 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasHost Builds It All: Autonomous Multi-Agent System Directed by Reinforcement Learning
Jun 12, 2025Large Language Model (LLM)-driven Multi-agent systems (Mas) have recently emerged as a powerful paradigm for tackling complex real-world tasks. However, existing Mas construction methods typically rely on manually crafted interaction mechanisms or heuristic rules, introducing human biases and constraining the autonomous ability. Even with recent advances in adaptive Mas construction, existing systems largely remain within the paradigm of semi-autonomous patterns. In this work, we propose MasHost, a Reinforcement Learning (RL)-based framework for autonomous and query-adaptive Mas design. By formulating Mas construction as a graph search problem, our proposed MasHost jointly samples agent roles and their interactions through a unified probabilistic sampling mechanism. Beyond the accuracy and efficiency objectives pursued in prior works, we introduce component rationality as an additional and novel design principle in Mas. To achieve this multi-objective optimization, we propose Hierarchical Relative Policy Optimization (HRPO), a novel RL strategy that collaboratively integrates group-relative advantages and action-wise rewards. To our knowledge, our proposed MasHost is the first RL-driven framework for autonomous Mas graph construction. Extensive experiments on six benchmarks demonstrate that MasHost consistently outperforms most competitive baselines, validating its effectiveness, efficiency, and structure rationality.
SAGE: Exploring the Boundaries of Unsafe Concept Domain with Semantic-Augment Erasing
Jun 11, 2025Diffusion models (DMs) have achieved significant progress in text-to-image generation. However, the inevitable inclusion of sensitive information during pre-training poses safety risks, such as unsafe content generation and copyright infringement. Concept erasing finetunes weights to unlearn undesirable concepts, and has emerged as a promising solution. However, existing methods treat unsafe concept as a fixed word and repeatedly erase it, trapping DMs in ``word concept abyss'', which prevents generalized concept-related erasing. To escape this abyss, we introduce semantic-augment erasing which transforms concept word erasure into concept domain erasure by the cyclic self-check and self-erasure. It efficiently explores and unlearns the boundary representation of concept domain through semantic spatial relationships between original and training DMs, without requiring additional preprocessed data. Meanwhile, to mitigate the retention degradation of irrelevant concepts while erasing unsafe concepts, we further propose the global-local collaborative retention mechanism that combines global semantic relationship alignment with local predicted noise preservation, effectively expanding the retentive receptive field for irrelevant concepts. We name our method SAGE, and extensive experiments demonstrate the comprehensive superiority of SAGE compared with other methods in the safe generation of DMs. The code and weights will be open-sourced at https://github.com/KevinLight831/SAGE.
