 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPA: Learning GUI Process Automation from Demonstrations
Apr 02, 2026GUI Process Automation (GPA) is a lightweight but general vision-based Robotic Process Automation (RPA), which enables fast and stable process replay with only a single demo. Addressing the fragility of traditional RPA and the non-deterministic risks of current vision language model-based GUI agents, GPA introduces three core benefits: (1) Robustness via Sequential Monte Carlo-based localization to handle rescaling and detection uncertainty; (2) Deterministic and Reliability safeguarded by readiness calibration; and (3) Privacy through fast, fully local execution. This approach delivers the adaptability, robustness, and security required for enterprise workflows. It can also be used as an MCP/CLI tool by other agents with coding capabilities so that the agent only reasons and orchestrates while GPA handles the GUI execution. We conducted a pilot experiment to compare GPA with Gemini 3 Pro (with CUA tools) and found that GPA achieves higher success rate with 10 times faster execution speed in finishing long-horizon GUI tasks.
EVATok: Adaptive Length Video Tokenization for Efficient Visual Autoregressive Generation
Mar 12, 2026Autoregressive (AR) video generative models rely on video tokenizers that compress pixels into discrete token sequences. The length of these token sequences is crucial for balancing reconstruction quality against downstream generation computational cost. Traditional video tokenizers apply a uniform token assignment across temporal blocks of different videos, often wasting tokens on simple, static, or repetitive segments while underserving dynamic or complex ones. To address this inefficiency, we introduce $\textbf{EVATok}$, a framework to produce $\textbf{E}$fficient $\textbf{V}$ideo $\textbf{A}$daptive $\textbf{Tok}$enizers. Our framework estimates optimal token assignments for each video to achieve the best quality-cost trade-off, develops lightweight routers for fast prediction of these optimal assignments, and trains adaptive tokenizers that encode videos based on the assignments predicted by routers. We demonstrate that EVATok delivers substantial improvements in efficiency and overall quality for video reconstruction and downstream AR generation. Enhanced by our advanced training recipe that integrates video semantic encoders, EVATok achieves superior reconstruction and state-of-the-art class-to-video generation on UCF-101, with at least 24.4% savings in average token usage compared to the prior state-of-the-art LARP and our fixed-length baseline.
W&D:Scaling Parallel Tool Calling for Efficient Deep Research Agents
Feb 07, 2026Deep research agents have emerged as powerful tools for automating complex intellectual tasks through multi-step reasoning and web-based information seeking. While recent efforts have successfully enhanced these agents by scaling depth through increasing the number of sequential thinking and tool calls, the potential of scaling width via parallel tool calling remains largely unexplored. In this work, we propose the Wide and Deep research agent, a framework designed to investigate the behavior and performance of agents when scaling not only depth but also width via parallel tool calling. Unlike existing approaches that rely on complex multi-agent orchestration to parallelize workloads, our method leverages intrinsic parallel tool calling to facilitate effective coordination within a single reasoning step. We demonstrate that scaling width significantly improves performance on deep research benchmarks while reducing the number of turns required to obtain correct answers. Furthermore, we analyze the factors driving these improvements through case studies and explore various tool call schedulers to optimize parallel tool calling strategy. Our findings suggest that optimizing the trade-off between width and depth is a critical pathway toward high-efficiency deep research agents. Notably, without context management or other tricks, we obtain 62.2% accuracy with GPT-5-Medium on BrowseComp, surpassing the original 54.9% reported by GPT-5-High.
