 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Dancer: Expressive Music to Human Dance Video Generation
Feb 24, 2025We present X-Dancer, a novel zero-shot music-driven image animation pipeline that creates diverse and long-range lifelike human dance videos from a single static image. As its core, we introduce a unified transformer-diffusion framework, featuring an autoregressive transformer model that synthesize extended and music-synchronized token sequences for 2D body, head and hands poses, which then guide a diffusion model to produce coherent and realistic dance video frames. Unlike traditional methods that primarily generate human motion in 3D, X-Dancer addresses data limitations and enhances scalability by modeling a wide spectrum of 2D dance motions, capturing their nuanced alignment with musical beats through readily available monocular videos. To achieve this, we first build a spatially compositional token representation from 2D human pose labels associated with keypoint confidences, encoding both large articulated body movements (e.g., upper and lower body) and fine-grained motions (e.g., head and hands). We then design a music-to-motion transformer model that autoregressively generates music-aligned dance pose token sequences, incorporating global attention to both musical style and prior motion context. Finally we leverage a diffusion backbone to animate the reference image with these synthesized pose tokens through AdaIN, forming a fully differentiable end-to-end framework. Experimental results demonstrate that X-Dancer is able to produce both diverse and characterized dance videos, substantially outperforming state-of-the-art methods in term of diversity, expressiveness and realism. Code and model will be available for research purposes.
X-Dyna: Expressive Dynamic Human Image Animation
Jan 20, 2025We introduce X-Dyna, a novel zero-shot, diffusion-based pipeline for animating a single human image using facial expressions and body movements derived from a driving video, that generates realistic, context-aware dynamics for both the subject and the surrounding environment. Building on prior approaches centered on human pose control, X-Dyna addresses key shortcomings causing the loss of dynamic details, enhancing the lifelike qualities of human video animations. At the core of our approach is the Dynamics-Adapter, a lightweight module that effectively integrates reference appearance context into the spatial attentions of the diffusion backbone while preserving the capacity of motion modules in synthesizing fluid and intricate dynamic details. Beyond body pose control, we connect a local control module with our model to capture identity-disentangled facial expressions, facilitating accurate expression transfer for enhanced realism in animated scenes. Together, these components form a unified framework capable of learning physical human motion and natural scene dynamics from a diverse blend of human and scene videos. Comprehensive qualitative and quantitative evaluations demonstrate that X-Dyna outperforms state-of-the-art methods, creating highly lifelike and expressive animations. The code is available at https://github.com/bytedance/X-Dyna.
High Quality Human Image Animation using Regional Supervision and Motion Blur Condition
Sep 29, 2024



Recent advances in video diffusion models have enabled realistic and controllable human image animation with temporal coherence. Although generating reasonable results, existing methods often overlook the need for regional supervision in crucial areas such as the face and hands, and neglect the explicit modeling for motion blur, leading to unrealistic low-quality synthesis. To address these limitations, we first leverage regional supervision for detailed regions to enhance face and hand faithfulness. Second, we model the motion blur explicitly to further improve the appearance quality. Third, we explore novel training strategies for high-resolution human animation to improve the overall fidelity. Experimental results demonstrate that our proposed method outperforms state-of-the-art approaches, achieving significant improvements upon the strongest baseline by more than 21.0% and 57.4% in terms of reconstruction precision (L1) and perceptual quality (FVD) on HumanDance dataset. Code and model will be made available.
X-Portrait: Expressive Portrait Animation with Hierarchical Motion Attention
Mar 27, 2024We propose X-Portrait, an innovative conditional diffusion model tailored for generating expressive and temporally coherent portrait animation. Specifically, given a single portrait as appearance reference, we aim to animate it with motion derived from a driving video, capturing both highly dynamic and subtle facial expressions along with wide-range head movements. As its core, we leverage the generative prior of a pre-trained diffusion model as the rendering backbone, while achieve fine-grained head pose and expression control with novel controlling signals within the framework of ControlNet. In contrast to conventional coarse explicit controls such as facial landmarks, our motion control module is learned to interpret the dynamics directly from the original driving RGB inputs. The motion accuracy is further enhanced with a patch-based local control module that effectively enhance the motion attention to small-scale nuances like eyeball positions. Notably, to mitigate the identity leakage from the driving signals, we train our motion control modules with scaling-augmented cross-identity images, ensuring maximized disentanglement from the appearance reference modules. Experimental results demonstrate the universal effectiveness of X-Portrait across a diverse range of facial portraits and expressive driving sequences, and showcase its proficiency in generating captivating portrait animations with consistently maintained identity characteristics.
DiffPortrait3D: Controllable Diffusion for Zero-Shot Portrait View Synthesis
Dec 22, 2023



