 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multimodal Lifelong Understanding: A Dataset and Agentic Baseline
Mar 05, 2026While datasets for video understanding have scaled to hour-long durations, they typically consist of densely concatenated clips that differ from natural, unscripted daily life. To bridge this gap, we introduce MM-Lifelong, a dataset designed for Multimodal Lifelong Understanding. Comprising 181.1 hours of footage, it is structured across Day, Week, and Month scales to capture varying temporal densities. Extensive evaluations reveal two critical failure modes in current paradigms: end-to-end MLLMs suffer from a Working Memory Bottleneck due to context saturation, while representative agentic baselines experience Global Localization Collapse when navigating sparse, month-long timelines. To address this, we propose the Recursive Multimodal Agent (ReMA), which employs dynamic memory management to iteratively update a recursive belief state, significantly outperforming existing methods. Finally, we establish dataset splits designed to isolate temporal and domain biases, providing a rigorous foundation for future research in supervised learning and out-of-distribution generalization.
PhyCritic: Multimodal Critic Models for Physical AI
Feb 11, 2026With the rapid development of large multimodal models, reliable judge and critic models have become essential for open-ended evaluation and preference alignment, providing pairwise preferences, numerical scores, and explanatory justifications for assessing model-generated responses. However, existing critics are primarily trained in general visual domains such as captioning or image question answering, leaving physical AI tasks involving perception, causal reasoning, and planning largely underexplored. We introduce PhyCritic, a multimodal critic model optimized for physical AI through a two-stage RLVR pipeline: a physical skill warmup stage that enhances physically oriented perception and reasoning, followed by self-referential critic finetuning, where the critic generates its own prediction as an internal reference before judging candidate responses, improving judgment stability and physical correctness. Across both physical and general-purpose multimodal judge benchmarks, PhyCritic achieves strong performance gains over open-source baselines and, when applied as a policy model, further improves perception and reasoning in physically grounded tasks.
Learning Heat-based Equations in Self-similar variables
Feb 03, 2026We study solution learning for heat-based equations in self-similar variables (SSV). We develop an SSV training framework compatible with standard neural-operator training. We instantiate this framework on the two-dimensional incompressible Navier-Stokes equations and the one-dimensional viscous Burgers equation, and perform controlled comparisons between models trained in physical coordinates and in the corresponding self-similar coordinates using two simple fully connected architectures (standard multilayer perceptrons and a factorized fully connected network). Across both systems and both architectures, SSV-trained networks consistently deliver substantially more accurate and stable extrapolation beyond the training window and better capture qualitative long-time trends. These results suggest that self-similar coordinates provide a mathematically motivated inductive bias for learning the long-time dynamics of heat-based equations.
ProphetKV: User-Query-Driven Selective Recomputation for Efficient KV Cache Reuse in Retrieval-Augmented Generation
Jan 31, 2026The prefill stage of long-context Retrieval-Augmented Generation (RAG) is severely bottlenecked by computational overhead. To mitigate this, recent methods assemble pre-calculated KV caches of retrieved RAG documents (by a user query) and reprocess selected tokens to recover cross-attention between these pre-calculated KV caches. However, we identify a fundamental "crowding-out effect" in current token selection criteria: globally salient but user-query-irrelevant tokens saturate the limited recomputation budget, displacing the tokens truly essential for answering the user query and degrading inference accuracy. We propose ProphetKV, a user-query-driven KV Cache reuse method for RAG scenarios. ProphetKV dynamically prioritizes tokens based on their semantic relevance to the user query and employs a dual-stage recomputation pipeline to fuse layer-wise attention metrics into a high-utility set. By ensuring the recomputation budget is dedicated to bridging the informational gap between retrieved context and the user query, ProphetKV achieves high-fidelity attention recovery with minimal overhead. Our extensive evaluation results show that ProphetKV retains 96%-101% of full-prefill accuracy with only a 20% recomputation ratio, while achieving accuracy improvements of 8.8%-24.9% on RULER and 18.6%-50.9% on LongBench over the state-of-the-art approaches (e.g., CacheBlend, EPIC, and KVShare).