The Scalability of Simplicity: Empirical Analysis of Vision-Language Learning with a Single Transformer
Apr 14, 2025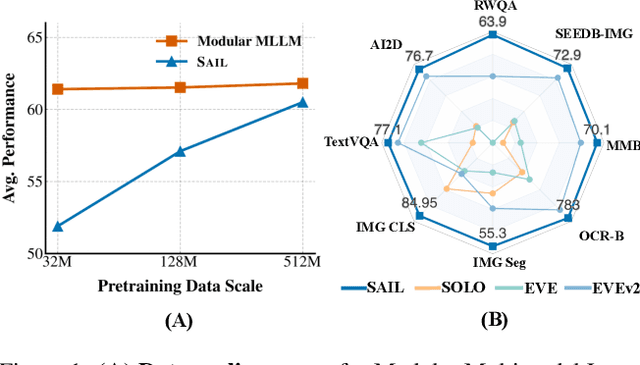
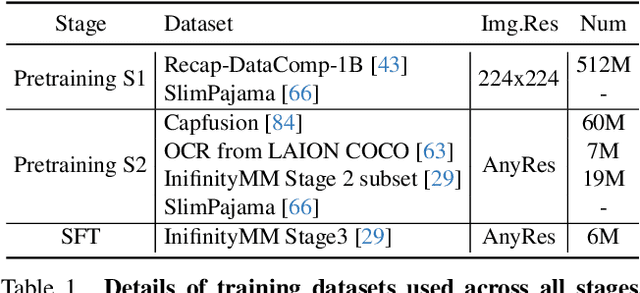
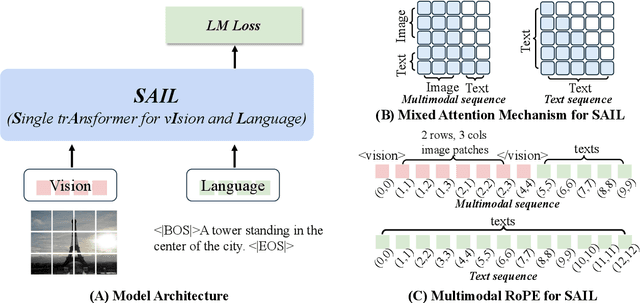
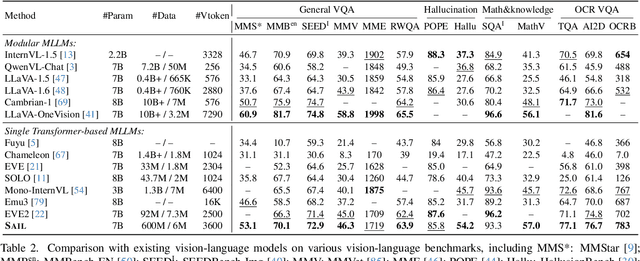
This paper introduces SAIL, a single transformer unified multimodal large language model (MLLM) that integrates raw pixel encoding and language decoding within a singular architecture. Unlike existing modular MLLMs, which rely on a pre-trained vision transformer (ViT), SAIL eliminates the need for a separate vision encoder, presenting a more minimalist architecture design. Instead of introducing novel architectural components, SAIL adapts mix-attention mechanisms and multimodal positional encodings to better align with the distinct characteristics of visual and textual modalities. We systematically compare SAIL's properties-including scalability, cross-modal information flow patterns, and visual representation capabilities-with those of modular MLLMs. By scaling both training data and model size, SAIL achieves performance comparable to modular MLLMs. Notably, the removal of pretrained ViT components enhances SAIL's scalability and results in significantly different cross-modal information flow patterns. Moreover, SAIL demonstrates strong visual representation capabilities, achieving results on par with ViT-22B in vision tasks such as semantic segmentation. Code and models are available at https://github.com/bytedance/SAIL.
GigaTok: Scaling Visual Tokenizers to 3 Billion Parameters for Autoregressive Image Generation
Apr 11, 2025In autoregressive (AR) image generation, visual tokenizers compress images into compact discrete latent tokens, enabling efficient training of downstream autoregressive models for visual generation via next-token prediction. While scaling visual tokenizers improves image reconstruction quality, it often degrades downstream generation quality -- a challenge not adequately addressed in existing literature. To address this, we introduce GigaTok, the first approach to simultaneously improve image reconstruction, generation, and representation learning when scaling visual tokenizers. We identify the growing complexity of latent space as the key factor behind the reconstruction vs. generation dilemma. To mitigate this, we propose semantic regularization, which aligns tokenizer features with semantically consistent features from a pre-trained visual encoder. This constraint prevents excessive latent space complexity during scaling, yielding consistent improvements in both reconstruction and downstream autoregressive generation. Building on semantic regularization, we explore three key practices for scaling tokenizers:(1) using 1D tokenizers for better scalability, (2) prioritizing decoder scaling when expanding both encoder and decoder, and (3) employing entropy loss to stabilize training for billion-scale tokenizers. By scaling to $\bf{3 \space billion}$ parameters, GigaTok achieves state-of-the-art performance in reconstruction, downstream AR generation, and downstream AR representation quality.
