 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL3TC: Leveraging RWKV for Learned Lossless Low-Complexity Text Compression
Dec 24, 2024
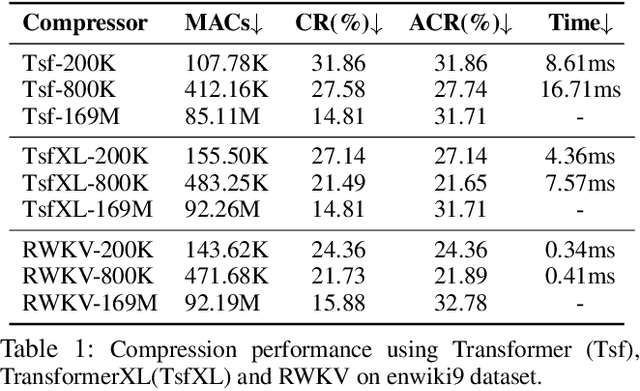


Learning-based probabilistic models can be combined with an entropy coder for data compression. However, due to the high complexity of learning-based models, their practical application as text compressors has been largely overlooked. To address this issue, our work focuses on a low-complexity design while maintaining compression performance. We introduce a novel Learned Lossless Low-complexity Text Compression method (L3TC). Specifically, we conduct extensive experiments demonstrating that RWKV models achieve the fastest decoding speed with a moderate compression ratio, making it the most suitable backbone for our method. Second, we propose an outlier-aware tokenizer that uses a limited vocabulary to cover frequent tokens while allowing outliers to bypass the prediction and encoding. Third, we propose a novel high-rank reparameterization strategy that enhances the learning capability during training without increasing complexity during inference. Experimental results validate that our method achieves 48% bit saving compared to gzip compressor. Besides, L3TC offers compression performance comparable to other learned compressors, with a 50x reduction in model parameters. More importantly, L3TC is the fastest among all learned compressors, providing real-time decoding speeds up to megabytes per second. Our code is available at https://github.com/alipay/L3TC-leveraging-rwkv-for-learned-lossless-low-complexity-text-compression.git.
Beyond Feature Mapping GAP: Integrating Real HDRTV Priors for Superior SDRTV-to-HDRTV Conversion
Nov 16, 2024



The rise of HDR-WCG display devices has highlighted the need to convert SDRTV to HDRTV, as most video sources are still in SDR. Existing methods primarily focus on designing neural networks to learn a single-style mapping from SDRTV to HDRTV. However, the limited information in SDRTV and the diversity of styles in real-world conversions render this process an ill-posed problem, thereby constraining the performance and generalization of these methods. Inspired by generative approaches, we propose a novel method for SDRTV to HDRTV conversion guided by real HDRTV priors. Despite the limited information in SDRTV, introducing real HDRTV as reference priors significantly constrains the solution space of the originally high-dimensional ill-posed problem. This shift transforms the task from solving an unreferenced prediction problem to making a referenced selection, thereby markedly enhancing the accuracy and reliability of the conversion process. Specifically, our approach comprises two stages: the first stage employs a Vector Quantized Generative Adversarial Network to capture HDRTV priors, while the second stage matches these priors to the input SDRTV content to recover realistic HDRTV outputs. We evaluate our method on public datasets, demonstrating its effectiveness with significant improvements in both objective and subjective metrics across real and synthetic datasets.