DP$^2$O-SR: Direct Perceptual Preference Optimization for Real-World Image Super-Resolution
Oct 21, 2025Benefiting from pre-trained text-to-image (T2I) diffusion models, real-world image super-resolution (Real-ISR) methods can synthesize rich and realistic details. However, due to the inherent stochasticity of T2I models, different noise inputs often lead to outputs with varying perceptual quality. Although this randomness is sometimes seen as a limitation, it also introduces a wider perceptual quality range, which can be exploited to improve Real-ISR performance. To this end, we introduce Direct Perceptual Preference Optimization for Real-ISR (DP$^2$O-SR), a framework that aligns generative models with perceptual preferences without requiring costly human annotations. We construct a hybrid reward signal by combining full-reference and no-reference image quality assessment (IQA) models trained on large-scale human preference datasets. This reward encourages both structural fidelity and natural appearance. To better utilize perceptual diversity, we move beyond the standard best-vs-worst selection and construct multiple preference pairs from outputs of the same model. Our analysis reveals that the optimal selection ratio depends on model capacity: smaller models benefit from broader coverage, while larger models respond better to stronger contrast in supervision. Furthermore, we propose hierarchical preference optimization, which adaptively weights training pairs based on intra-group reward gaps and inter-group diversity, enabling more efficient and stable learning. Extensive experiments across both diffusion- and flow-based T2I backbones demonstrate that DP$^2$O-SR significantly improves perceptual quality and generalizes well to real-world benchmarks.
VideoITG: Multimodal Video Understanding with Instructed Temporal Grounding
Jul 17, 2025Recent studies have revealed that selecting informative and relevant video frames can significantly improve the performance of Video Large Language Models (Video-LLMs). Current methods, such as reducing inter-frame redundancy, employing separate models for image-text relevance assessment, or utilizing temporal video grounding for event localization, substantially adopt unsupervised learning paradigms, whereas they struggle to address the complex scenarios in long video understanding. We propose Instructed Temporal Grounding for Videos (VideoITG), featuring customized frame sampling aligned with user instructions. The core of VideoITG is the VidThinker pipeline, an automated annotation framework that explicitly mimics the human annotation process. First, it generates detailed clip-level captions conditioned on the instruction; then, it retrieves relevant video segments through instruction-guided reasoning; finally, it performs fine-grained frame selection to pinpoint the most informative visual evidence. Leveraging VidThinker, we construct the VideoITG-40K dataset, containing 40K videos and 500K instructed temporal grounding annotations. We then design a plug-and-play VideoITG model, which takes advantage of visual language alignment and reasoning capabilities of Video-LLMs, for effective frame selection in a discriminative manner. Coupled with Video-LLMs, VideoITG achieves consistent performance improvements across multiple multimodal video understanding benchmarks, showing its superiority and great potentials for video understanding.