PreFM: Online Audio-Visual Event Parsing via Predictive Future Modeling
May 29, 2025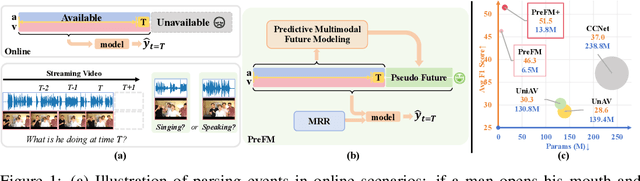
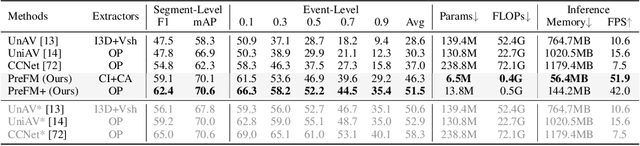
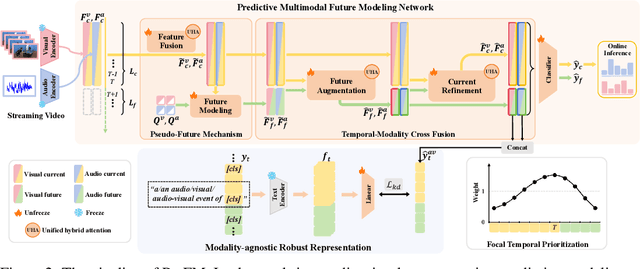
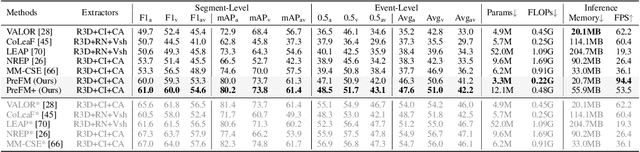
Audio-visual event parsing plays a crucial role in understanding multimodal video content, but existing methods typically rely on offline processing of entire videos with huge model sizes, limiting their real-time applicability. We introduce Online Audio-Visual Event Parsing (On-AVEP), a novel paradigm for parsing audio, visual, and audio-visual events by sequentially analyzing incoming video streams. The On-AVEP task necessitates models with two key capabilities: (1) Accurate online inference, to effectively distinguish events with unclear and limited context in online settings, and (2) Real-time efficiency, to balance high performance with computational constraints. To cultivate these, we propose the Predictive Future Modeling (PreFM) framework featured by (a) predictive multimodal future modeling to infer and integrate beneficial future audio-visual cues, thereby enhancing contextual understanding and (b) modality-agnostic robust representation along with focal temporal prioritization to improve precision and generalization. Extensive experiments on the UnAV-100 and LLP datasets show PreFM significantly outperforms state-of-the-art methods by a large margin with significantly fewer parameters, offering an insightful approach for real-time multimodal video understanding. Code is available at https://github.com/XiaoYu-1123/PreFM.
Rendering Anywhere You See: Renderability Field-guided Gaussian Splatting
Apr 27, 2025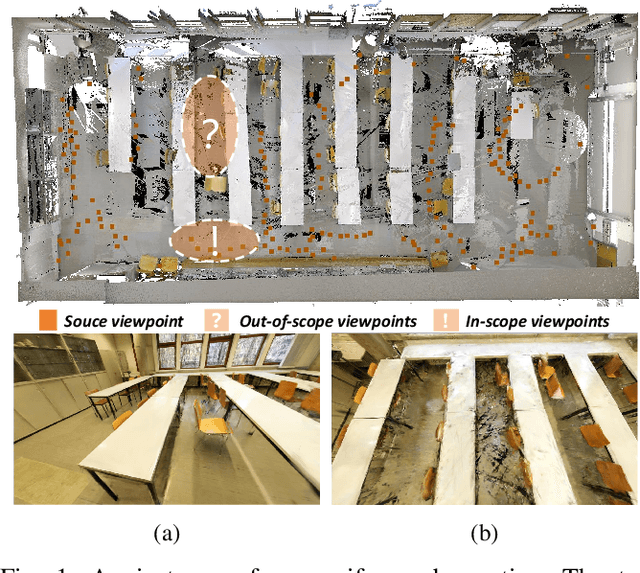
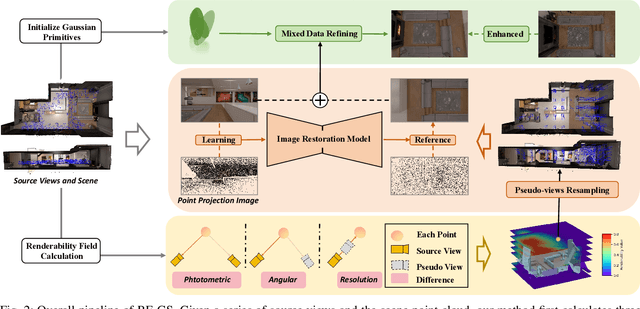
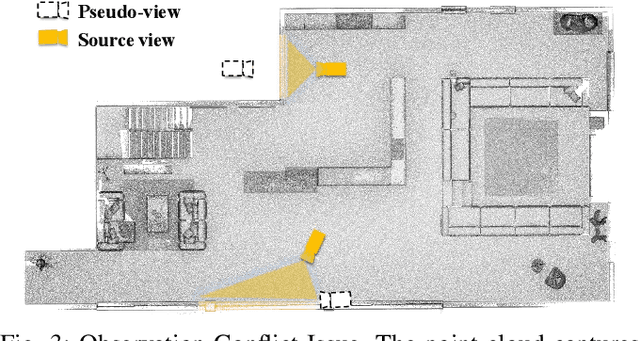

Scene view synthesis, which generates novel views from limited perspectives, is increasingly vital for applications like virtual reality, augmented reality, and robotics. Unlike object-based tasks, such as generating 360{\deg} views of a car, scene view synthesis handles entire environments where non-uniform observations pose unique challenges for stable rendering quality. To address this issue, we propose a novel approach: renderability field-guided gaussian splatting (RF-GS). This method quantifies input inhomogeneity through a renderability field, guiding pseudo-view sampling to enhanced visual consistency. To ensure the quality of wide-baseline pseudo-views, we train an image restoration model to map point projections to visible-light styles. Additionally, our validated hybrid data optimization strategy effectively fuses information of pseudo-view angles and source view textures. Comparative experiments on simulated and real-world data show that our method outperforms existing approaches in rendering stability.