We present DiffPortrait3D, a conditional diffusion model that is capable of synthesizing 3D-consistent photo-realistic novel views from as few as a single in-the-wild portrait. Specifically, given a single RGB input, we aim to synthesize plausible but consistent facial details rendered from novel camera views with retained both identity and facial expression. In lieu of time-consuming optimization and fine-tuning, our zero-shot method generalizes well to arbitrary face portraits with unposed camera views, extreme facial expressions, and diverse artistic depictions. At its core, we leverage the generative prior of 2D diffusion models pre-trained on large-scale image datasets as our rendering backbone, while the denoising is guided with disentangled attentive control of appearance and camera pose. To achieve this, we first inject the appearance context from the reference image into the self-attention layers of the frozen UNets. The rendering view is then manipulated with a novel conditional control module that interprets the camera pose by watching a condition image of a crossed subject from the same view. Furthermore, we insert a trainable cross-view attention module to enhance view consistency, which is further strengthened with a novel 3D-aware noise generation process during inference. We demonstrate state-of-the-art results both qualitatively and quantitatively on our challenging in-the-wild and multi-view benchmarks.
DREAM-Talk: Diffusion-based Realistic Emotional Audio-driven Method for Single Image Talking Face Generation
Dec 21, 2023



The generation of emotional talking faces from a single portrait image remains a significant challenge. The simultaneous achievement of expressive emotional talking and accurate lip-sync is particularly difficult, as expressiveness is often compromised for the accuracy of lip-sync. As widely adopted by many prior works, the LSTM network often fails to capture the subtleties and variations of emotional expressions. To address these challenges, we introduce DREAM-Talk, a two-stage diffusion-based audio-driven framework, tailored for generating diverse expressions and accurate lip-sync concurrently. In the first stage, we propose EmoDiff, a novel diffusion module that generates diverse highly dynamic emotional expressions and head poses in accordance with the audio and the referenced emotion style. Given the strong correlation between lip motion and audio, we then refine the dynamics with enhanced lip-sync accuracy using audio features and emotion style. To this end, we deploy a video-to-video rendering module to transfer the expressions and lip motions from our proxy 3D avatar to an arbitrary portrait. Both quantitatively and qualitatively, DREAM-Talk outperforms state-of-the-art methods in terms of expressiveness, lip-sync accuracy and perceptual quality.
UV-Based 3D Hand-Object Reconstruction with Grasp Optimization
Nov 24, 2022



We propose a novel framework for 3D hand shape reconstruction and hand-object grasp optimization from a single RGB image. The representation of hand-object contact regions is critical for accurate reconstructions. Instead of approximating the contact regions with sparse points, as in previous works, we propose a dense representation in the form of a UV coordinate map. Furthermore, we introduce inference-time optimization to fine-tune the grasp and improve interactions between the hand and the object. Our pipeline increases hand shape reconstruction accuracy and produces a vibrant hand texture. Experiments on datasets such as Ho3D, FreiHAND, and DexYCB reveal that our proposed method outperforms the state-of-the-art.
TemporalUV: Capturing Loose Clothing with Temporally Coherent UV Coordinates
Apr 07, 2022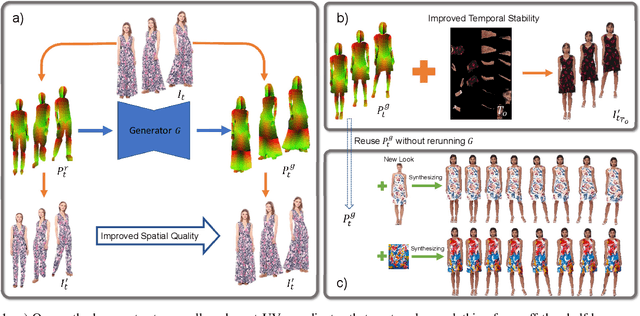

