 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuoGen: Towards General Purpose Interleaved Multimodal Generation
Feb 03, 2026Interleaved multimodal generation enables capabilities beyond unimodal generation models, such as step-by-step instructional guides, visual planning, and generating visual drafts for reasoning. However, the quality of existing interleaved generation models under general instructions remains limited by insufficient training data and base model capacity. We present DuoGen, a general-purpose interleaved generation framework that systematically addresses data curation, architecture design, and evaluation. On the data side, we build a large-scale, high-quality instruction-tuning dataset by combining multimodal conversations rewritten from curated raw websites, and diverse synthetic examples covering everyday scenarios. Architecturally, DuoGen leverages the strong visual understanding of a pretrained multimodal LLM and the visual generation capabilities of a diffusion transformer (DiT) pretrained on video generation, avoiding costly unimodal pretraining and enabling flexible base model selection. A two-stage decoupled strategy first instruction-tunes the MLLM, then aligns DiT with it using curated interleaved image-text sequences. Across public and newly proposed benchmarks, DuoGen outperforms prior open-source models in text quality, image fidelity, and image-context alignment, and also achieves state-of-the-art performance on text-to-image and image editing among unified generation models. Data and code will be released at https://research.nvidia.com/labs/dir/duogen/.
SAGE: Exploring the Boundaries of Unsafe Concept Domain with Semantic-Augment Erasing
Jun 11, 2025Diffusion models (DMs) have achieved significant progress in text-to-image generation. However, the inevitable inclusion of sensitive information during pre-training poses safety risks, such as unsafe content generation and copyright infringement. Concept erasing finetunes weights to unlearn undesirable concepts, and has emerged as a promising solution. However, existing methods treat unsafe concept as a fixed word and repeatedly erase it, trapping DMs in ``word concept abyss'', which prevents generalized concept-related erasing. To escape this abyss, we introduce semantic-augment erasing which transforms concept word erasure into concept domain erasure by the cyclic self-check and self-erasure. It efficiently explores and unlearns the boundary representation of concept domain through semantic spatial relationships between original and training DMs, without requiring additional preprocessed data. Meanwhile, to mitigate the retention degradation of irrelevant concepts while erasing unsafe concepts, we further propose the global-local collaborative retention mechanism that combines global semantic relationship alignment with local predicted noise preservation, effectively expanding the retentive receptive field for irrelevant concepts. We name our method SAGE, and extensive experiments demonstrate the comprehensive superiority of SAGE compared with other methods in the safe generation of DMs. The code and weights will be open-sourced at https://github.com/KevinLight831/SAGE.
Generalized Neighborhood Attention: Multi-dimensional Sparse Attention at the Speed of Light
Apr 23, 2025Many sparse attention mechanisms such as Neighborhood Attention have typically failed to consistently deliver speedup over the self attention baseline. This is largely due to the level of complexity in attention infrastructure, and the rapid evolution of AI hardware architecture. At the same time, many state-of-the-art foundational models, particularly in computer vision, are heavily bound by attention, and need reliable sparsity to escape the O(n^2) complexity. In this paper, we study a class of promising sparse attention mechanisms that focus on locality, and aim to develop a better analytical model of their performance improvements. We first introduce Generalized Neighborhood Attention (GNA), which can describe sliding window, strided sliding window, and blocked attention. We then consider possible design choices in implementing these approaches, and create a simulator that can provide much more realistic speedup upper bounds for any given setting. Finally, we implement GNA on top of a state-of-the-art fused multi-headed attention (FMHA) kernel designed for the NVIDIA Blackwell architecture in CUTLASS. Our implementation can fully realize the maximum speedup theoretically possible in many perfectly block-sparse cases, and achieves an effective utilization of 1.3 petaFLOPs/second in FP16. In addition, we plug various GNA configurations into off-the-shelf generative models, such as Cosmos-7B, HunyuanVideo, and FLUX, and show that it can deliver 28% to 46% end-to-end speedup on B200 without any fine-tuning. We will open source our simulator and Blackwell kernels directly through the NATTEN project.
Collaborative Vision-Text Representation Optimizing for Open-Vocabulary Segmentation
Aug 01, 2024

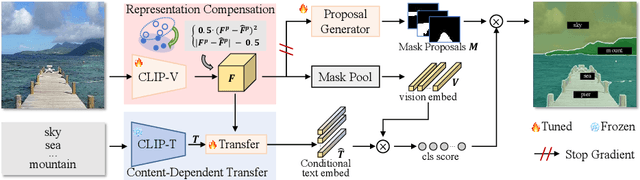

Pre-trained vision-language models, e.g. CLIP, have been increasingly used to address the challenging Open-Vocabulary Segmentation (OVS) task, benefiting from their well-aligned vision-text embedding space. Typical solutions involve either freezing CLIP during training to unilaterally maintain its zero-shot capability, or fine-tuning CLIP vision encoder to achieve perceptual sensitivity to local regions. However, few of them incorporate vision-text collaborative optimization. Based on this, we propose the Content-Dependent Transfer to adaptively enhance each text embedding by interacting with the input image, which presents a parameter-efficient way to optimize the text representation. Besides, we additionally introduce a Representation Compensation strategy, reviewing the original CLIP-V representation as compensation to maintain the zero-shot capability of CLIP. In this way, the vision and text representation of CLIP are optimized collaboratively, enhancing the alignment of the vision-text feature space. To the best of our knowledge, we are the first to establish the collaborative vision-text optimizing mechanism within the OVS field. Extensive experiments demonstrate our method achieves superior performance on popular OVS benchmarks. In open-vocabulary semantic segmentation, our method outperforms the previous state-of-the-art approaches by +0.5, +2.3, +3.4, +0.4 and +1.1 mIoU, respectively on A-847, A-150, PC-459, PC-59 and PAS-20. Furthermore, in a panoptic setting on ADE20K, we achieve the performance of 27.1 PQ, 73.5 SQ, and 32.9 RQ. Code will be available at https://github.com/jiaosiyu1999/MAFT-Plus.git .
ClassDiffusion: More Aligned Personalization Tuning with Explicit Class Guidance
May 27, 2024Recent text-to-image customization works have been proven successful in generating images of given concepts by fine-tuning the diffusion models on a few examples. However, these methods tend to overfit the concepts, resulting in failure to create the concept under multiple conditions (e.g. headphone is missing when generating a <sks> dog wearing a headphone'). Interestingly, we notice that the base model before fine-tuning exhibits the capability to compose the base concept with other elements (e.g. a dog wearing a headphone) implying that the compositional ability only disappears after personalization tuning. Inspired by this observation, we present ClassDiffusion, a simple technique that leverages a semantic preservation loss to explicitly regulate the concept space when learning the new concept. Despite its simplicity, this helps avoid semantic drift when fine-tuning on the target concepts. Extensive qualitative and quantitative experiments demonstrate that the use of semantic preservation loss effectively improves the compositional abilities of the fine-tune models. In response to the ineffective evaluation of CLIP-T metrics, we introduce BLIP2-T metric, a more equitable and effective evaluation metric for this particular domain. We also provide in-depth empirical study and theoretical analysis to better understand the role of the proposed loss. Lastly, we also extend our ClassDiffusion to personalized video generation, demonstrating its flexibility.