 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming Generative Synthetic Data for X-ray Prohibited Item Detection
Nov 19, 2025


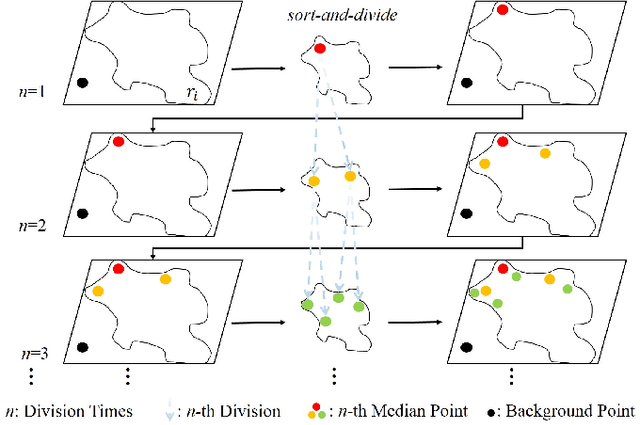
Training prohibited item detection models requires a large amount of X-ray security images, but collecting and annotating these images is time-consuming and laborious. To address data insufficiency, X-ray security image synthesis methods composite images to scale up datasets. However, previous methods primarily follow a two-stage pipeline, where they implement labor-intensive foreground extraction in the first stage and then composite images in the second stage. Such a pipeline introduces inevitable extra labor cost and is not efficient. In this paper, we propose a one-stage X-ray security image synthesis pipeline (Xsyn) based on text-to-image generation, which incorporates two effective strategies to improve the usability of synthetic images. The Cross-Attention Refinement (CAR) strategy leverages the cross-attention map from the diffusion model to refine the bounding box annotation. The Background Occlusion Modeling (BOM) strategy explicitly models background occlusion in the latent space to enhance imaging complexity. To the best of our knowledge, compared with previous methods, Xsyn is the first to achieve high-quality X-ray security image synthesis without extra labor cost. Experiments demonstrate that our method outperforms all previous methods with 1.2% mAP improvement, and the synthetic images generated by our method are beneficial to improve prohibited item detection performance across various X-ray security datasets and detectors. Code is available at https://github.com/pILLOW-1/Xsyn/.
All-in-One Slider for Attribute Manipulation in Diffusion Models
Aug 26, 2025Text-to-image (T2I) diffusion models have made significant strides in generating high-quality images. However, progressively manipulating certain attributes of generated images to meet the desired user expectations remains challenging, particularly for content with rich details, such as human faces. Some studies have attempted to address this by training slider modules. However, they follow a One-for-One manner, where an independent slider is trained for each attribute, requiring additional training whenever a new attribute is introduced. This not only results in parameter redundancy accumulated by sliders but also restricts the flexibility of practical applications and the scalability of attribute manipulation. To address this issue, we introduce the All-in-One Slider, a lightweight module that decomposes the text embedding space into sparse, semantically meaningful attribute directions. Once trained, it functions as a general-purpose slider, enabling interpretable and fine-grained continuous control over various attributes. Moreover, by recombining the learned directions, the All-in-One Slider supports zero-shot manipulation of unseen attributes (e.g., races and celebrities) and the composition of multiple attributes. Extensive experiments demonstrate that our method enables accurate and scalable attribute manipulation, achieving notable improvements compared to previous methods. Furthermore, our method can be extended to integrate with the inversion framework to perform attribute manipulation on real images, broadening its applicability to various real-world scenarios. The code and trained model will be released at: https://github.com/ywxsuperstar/KSAE-FaceSteer.
SAGE: Exploring the Boundaries of Unsafe Concept Domain with Semantic-Augment Erasing
Jun 11, 2025Diffusion models (DMs) have achieved significant progress in text-to-image generation. However, the inevitable inclusion of sensitive information during pre-training poses safety risks, such as unsafe content generation and copyright infringement. Concept erasing finetunes weights to unlearn undesirable concepts, and has emerged as a promising solution. However, existing methods treat unsafe concept as a fixed word and repeatedly erase it, trapping DMs in ``word concept abyss'', which prevents generalized concept-related erasing. To escape this abyss, we introduce semantic-augment erasing which transforms concept word erasure into concept domain erasure by the cyclic self-check and self-erasure. It efficiently explores and unlearns the boundary representation of concept domain through semantic spatial relationships between original and training DMs, without requiring additional preprocessed data. Meanwhile, to mitigate the retention degradation of irrelevant concepts while erasing unsafe concepts, we further propose the global-local collaborative retention mechanism that combines global semantic relationship alignment with local predicted noise preservation, effectively expanding the retentive receptive field for irrelevant concepts. We name our method SAGE, and extensive experiments demonstrate the comprehensive superiority of SAGE compared with other methods in the safe generation of DMs. The code and weights will be open-sourced at https://github.com/KevinLight831/SAGE.
BGM: Background Mixup for X-ray Prohibited Items Detection
Nov 30, 2024Prohibited item detection is crucial for ensuring public safety, yet current X-ray image-based detection methods often lack comprehensive data-driven exploration. This paper introduces a novel data augmentation approach tailored for prohibited item detection, leveraging unique characteristics inherent to X-ray imagery. Our method is motivated by observations of physical properties including: 1) X-ray Transmission Imagery: Unlike reflected light images, transmitted X-ray pixels represent composite information from multiple materials along the imaging path. 2) Material-based Pseudo-coloring: Pseudo-color rendering in X-ray images correlates directly with material properties, aiding in material distinction. Building on a novel perspective from physical properties, we propose a simple yet effective X-ray image augmentation technique, Background Mixup (BGM), for prohibited item detection in security screening contexts. The essence is the rich background simulation of X-ray images to induce the model to increase its attention to the foreground. The approach introduces 1) contour information of baggage and 2) variation of material information into the original image by Mixup at patch level. Background Mixup is plug-and-play, parameter-free, highly generalizable and provides an effective solution to the limitations of classical visual augmentations in non-reflected light imagery. When implemented with different high-performance detectors, our augmentation method consistently boosts performance across diverse X-ray datasets from various devices and environments. Extensive experimental results demonstrate that our approach surpasses strong baselines while maintaining similar training resources.
Collaborative Vision-Text Representation Optimizing for Open-Vocabulary Segmentation
Aug 01, 2024

