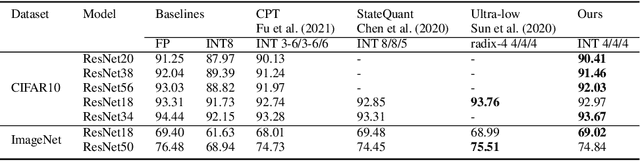
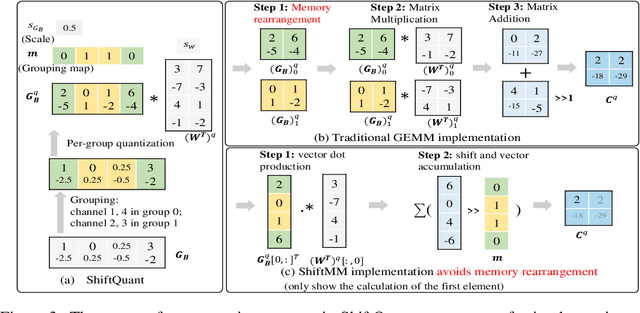
Neural network training is a memory- and compute-intensive task. Quantization, which enables low-bitwidth formats in training, can significantly mitigate the workload. To reduce quantization error, recent methods have developed new data formats and additional pre-processing operations on quantizers. However, it remains quite challenging to achieve high accuracy and efficiency simultaneously. In this paper, we explore sub-8-bit integer training from its essence of gradient descent optimization. Our integer training framework includes two components: ShiftQuant to realize accurate gradient estimation, and L1 normalization to smoothen the loss landscape. ShiftQuant attains performance that approaches the theoretical upper bound of group quantization. Furthermore, it liberates group quantization from inefficient memory rearrangement. The L1 normalization facilitates the implementation of fully quantized normalization layers with impressive convergence accuracy. Our method frees sub-8-bit integer training from pre-processing and supports general devices. This framework achieves negligible accuracy loss across various neural networks and tasks ($0.92\%$ on 4-bit ResNets, $0.61\%$ on 6-bit Transformers). The prototypical implementation of ShiftQuant achieves more than $1.85\times/15.3\%$ performance improvement on CPU/GPU compared to its FP16 counterparts, and $33.9\%$ resource consumption reduction on FPGA than the FP16 counterparts. The proposed fully-quantized L1 normalization layers achieve more than $35.54\%$ improvement in throughout on CPU compared to traditional L2 normalization layers. Moreover, theoretical analysis verifies the advancement of our method.
Beyond Feature Mapping GAP: Integrating Real HDRTV Priors for Superior SDRTV-to-HDRTV Conversion
Nov 16, 2024



The rise of HDR-WCG display devices has highlighted the need to convert SDRTV to HDRTV, as most video sources are still in SDR. Existing methods primarily focus on designing neural networks to learn a single-style mapping from SDRTV to HDRTV. However, the limited information in SDRTV and the diversity of styles in real-world conversions render this process an ill-posed problem, thereby constraining the performance and generalization of these methods. Inspired by generative approaches, we propose a novel method for SDRTV to HDRTV conversion guided by real HDRTV priors. Despite the limited information in SDRTV, introducing real HDRTV as reference priors significantly constrains the solution space of the originally high-dimensional ill-posed problem. This shift transforms the task from solving an unreferenced prediction problem to making a referenced selection, thereby markedly enhancing the accuracy and reliability of the conversion process. Specifically, our approach comprises two stages: the first stage employs a Vector Quantized Generative Adversarial Network to capture HDRTV priors, while the second stage matches these priors to the input SDRTV content to recover realistic HDRTV outputs. We evaluate our method on public datasets, demonstrating its effectiveness with significant improvements in both objective and subjective metrics across real and synthetic datasets.
An End-to-End Real-World Camera Imaging Pipeline
Nov 16, 2024



Recent advances in neural camera imaging pipelines have demonstrated notable progress. Nevertheless, the real-world imaging pipeline still faces challenges including the lack of joint optimization in system components, computational redundancies, and optical distortions such as lens shading.In light of this, we propose an end-to-end camera imaging pipeline (RealCamNet) to enhance real-world camera imaging performance. Our methodology diverges from conventional, fragmented multi-stage image signal processing towards end-to-end architecture. This architecture facilitates joint optimization across the full pipeline and the restoration of coordinate-biased distortions. RealCamNet is designed for high-quality conversion from RAW to RGB and compact image compression. Specifically, we deeply analyze coordinate-dependent optical distortions, e.g., vignetting and dark shading, and design a novel Coordinate-Aware Distortion Restoration (CADR) module to restore coordinate-biased distortions. Furthermore, we propose a Coordinate-Independent Mapping Compression (CIMC) module to implement tone mapping and redundant information compression. Existing datasets suffer from misalignment and overly idealized conditions, making them inadequate for training real-world imaging pipelines. Therefore, we collected a real-world imaging dataset. Experiment results show that RealCamNet achieves the best rate-distortion performance with lower inference latency.
