 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLine as object: datasets and framework for semantic line segment detection
Sep 14, 2019

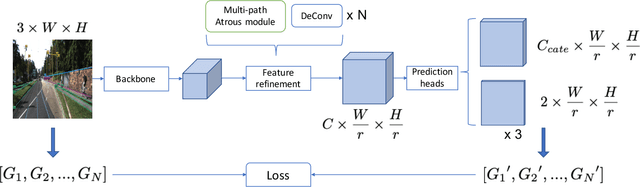
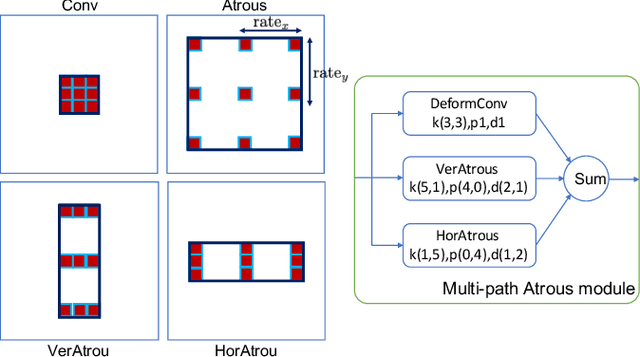
In this work, we propose a learning-based approach to the task of detecting semantic line segments from outdoor scenes. Semantic line segments are salient edges enclosed by two endpoints on an image with apparent semantic information, e.g., the boundary between a building roof and the sky (See Fig. 1). Semantic line segments can be efficiently parameterized and fill the gap between dense feature points and sparse objects to act as an effective landmarks in applications such as large-scale High Definition Mapping (HDM). With no existing benchmarks, we have built two new datasets carefully labeled by humans that contain over 6,000 images of semantic line segments. Semantic line segments have different appearance and layout patterns that are challenging for existing object detectors. We have proposed a Semantic Line Segment Detector (SLSD) together with an unified representation and a modified evaluation metric to better detect semantic line segments. SLSD trained on our proposed datasets is shown to perform effectively and efficiently. We have conducted excessive experiments to demonstrate semantic line segment detection task as a valid and challenging research topic.
CNN-MERP: An FPGA-Based Memory-Efficient Reconfigurable Processor for Forward and Backward Propagation of Convolutional Neural Networks
Mar 22, 2017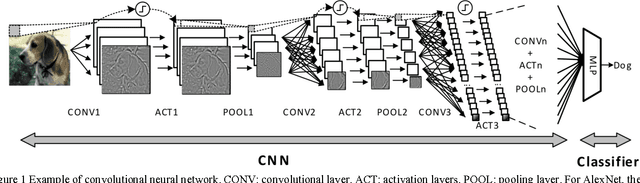
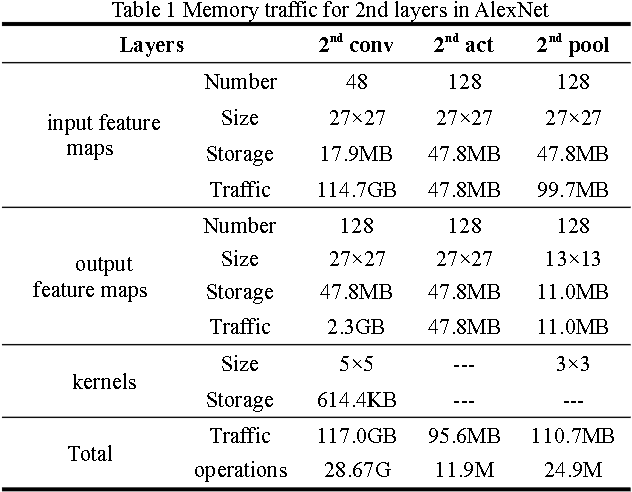
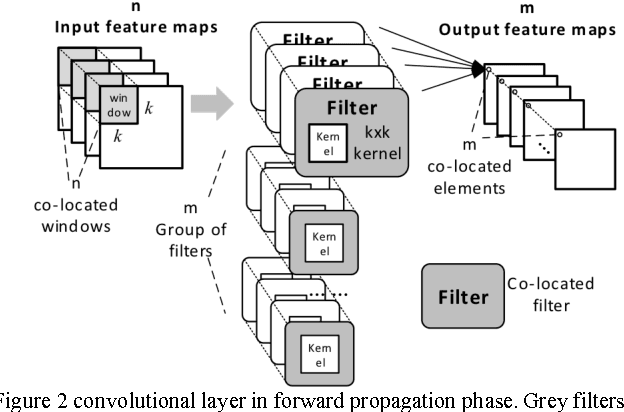
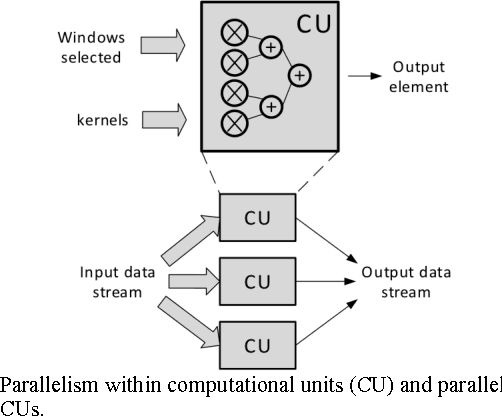
Large-scale deep convolutional neural networks (CNNs) are widely used in machine learning applications. While CNNs involve huge complexity, VLSI (ASIC and FPGA) chips that deliver high-density integration of computational resources are regarded as a promising platform for CNN's implementation. At massive parallelism of computational units, however, the external memory bandwidth, which is constrained by the pin count of the VLSI chip, becomes the system bottleneck. Moreover, VLSI solutions are usually regarded as a lack of the flexibility to be reconfigured for the various parameters of CNNs. This paper