CNN-MERP: An FPGA-Based Memory-Efficient Reconfigurable Processor for Forward and Backward Propagation of Convolutional Neural Networks
Mar 22, 2017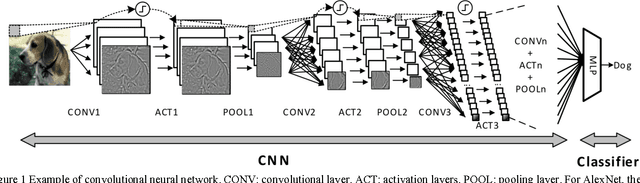
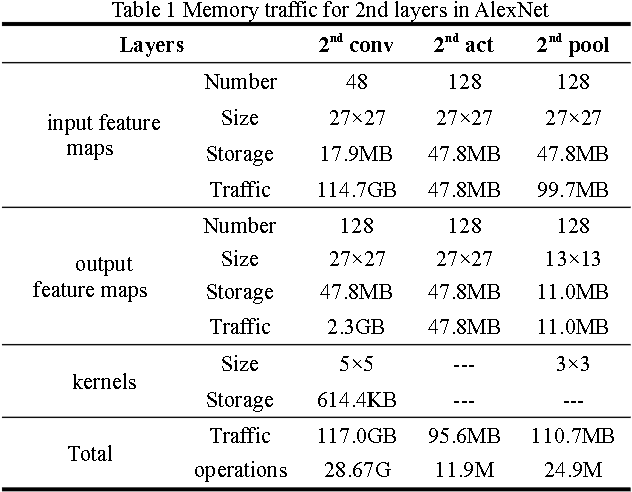
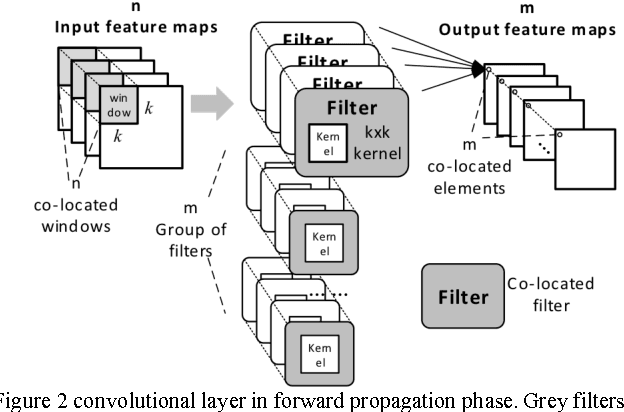
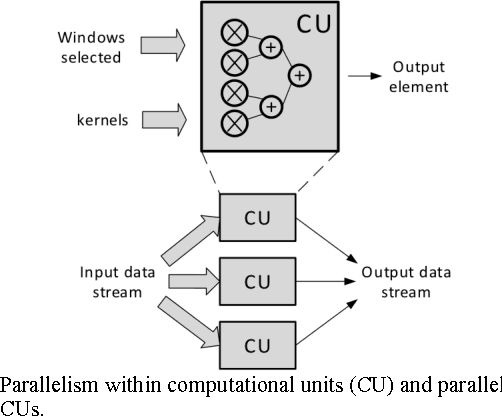
Large-scale deep convolutional neural networks (CNNs) are widely used in machine learning applications. While CNNs involve huge complexity, VLSI (ASIC and FPGA) chips that deliver high-density integration of computational resources are regarded as a promising platform for CNN's implementation. At massive parallelism of computational units, however, the external memory bandwidth, which is constrained by the pin count of the VLSI chip, becomes the system bottleneck. Moreover, VLSI solutions are usually regarded as a lack of the flexibility to be reconfigured for the various parameters of CNNs. This paper presents CNN-MERP to address these issues. CNN-MERP incorporates an efficient memory hierarchy that significantly reduces the bandwidth requirements from multiple optimizations including on/off-chip data allocation, data flow optimization and data reuse. The proposed 2-level reconfigurability is utilized to enable fast and efficient reconfiguration, which is based on the control logic and the multiboot feature of FPGA. As a result, an external memory bandwidth requirement of 1.94MB/GFlop is achieved, which is 55% lower than prior arts. Under limited DRAM bandwidth, a system throughput of 1244GFlop/s is achieved at the Vertex UltraScale platform, which is 5.48 times higher than the state-of-the-art FPGA implementations.
Chain-NN: An Energy-Efficient 1D Chain Architecture for Accelerating Deep Convolutional Neural Networks
Mar 04, 2017
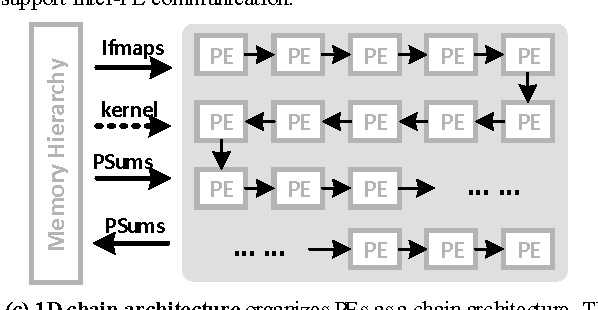
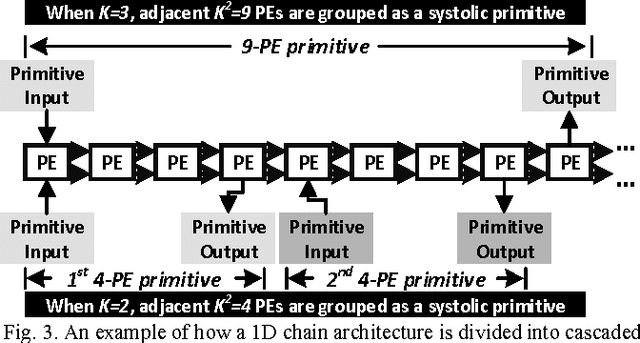
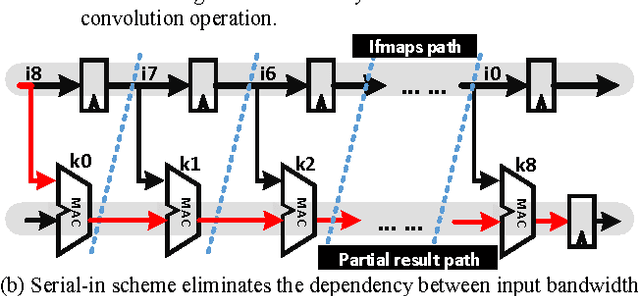
Deep convolutional neural networks (CNN) have shown their good performances in many computer vision tasks. However, the high computational complexity of CNN involves a huge amount of data movements between the computational processor core and memory hierarchy which occupies the major of the power consumption. This paper presents Chain-NN, a novel energy-efficient 1D chain architecture for accelerating deep CNNs. Chain-NN consists of the dedicated dual-channel process engines (PE). In Chain-NN, convolutions are done by the 1D systolic primitives composed of a group of adjacent PEs. These systolic primitives, together with the proposed column-wise scan input pattern, can fully reuse input operand to reduce the memory bandwidth requirement for energy saving. Moreover, the 1D chain architecture allows the systolic primitives to be easily reconfigured according to specific CNN parameters with fewer design complexity. The synthesis and layout of Chain-NN is under TSMC 28nm process. It costs 3751k logic gates and 352KB on-chip memory. The results show a 576-PE Chain-NN can be scaled up to 700MHz. This achieves a peak throughput of 806.4GOPS with 567.5mW and is able to accelerate the five convolutional layers in AlexNet at a frame rate of 326.2fps. 1421.0GOPS/W power efficiency is at least 2.5 to 4.1x times better than the state-of-the-art works.