IPSeg: Image Posterior Mitigates Semantic Drift in Class-Incremental Segmentation
Feb 07, 2025Class incremental learning aims to enable models to learn from sequential, non-stationary data streams across different tasks without catastrophic forgetting. In class incremental semantic segmentation (CISS), the semantic content of image pixels evolves over incremental phases, known as semantic drift. In this work, we identify two critical challenges in CISS that contribute to semantic drift and degrade performance. First, we highlight the issue of separate optimization, where different parts of the model are optimized in distinct incremental stages, leading to misaligned probability scales. Second, we identify noisy semantics arising from inappropriate pseudo-labeling, which results in sub-optimal results. To address these challenges, we propose a novel and effective approach, Image Posterior and Semantics Decoupling for Segmentation (IPSeg). IPSeg introduces two key mechanisms: (1) leveraging image posterior probabilities to align optimization across stages and mitigate the effects of separate optimization, and (2) employing semantics decoupling to handle noisy semantics and tailor learning strategies for different semantics. Extensive experiments on the Pascal VOC 2012 and ADE20K datasets demonstrate that IPSeg achieves superior performance compared to state-of-the-art methods, particularly in challenging long-term incremental scenarios.
FAVbot: An Autonomous Target Tracking Micro-Robot with Frequency Actuation Control
Jan 26, 2025



Robotic autonomy at centimeter scale requires compact and miniaturization-friendly actuation integrated with sensing and neural network processing assembly within a tiny form factor. Applications of such systems have witnessed significant advancements in recent years in fields such as healthcare, manufacturing, and post-disaster rescue. The system design at this scale puts stringent constraints on power consumption for both the sensory front-end and actuation back-end and the weight of the electronic assembly for robust operation. In this paper, we introduce FAVbot, the first autonomous mobile micro-robotic system integrated with a novel actuation mechanism and convolutional neural network (CNN) based computer vision - all integrated within a compact 3-cm form factor. The novel actuation mechanism utilizes mechanical resonance phenomenon to achieve frequency-controlled steering with a single piezoelectric actuator. Experimental results demonstrate the effectiveness of FAVbot's frequency-controlled actuation, which offers a diverse selection of resonance modes with different motion characteristics. The actuation system is complemented with the vision front-end where a camera along with a microcontroller supports object detection for closed-loop control and autonomous target tracking. This enables adaptive navigation in dynamic environments. This work contributes to the evolving landscape of neural network-enabled micro-robotic systems showing the smallest autonomous robot built using controllable multi-directional single-actuator mechanism.
PharmaGPT: Domain-Specific Large Language Models for Bio-Pharmaceutical and Chemistry
Jul 03, 2024



Large language models (LLMs) have revolutionized Natural Language Processing (NLP) by by minimizing the need for complex feature engineering. However, the application of LLMs in specialized domains like biopharmaceuticals and chemistry remains largely unexplored. These fields are characterized by intricate terminologies, specialized knowledge, and a high demand for precision areas where general purpose LLMs often fall short. In this study, we introduce PharmGPT, a suite of multilingual LLMs with 13 billion and 70 billion parameters, specifically trained on a comprehensive corpus of hundreds of billions of tokens tailored to the Bio-Pharmaceutical and Chemical sectors. Our evaluation shows that PharmGPT matches or surpasses existing general models on key benchmarks, such as NAPLEX, demonstrating its exceptional capability in domain-specific tasks. This advancement establishes a new benchmark for LLMs in the Bio-Pharmaceutical and Chemical fields, addressing the existing gap in specialized language modeling. Furthermore, this suggests a promising path for enhanced research and development in these specialized areas, paving the way for more precise and effective applications of NLP in specialized domains.