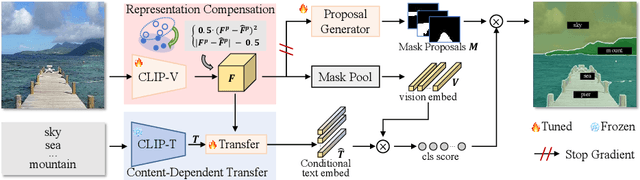

Pre-trained vision-language models, e.g. CLIP, have been increasingly used to address the challenging Open-Vocabulary Segmentation (OVS) task, benefiting from their well-aligned vision-text embedding space. Typical solutions involve either freezing CLIP during training to unilaterally maintain its zero-shot capability, or fine-tuning CLIP vision encoder to achieve perceptual sensitivity to local regions. However, few of them incorporate vision-text collaborative optimization. Based on this, we propose the Content-Dependent Transfer to adaptively enhance each text embedding by interacting with the input image, which presents a parameter-efficient way to optimize the text representation. Besides, we additionally introduce a Representation Compensation strategy, reviewing the original CLIP-V representation as compensation to maintain the zero-shot capability of CLIP. In this way, the vision and text representation of CLIP are optimized collaboratively, enhancing the alignment of the vision-text feature space. To the best of our knowledge, we are the first to establish the collaborative vision-text optimizing mechanism within the OVS field. Extensive experiments demonstrate our method achieves superior performance on popular OVS benchmarks. In open-vocabulary semantic segmentation, our method outperforms the previous state-of-the-art approaches by +0.5, +2.3, +3.4, +0.4 and +1.1 mIoU, respectively on A-847, A-150, PC-459, PC-59 and PAS-20. Furthermore, in a panoptic setting on ADE20K, we achieve the performance of 27.1 PQ, 73.5 SQ, and 32.9 RQ. Code will be available at https://github.com/jiaosiyu1999/MAFT-Plus.git .
CTP: Towards Vision-Language Continual Pretraining via Compatible Momentum Contrast and Topology Preservation
Aug 14, 2023



