 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuoGen: Towards General Purpose Interleaved Multimodal Generation
Feb 03, 2026Interleaved multimodal generation enables capabilities beyond unimodal generation models, such as step-by-step instructional guides, visual planning, and generating visual drafts for reasoning. However, the quality of existing interleaved generation models under general instructions remains limited by insufficient training data and base model capacity. We present DuoGen, a general-purpose interleaved generation framework that systematically addresses data curation, architecture design, and evaluation. On the data side, we build a large-scale, high-quality instruction-tuning dataset by combining multimodal conversations rewritten from curated raw websites, and diverse synthetic examples covering everyday scenarios. Architecturally, DuoGen leverages the strong visual understanding of a pretrained multimodal LLM and the visual generation capabilities of a diffusion transformer (DiT) pretrained on video generation, avoiding costly unimodal pretraining and enabling flexible base model selection. A two-stage decoupled strategy first instruction-tunes the MLLM, then aligns DiT with it using curated interleaved image-text sequences. Across public and newly proposed benchmarks, DuoGen outperforms prior open-source models in text quality, image fidelity, and image-context alignment, and also achieves state-of-the-art performance on text-to-image and image editing among unified generation models. Data and code will be released at https://research.nvidia.com/labs/dir/duogen/.
T2I-Copilot: A Training-Free Multi-Agent Text-to-Image System for Enhanced Prompt Interpretation and Interactive Generation
Jul 28, 2025Text-to-Image (T2I) generative models have revolutionized content creation but remain highly sensitive to prompt phrasing, often requiring users to repeatedly refine prompts multiple times without clear feedback. While techniques such as automatic prompt engineering, controlled text embeddings, denoising, and multi-turn generation mitigate these issues, they offer limited controllability, or often necessitate additional training, restricting the generalization abilities. Thus, we introduce T2I-Copilot, a training-free multi-agent system that leverages collaboration between (Multimodal) Large Language Models to automate prompt phrasing, model selection, and iterative refinement. This approach significantly simplifies prompt engineering while enhancing generation quality and text-image alignment compared to direct generation. Specifically, T2I-Copilot consists of three agents: (1) Input Interpreter, which parses the input prompt, resolves ambiguities, and generates a standardized report; (2) Generation Engine, which selects the appropriate model from different types of T2I models and organizes visual and textual prompts to initiate generation; and (3) Quality Evaluator, which assesses aesthetic quality and text-image alignment, providing scores and feedback for potential regeneration. T2I-Copilot can operate fully autonomously while also supporting human-in-the-loop intervention for fine-grained control. On GenAI-Bench, using open-source generation models, T2I-Copilot achieves a VQA score comparable to commercial models RecraftV3 and Imagen 3, surpasses FLUX1.1-pro by 6.17% at only 16.59% of its cost, and outperforms FLUX.1-dev and SD 3.5 Large by 9.11% and 6.36%. Code will be released at: https://github.com/SHI-Labs/T2I-Copilot.
Generalized Neighborhood Attention: Multi-dimensional Sparse Attention at the Speed of Light
Apr 23, 2025Many sparse attention mechanisms such as Neighborhood Attention have typically failed to consistently deliver speedup over the self attention baseline. This is largely due to the level of complexity in attention infrastructure, and the rapid evolution of AI hardware architecture. At the same time, many state-of-the-art foundational models, particularly in computer vision, are heavily bound by attention, and need reliable sparsity to escape the O(n^2) complexity. In this paper, we study a class of promising sparse attention mechanisms that focus on locality, and aim to develop a better analytical model of their performance improvements. We first introduce Generalized Neighborhood Attention (GNA), which can describe sliding window, strided sliding window, and blocked attention. We then consider possible design choices in implementing these approaches, and create a simulator that can provide much more realistic speedup upper bounds for any given setting. Finally, we implement GNA on top of a state-of-the-art fused multi-headed attention (FMHA) kernel designed for the NVIDIA Blackwell architecture in CUTLASS. Our implementation can fully realize the maximum speedup theoretically possible in many perfectly block-sparse cases, and achieves an effective utilization of 1.3 petaFLOPs/second in FP16. In addition, we plug various GNA configurations into off-the-shelf generative models, such as Cosmos-7B, HunyuanVideo, and FLUX, and show that it can deliver 28% to 46% end-to-end speedup on B200 without any fine-tuning. We will open source our simulator and Blackwell kernels directly through the NATTEN project.
Slow-Fast Architecture for Video Multi-Modal Large Language Models
Apr 02, 2025Balancing temporal resolution and spatial detail under limited compute budget remains a key challenge for video-based multi-modal large language models (MLLMs). Existing methods typically compress video representations using predefined rules before feeding them into the LLM, resulting in irreversible information loss and often ignoring input instructions. To address this, we propose a novel slow-fast architecture that naturally circumvents this trade-off, enabling the use of more input frames while preserving spatial details. Inspired by how humans first skim a video before focusing on relevant parts, our slow-fast design employs a dual-token strategy: 1) "fast" visual tokens -- a compact set of compressed video features -- are fed into the LLM alongside text embeddings to provide a quick overview; 2) "slow" visual tokens -- uncompressed video features -- are cross-attended by text embeddings through specially designed hybrid decoder layers, enabling instruction-aware extraction of relevant visual details with linear complexity. We conduct systematic exploration to optimize both the overall architecture and key components. Experiments show that our model significantly outperforms self-attention-only baselines, extending the input capacity from 16 to 128 frames with just a 3% increase in computation, and achieving a 16% average performance improvement across five video understanding benchmarks. Our 7B model achieves state-of-the-art performance among models of similar size. Furthermore, our slow-fast architecture is a plug-and-play design that can be integrated into other video MLLMs to improve efficiency and scalability.
Template-Free Try-on Image Synthesis via Semantic-guided Optimization
Feb 06, 2021