PharmGPT: Domain-Specific Large Language Models for Bio-Pharmaceutical and Chemistry
Jun 26, 2024Large language models (LLMs) have revolutionized Natural Language Processing (NLP) by by minimizing the need for complex feature engineering. However, the application of LLMs in specialized domains like biopharmaceuticals and chemistry remains largely unexplored. These fields are characterized by intricate terminologies, specialized knowledge, and a high demand for precision areas where general purpose LLMs often fall short. In this study, we introduce PharmGPT, a suite of multilingual LLMs with 13 billion and 70 billion parameters, specifically trained on a comprehensive corpus of hundreds of billions of tokens tailored to the Bio-Pharmaceutical and Chemical sectors. Our evaluation shows that PharmGPT matches or surpasses existing general models on key benchmarks, such as NAPLEX, demonstrating its exceptional capability in domain-specific tasks. This advancement establishes a new benchmark for LLMs in the Bio-Pharmaceutical and Chemical fields, addressing the existing gap in specialized language modeling. Furthermore, this suggests a promising path for enhanced research and development in these specialized areas, paving the way for more precise and effective applications of NLP in specialized domains.
PatentGPT: A Large Language Model for Intellectual Property
Apr 30, 2024

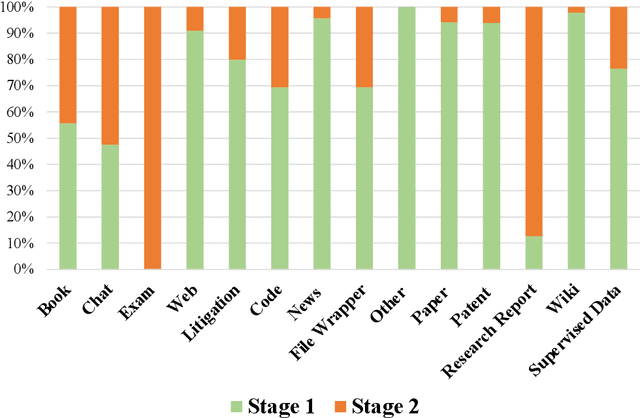
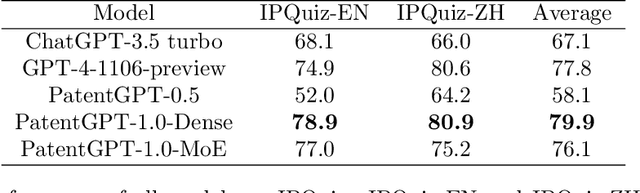
In recent years, large language models have attracted significant attention due to their exceptional performance across a multitude of natural language process tasks, and have been widely applied in various fields. However, the application of large language models in the Intellectual Property (IP) space is challenging due to the strong need for specialized knowledge, privacy protection, processing of extremely long text in this field. In this technical report, we present for the first time a low-cost, standardized procedure for training IP-oriented LLMs, meeting the unique requirements of the IP domain. Using this standard process, we have trained the PatentGPT series models based on open-source pretrained models. By evaluating them on the open-source IP-oriented benchmark MOZIP, our domain-specific LLMs outperforms GPT-4, indicating the effectiveness of the proposed training procedure and the expertise of the PatentGPT models in the IP demain. What is impressive is that our model significantly outperformed GPT-4 on the 2019 China Patent Agent Qualification Examination by achieving a score of 65, reaching the level of human experts. Additionally, the PatentGPT model, which utilizes the SMoE architecture, achieves performance comparable to that of GPT-4 in the IP domain and demonstrates a better cost-performance ratio on long-text tasks, potentially serving as an alternative to GPT-4 within the IP domain.