Eagle 2.5: Boosting Long-Context Post-Training for Frontier Vision-Language Models
Apr 21, 2025We introduce Eagle 2.5, a family of frontier vision-language models (VLMs) for long-context multimodal learning. Our work addresses the challenges in long video comprehension and high-resolution image understanding, introducing a generalist framework for both tasks. The proposed training framework incorporates Automatic Degrade Sampling and Image Area Preservation, two techniques that preserve contextual integrity and visual details. The framework also includes numerous efficiency optimizations in the pipeline for long-context data training. Finally, we propose Eagle-Video-110K, a novel dataset that integrates both story-level and clip-level annotations, facilitating long-video understanding. Eagle 2.5 demonstrates substantial improvements on long-context multimodal benchmarks, providing a robust solution to the limitations of existing VLMs. Notably, our best model Eagle 2.5-8B achieves 72.4% on Video-MME with 512 input frames, matching the results of top-tier commercial model such as GPT-4o and large-scale open-source models like Qwen2.5-VL-72B and InternVL2.5-78B.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
OmniDrive: A Holistic Vision-Language Dataset for Autonomous Driving with Counterfactual Reasoning
Apr 06, 2025
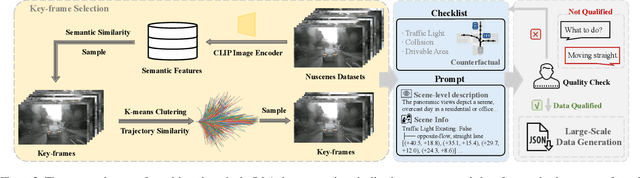
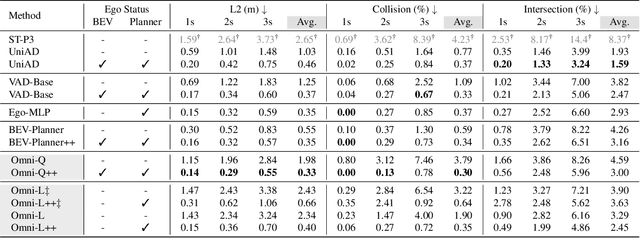
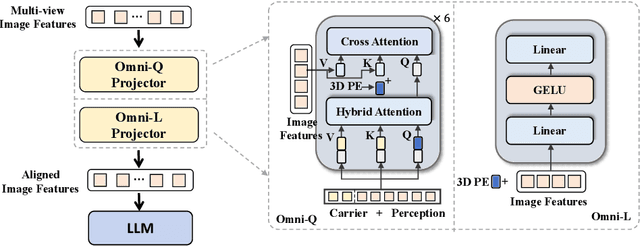
The advances in vision-language models (VLMs) have led to a growing interest in autonomous driving to leverage their strong reasoning capabilities. However, extending these capabilities from 2D to full 3D understanding is crucial for real-world applications. To address this challenge, we propose OmniDrive, a holistic vision-language dataset that aligns agent models with 3D driving tasks through counterfactual reasoning. This approach enhances decision-making by evaluating potential scenarios and their outcomes, similar to human drivers considering alternative actions. Our counterfactual-based synthetic data annotation process generates large-scale, high-quality datasets, providing denser supervision signals that bridge planning trajectories and language-based reasoning. Futher, we explore two advanced OmniDrive-Agent frameworks, namely Omni-L and Omni-Q, to assess the importance of vision-language alignment versus 3D perception, revealing critical insights into designing effective LLM-agents. Significant improvements on the DriveLM Q\&A benchmark and nuScenes open-loop planning demonstrate the effectiveness of our dataset and methods.
Slow-Fast Architecture for Video Multi-Modal Large Language Models
Apr 02, 2025Balancing temporal resolution and spatial detail under limited compute budget remains a key challenge for video-based multi-modal large language models (MLLMs). Existing methods typically compress video representations using predefined rules before feeding them into the LLM, resulting in irreversible information loss and often ignoring input instructions. To address this, we propose a novel slow-fast architecture that naturally circumvents this trade-off, enabling the use of more input frames while preserving spatial details. Inspired by how humans first skim a video before focusing on relevant parts, our slow-fast design employs a dual-token strategy: 1) "fast" visual tokens -- a compact set of compressed video features -- are fed into the LLM alongside text embeddings to provide a quick overview; 2) "slow" visual tokens -- uncompressed video features -- are cross-attended by text embeddings through specially designed hybrid decoder layers, enabling instruction-aware extraction of relevant visual details with linear complexity. We conduct systematic exploration to optimize both the overall architecture and key components. Experiments show that our model significantly outperforms self-attention-only baselines, extending the input capacity from 16 to 128 frames with just a 3% increase in computation, and achieving a 16% average performance improvement across five video understanding benchmarks. Our 7B model achieves state-of-the-art performance among models of similar size. Furthermore, our slow-fast architecture is a plug-and-play design that can be integrated into other video MLLMs to improve efficiency and scalability.