Vision-Language Pretraining (VLP) has shown impressive results on diverse downstream tasks by offline training on large-scale datasets. Regarding the growing nature of real-world data, such an offline training paradigm on ever-expanding data is unsustainable, because models lack the continual learning ability to accumulate knowledge constantly. However, most continual learning studies are limited to uni-modal classification and existing multi-modal datasets cannot simulate continual non-stationary data stream scenarios. To support the study of Vision-Language Continual Pretraining (VLCP), we first contribute a comprehensive and unified benchmark dataset P9D which contains over one million product image-text pairs from 9 industries. The data from each industry as an independent task supports continual learning and conforms to the real-world long-tail nature to simulate pretraining on web data. We comprehensively study the characteristics and challenges of VLCP, and propose a new algorithm: Compatible momentum contrast with Topology Preservation, dubbed CTP. The compatible momentum model absorbs the knowledge of the current and previous-task models to flexibly update the modal feature. Moreover, Topology Preservation transfers the knowledge of embedding across tasks while preserving the flexibility of feature adjustment. The experimental results demonstrate our method not only achieves superior performance compared with other baselines but also does not bring an expensive training burden. Dataset and codes are available at https://github.com/KevinLight831/CTP.
Towards Fast and Accurate Real-World Depth Super-Resolution: Benchmark Dataset and Baseline
Apr 13, 2021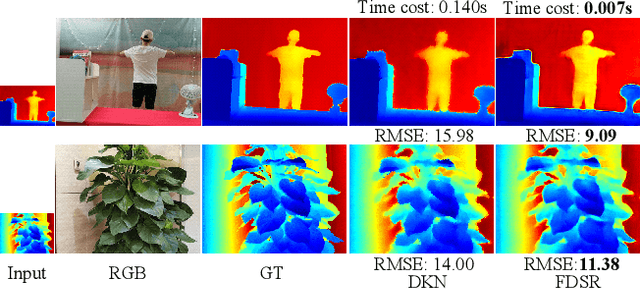

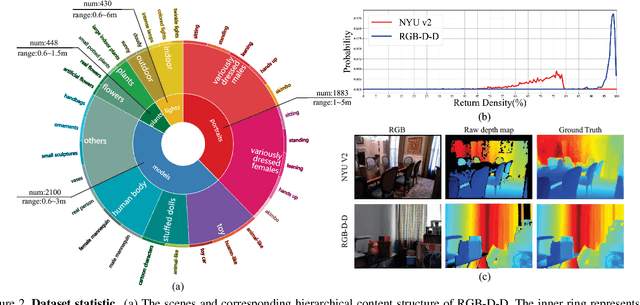

Depth maps obtained by commercial depth sensors are always in low-resolution, making it difficult to be used in various computer vision tasks. Thus, depth map super-resolution (SR) is a practical and valuable task, which upscales the depth map into high-resolution (HR) space. However, limited by the lack of real-world paired low-resolution (LR) and HR depth maps, most existing methods use downsampling to obtain paired training samples. To this end, we first construct a large-scale dataset named "RGB-D-D", which can greatly promote the study of depth map SR and even more depth-related real-world tasks. The "D-D" in our dataset represents the paired LR and HR depth maps captured from mobile phone and Lucid Helios respectively ranging from indoor scenes to challenging outdoor scenes. Besides, we provide a fast depth map super-resolution (FDSR) baseline, in which the high-frequency component adaptively decomposed from RGB image to guide the depth map SR. Extensive experiments on existing public datasets demonstrate the effectiveness and efficiency of our network compared with the state-of-the-art methods. Moreover, for the real-world LR depth maps, our algorithm can produce more accurate HR depth maps with clearer boundaries and to some extent correct the depth value errors.