Collaborative-Enhanced Prediction of Spending on Newly Downloaded Mobile Games under Consumption Uncertainty
Apr 12, 2024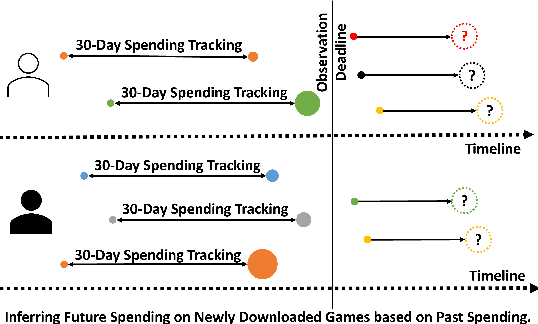
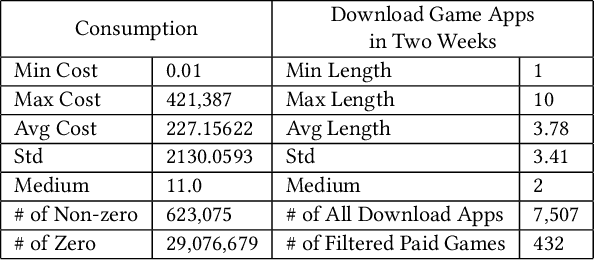
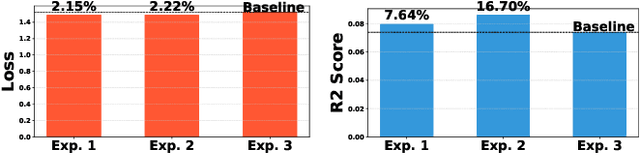
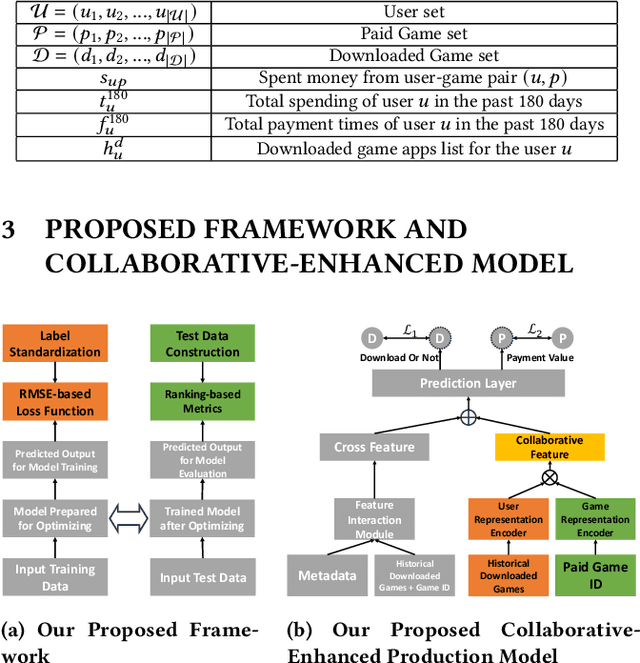
With the surge in mobile gaming, accurately predicting user spending on newly downloaded games has become paramount for maximizing revenue. However, the inherently unpredictable nature of user behavior poses significant challenges in this endeavor. To address this, we propose a robust model training and evaluation framework aimed at standardizing spending data to mitigate label variance and extremes, ensuring stability in the modeling process. Within this framework, we introduce a collaborative-enhanced model designed to predict user game spending without relying on user IDs, thus ensuring user privacy and enabling seamless online training. Our model adopts a unique approach by separately representing user preferences and game features before merging them as input to the spending prediction module. Through rigorous experimentation, our approach demonstrates notable improvements over production models, achieving a remarkable \textbf{17.11}\% enhancement on offline data and an impressive \textbf{50.65}\% boost in an online A/B test. In summary, our contributions underscore the importance of stable model training frameworks and the efficacy of collaborative-enhanced models in predicting user spending behavior in mobile gaming.