SeaDATE: Remedy Dual-Attention Transformer with Semantic Alignment via Contrast Learning for Multimodal Object Detection
Oct 15, 2024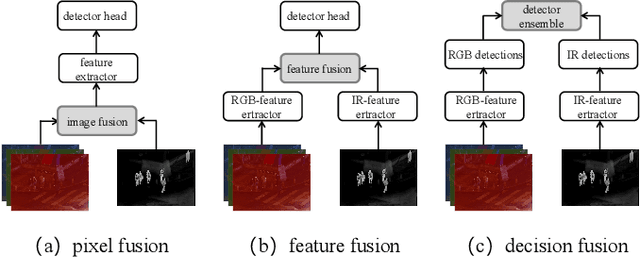
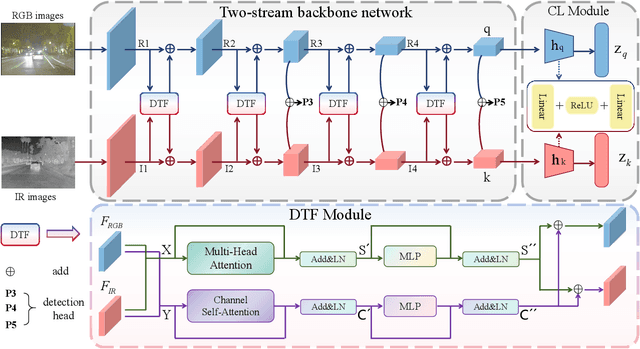
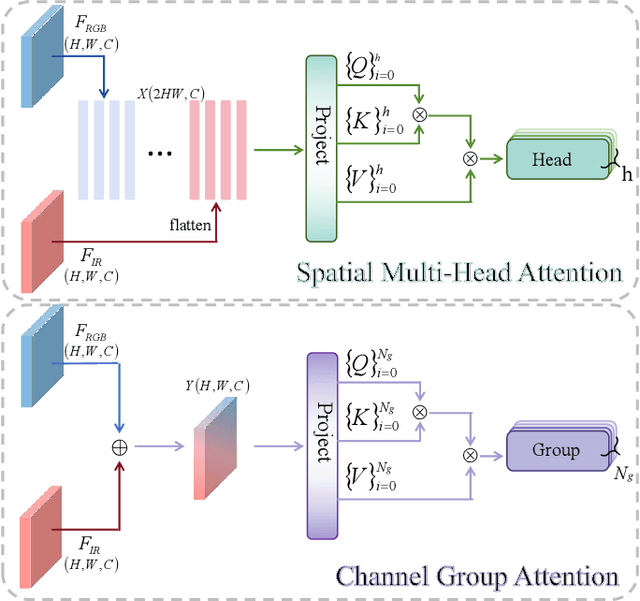
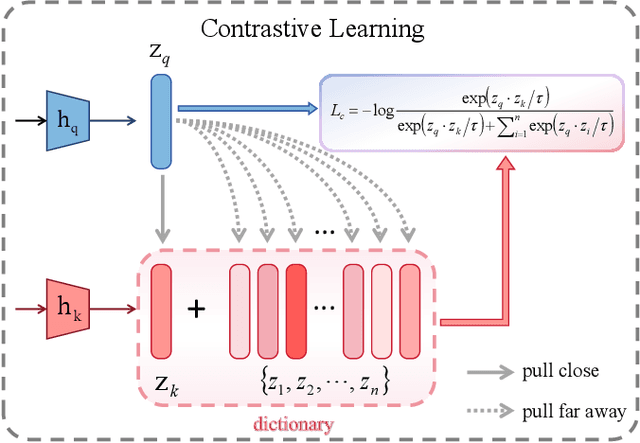
Multimodal object detection leverages diverse modal information to enhance the accuracy and robustness of detectors. By learning long-term dependencies, Transformer can effectively integrate multimodal features in the feature extraction stage, which greatly improves the performance of multimodal object detection. However, current methods merely stack Transformer-guided fusion techniques without exploring their capability to extract features at various depth layers of network, thus limiting the improvements in detection performance. In this paper, we introduce an accurate and efficient object detection method named SeaDATE. Initially, we propose a novel dual attention Feature Fusion (DTF) module that, under Transformer's guidance, integrates local and global information through a dual attention mechanism, strengthening the fusion of modal features from orthogonal perspectives using spatial and channel tokens. Meanwhile, our theoretical analysis and empirical validation demonstrate that the Transformer-guided fusion method, treating images as sequences of pixels for fusion, performs better on shallow features' detail information compared to deep semantic information. To address this, we designed a contrastive learning (CL) module aimed at learning features of multimodal samples, remedying the shortcomings of Transformer-guided fusion in extracting deep semantic features, and effectively utilizing cross-modal information. Extensive experiments and ablation studies on the FLIR, LLVIP, and M3FD datasets have proven our method to be effective, achieving state-of-the-art detection performance.
