 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Vision-Text Representation Optimizing for Open-Vocabulary Segmentation
Paper and Code


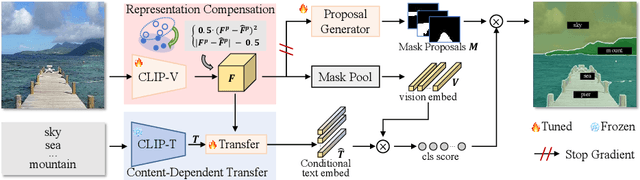

Pre-trained vision-language models, e.g. CLIP, have been increasingly used to address the challenging Open-Vocabulary Segmentation (OVS) task, benefiting from their well-aligned vision-text embedding space. Typical solutions involve either freezing CLIP during training to unilaterally maintain its zero-shot capability, or fine-tuning CLIP vision encoder to achieve perceptual sensitivity to local regions. However, few of them incorporate vision-text collaborative optimization. Based on this, we propose the Content-Dependent Transfer to adaptively enhance each text embedding by interacting with the input image, which presents a parameter-efficient way to optimize the text representation. Besides, we additionally introduce a Representation Compensation strategy, reviewing the original CLIP-V representation as compensation to maintain the zero-shot capability of CLIP. In this way, the vision and text representation of CLIP are optimized collaboratively, enhancing the alignment of the vision-text feature space. To the best of our knowledge, we are the first to establish the collaborative vision-text optimizing mechanism within the OVS field. Extensive experiments demonstrate our method achieves superior performance on popular OVS benchmarks. In open-vocabulary semantic segmentation, our method outperforms the previous state-of-the-art approaches by +0.5, +2.3, +3.4, +0.4 and +1.1 mIoU, respectively on A-847, A-150, PC-459, PC-59 and PAS-20. Furthermore, in a panoptic setting on ADE20K, we achieve the performance of 27.1 PQ, 73.5 SQ, and 32.9 RQ. Code will be available at https://github.com/jiaosiyu1999/MAFT-Plus.git .