The virtual try-on task is so attractive that it has drawn considerable attention in the field of computer vision. However, presenting the three-dimensional (3D) physical characteristic (e.g., pleat and shadow) based on a 2D image is very challenging. Although there have been several previous studies on 2D-based virtual try-on work, most 1) required user-specified target poses that are not user-friendly and may not be the best for the target clothing, and 2) failed to address some problematic cases, including facial details, clothing wrinkles and body occlusions. To address these two challenges, in this paper, we propose an innovative template-free try-on image synthesis (TF-TIS) network. The TF-TIS first synthesizes the target pose according to the user-specified in-shop clothing. Afterward, given an in-shop clothing image, a user image, and a synthesized pose, we propose a novel model for synthesizing a human try-on image with the target clothing in the best fitting pose. The qualitative and quantitative experiments both indicate that the proposed TF-TIS outperforms the state-of-the-art methods, especially for difficult cases.
Fashion Meets Computer Vision: A Survey
Mar 31, 2020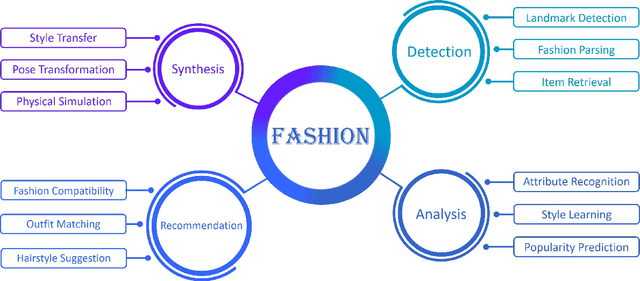

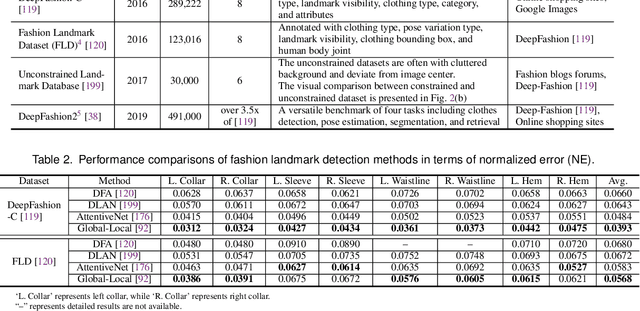

Fashion is the way we present ourselves to the world and has become one of the world's largest industries. Fashion, mainly conveyed by vision, has thus attracted much attention from computer vision researchers in recent years. Given the rapid development, this paper provides a comprehensive survey of more than 200 major fashion-related works covering four main aspects for enabling intelligent fashion: (1) Fashion detection includes landmark detection, fashion parsing, and item retrieval, (2) Fashion analysis contains attribute recognition, style learning, and popularity prediction, (3) Fashion synthesis involves style transfer, pose transformation, and physical simulation, and (4) Fashion recommendation comprises fashion compatibility, outfit matching, and hairstyle suggestion. For each task, the benchmark datasets and the evaluation protocols are summarized. Furthermore, we highlight promising directions for future research.