presents CNN-MERP to address these issues. CNN-MERP incorporates an efficient memory hierarchy that significantly reduces the bandwidth requirements from multiple optimizations including on/off-chip data allocation, data flow optimization and data reuse. The proposed 2-level reconfigurability is utilized to enable fast and efficient reconfiguration, which is based on the control logic and the multiboot feature of FPGA. As a result, an external memory bandwidth requirement of 1.94MB/GFlop is achieved, which is 55% lower than prior arts. Under limited DRAM bandwidth, a system throughput of 1244GFlop/s is achieved at the Vertex UltraScale platform, which is 5.48 times higher than the state-of-the-art FPGA implementations.
Chain-NN: An Energy-Efficient 1D Chain Architecture for Accelerating Deep Convolutional Neural Networks
Mar 04, 2017
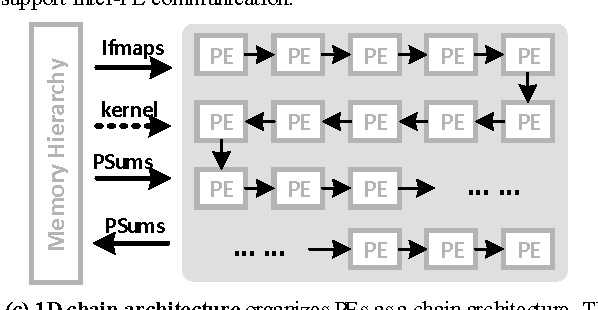
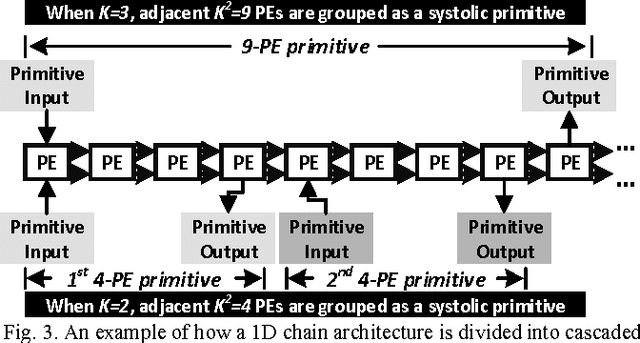
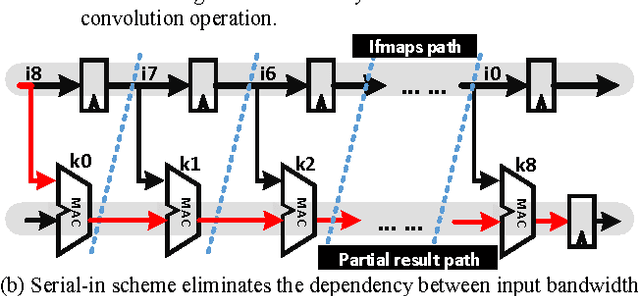
Deep convolutional neural networks (CNN) have shown their good performances in many computer vision tasks. However, the high computational complexity of CNN involves a huge amount of data movements between the computational processor core and memory hierarchy which occupies the major of the power consumption. This paper presents Chain-NN, a novel energy-efficient 1D chain architecture for accelerating deep CNNs. Chain-NN consists of the dedicated dual-channel process engines (PE). In Chain-NN, convolutions are done by the 1D systolic primitives composed of a group of adjacent PEs. These systolic primitives, together with the proposed column-wise scan input pattern, can fully reuse input operand to reduce the memory bandwidth requirement for energy saving. Moreover, the 1D chain architecture allows the systolic primitives to be easily reconfigured according to specific CNN parameters with fewer design complexity. The synthesis and layout of Chain-NN is under TSMC 28nm process. It costs 3751k logic gates and 352KB on-chip memory. The results show a 576-PE Chain-NN can be scaled up to 700MHz. This achieves a peak throughput of 806.4GOPS with 567.5mW and is able to accelerate the five convolutional layers in AlexNet at a frame rate of 326.2fps. 1421.0GOPS/W power efficiency is at least 2.5 to 4.1x times better than the state-of-the-art works.