AMPO: Automatic Multi-Branched Prompt Optimization
Oct 11, 2024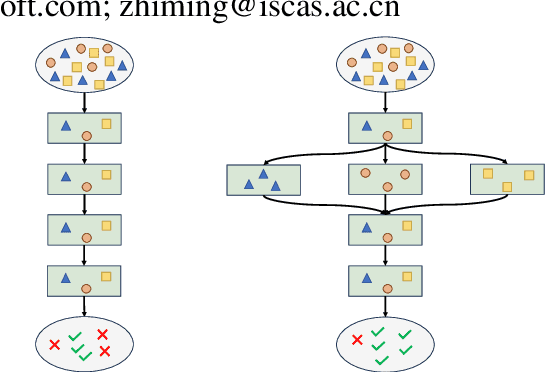
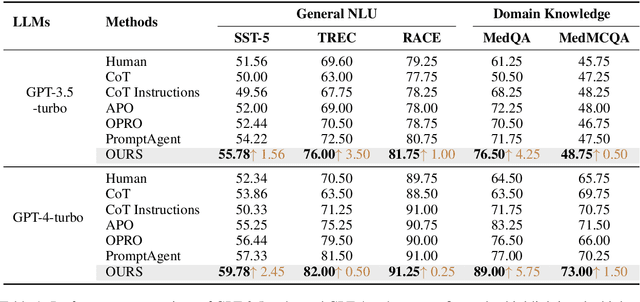
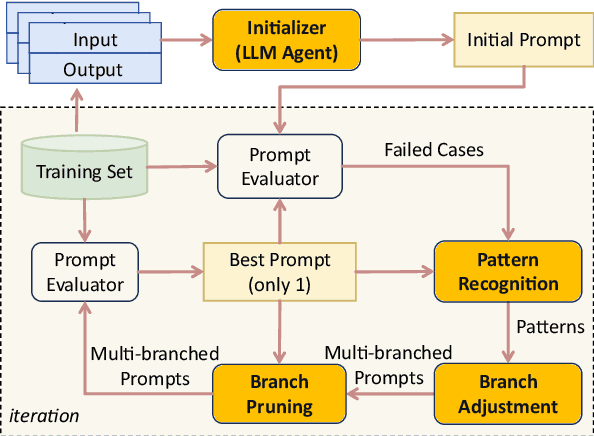
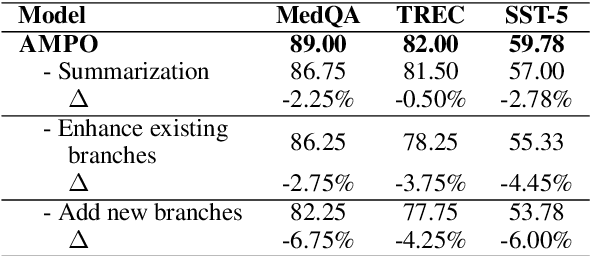
Prompt engineering is very important to enhance the performance of large language models (LLMs). When dealing with complex issues, prompt engineers tend to distill multiple patterns from examples and inject relevant solutions to optimize the prompts, achieving satisfying results. However, existing automatic prompt optimization techniques are only limited to producing single flow instructions, struggling with handling diverse patterns. In this paper, we present AMPO, an automatic prompt optimization method that can iteratively develop a multi-branched prompt using failure cases as feedback. Our goal is to explore a novel way of structuring prompts with multi-branches to better handle multiple patterns in complex tasks, for which we introduce three modules: Pattern Recognition, Branch Adjustment, and Branch Pruning. In experiments across five tasks, AMPO consistently achieves the best results. Additionally, our approach demonstrates significant optimization efficiency due to our adoption of a minimal search strategy.