MagicArticulate: Make Your 3D Models Articulation-Ready
Feb 18, 2025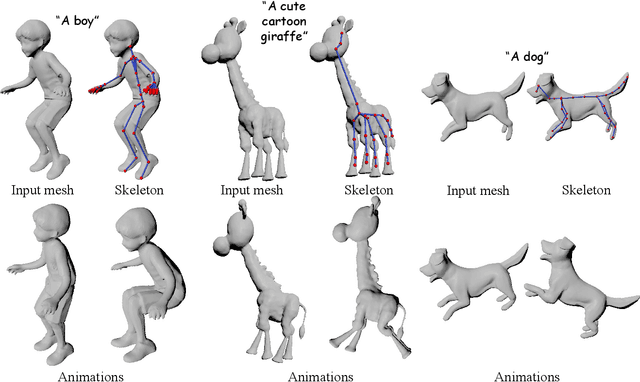
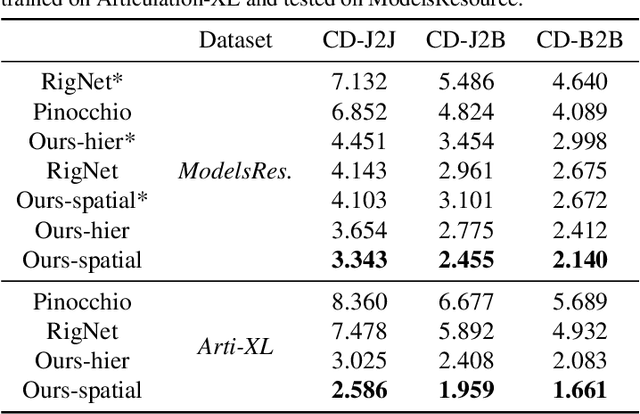
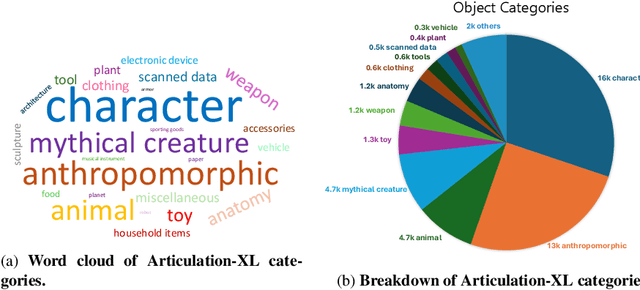
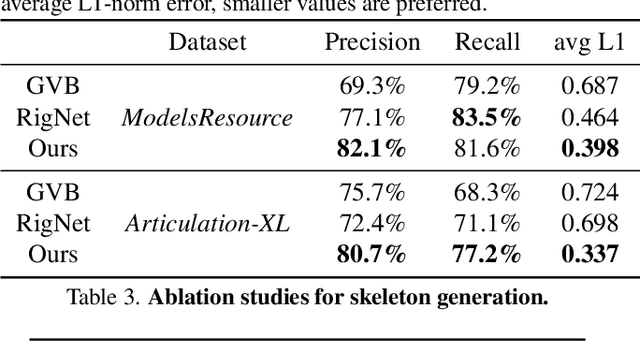
With the explosive growth of 3D content creation, there is an increasing demand for automatically converting static 3D models into articulation-ready versions that support realistic animation. Traditional approaches rely heavily on manual annotation, which is both time-consuming and labor-intensive. Moreover, the lack of large-scale benchmarks has hindered the development of learning-based solutions. In this work, we present MagicArticulate, an effective framework that automatically transforms static 3D models into articulation-ready assets. Our key contributions are threefold. First, we introduce Articulation-XL, a large-scale benchmark containing over 33k 3D models with high-quality articulation annotations, carefully curated from Objaverse-XL. Second, we propose a novel skeleton generation method that formulates the task as a sequence modeling problem, leveraging an auto-regressive transformer to naturally handle varying numbers of bones or joints within skeletons and their inherent dependencies across different 3D models. Third, we predict skinning weights using a functional diffusion process that incorporates volumetric geodesic distance priors between vertices and joints. Extensive experiments demonstrate that MagicArticulate significantly outperforms existing methods across diverse object categories, achieving high-quality articulation that enables realistic animation. Project page: https://chaoyuesong.github.io/MagicArticulate.
High Quality Human Image Animation using Regional Supervision and Motion Blur Condition
Sep 29, 2024



Recent advances in video diffusion models have enabled realistic and controllable human image animation with temporal coherence. Although generating reasonable results, existing methods often overlook the need for regional supervision in crucial areas such as the face and hands, and neglect the explicit modeling for motion blur, leading to unrealistic low-quality synthesis. To address these limitations, we first leverage regional supervision for detailed regions to enhance face and hand faithfulness. Second, we model the motion blur explicitly to further improve the appearance quality. Third, we explore novel training strategies for high-resolution human animation to improve the overall fidelity. Experimental results demonstrate that our proposed method outperforms state-of-the-art approaches, achieving significant improvements upon the strongest baseline by more than 21.0% and 57.4% in terms of reconstruction precision (L1) and perceptual quality (FVD) on HumanDance dataset. Code and model will be made available.
Empowering Visual Creativity: A Vision-Language Assistant to Image Editing Recommendations
May 31, 2024

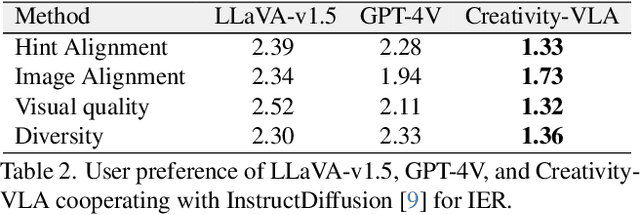

Advances in text-based image generation and editing have revolutionized content creation, enabling users to create impressive content from imaginative text prompts. However, existing methods are not designed to work well with the oversimplified prompts that are often encountered in typical scenarios when users start their editing with only vague or abstract purposes in mind. Those scenarios demand elaborate ideation efforts from the users to bridge the gap between such vague starting points and the detailed creative ideas needed to depict the desired results. In this paper, we introduce the task of Image Editing Recommendation (IER). This task aims to automatically generate diverse creative editing instructions from an input image and a simple prompt representing the users' under-specified editing purpose. To this end, we introduce Creativity-Vision Language Assistant~(Creativity-VLA), a multimodal framework designed specifically for edit-instruction generation. We train Creativity-VLA on our edit-instruction dataset specifically curated for IER. We further enhance our model with a novel 'token-for-localization' mechanism, enabling it to support both global and local editing operations. Our experimental results demonstrate the effectiveness of \ours{} in suggesting instructions that not only contain engaging creative elements but also maintain high relevance to both the input image and the user's initial hint.
DiG: Scalable and Efficient Diffusion Models with Gated Linear Attention
May 28, 2024



Diffusion models with large-scale pre-training have achieved significant success in the field of visual content generation, particularly exemplified by Diffusion Transformers (DiT). However, DiT models have faced challenges with scalability and quadratic complexity efficiency. In this paper, we aim to leverage the long sequence modeling capability of Gated Linear Attention (GLA) Transformers, expanding its applicability to diffusion models. We introduce Diffusion Gated Linear Attention Transformers (DiG), a simple, adoptable solution with minimal parameter overhead, following the DiT design, but offering superior efficiency and effectiveness. In addition to better performance than DiT, DiG-S/2 exhibits $2.5\times$ higher training speed than DiT-S/2 and saves $75.7\%$ GPU memory at a resolution of $1792 \times 1792$. Moreover, we analyze the scalability of DiG across a variety of computational complexity. DiG models, with increased depth/width or augmentation of input tokens, consistently exhibit decreasing FID. We further compare DiG with other subquadratic-time diffusion models. With the same model size, DiG-XL/2 is $4.2\times$ faster than the recent Mamba-based diffusion model at a $1024$ resolution, and is $1.8\times$ faster than DiT with CUDA-optimized FlashAttention-2 under the $2048$ resolution. All these results demonstrate its superior efficiency among the latest diffusion models. Code is released at https://github.com/hustvl/DiG.
ClassDiffusion: More Aligned Personalization Tuning with Explicit Class Guidance
May 27, 2024Recent text-to-image customization works have been proven successful in generating images of given concepts by fine-tuning the diffusion models on a few examples. However, these methods tend to overfit the concepts, resulting in failure to create the concept under multiple conditions (e.g. headphone is missing when generating a <sks> dog wearing a headphone'). Interestingly, we notice that the base model before fine-tuning exhibits the capability to compose the base concept with other elements (e.g. a dog wearing a headphone) implying that the compositional ability only disappears after personalization tuning. Inspired by this observation, we present ClassDiffusion, a simple technique that leverages a semantic preservation loss to explicitly regulate the concept space when learning the new concept. Despite its simplicity, this helps avoid semantic drift when fine-tuning on the target concepts. Extensive qualitative and quantitative experiments demonstrate that the use of semantic preservation loss effectively improves the compositional abilities of the fine-tune models. In response to the ineffective evaluation of CLIP-T metrics, we introduce BLIP2-T metric, a more equitable and effective evaluation metric for this particular domain. We also provide in-depth empirical study and theoretical analysis to better understand the role of the proposed loss. Lastly, we also extend our ClassDiffusion to personalized video generation, demonstrating its flexibility.