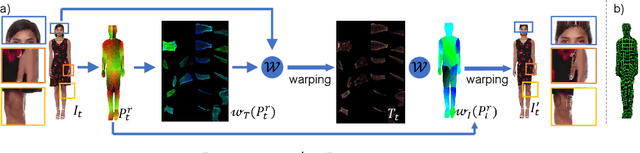
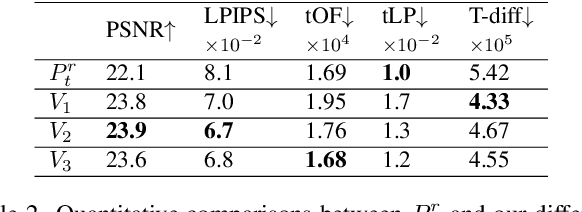
We propose a novel approach to generate temporally coherent UV coordinates for loose clothing. Our method is not constrained by human body outlines and can capture loose garments and hair. We implemented a differentiable pipeline to learn UV mapping between a sequence of RGB inputs and textures via UV coordinates. Instead of treating the UV coordinates of each frame separately, our data generation approach connects all UV coordinates via feature matching for temporal stability. Subsequently, a generative model is trained to balance the spatial quality and temporal stability. It is driven by supervised and unsupervised losses in both UV and image spaces. Our experiments show that the trained models output high-quality UV coordinates and generalize to new poses. Once a sequence of UV coordinates has been inferred by our model, it can be used to flexibly synthesize new looks and modified visual styles. Compared to existing methods, our approach reduces the computational workload to animate new outfits by several orders of magnitude.
Data-driven Regularization via Racecar Training for Generalizing Neural Networks
Jun 30, 2020

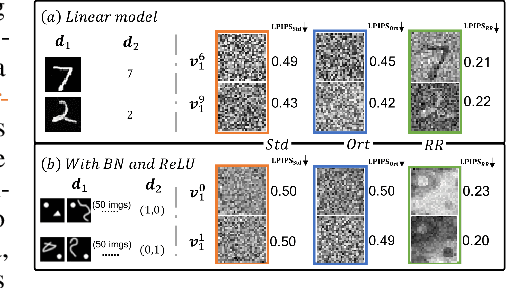

We propose a novel training approach for improving the generalization in neural networks. We show that in contrast to regular constraints for orthogonality, our approach represents a {\em data-dependent} orthogonality constraint, and is closely related to singular value decompositions of the weight matrices. We also show how our formulation is easy to realize in practical network architectures via a reverse pass, which aims for reconstructing the full sequence of internal states of the network. Despite being a surprisingly simple change, we demonstrate that this forward-backward training approach, which we refer to as {\em racecar} training, leads to significantly more generic features being extracted from a given data set. Networks trained with our approach show more balanced mutual information between input and output throughout all layers, yield improved explainability and, exhibit improved performance for a variety of tasks and task transfers.
A Multi-Pass GAN for Fluid Flow Super-Resolution
Jun 04, 2019
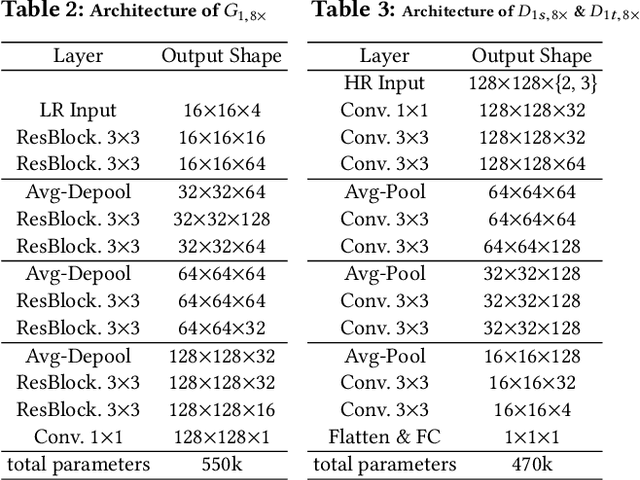
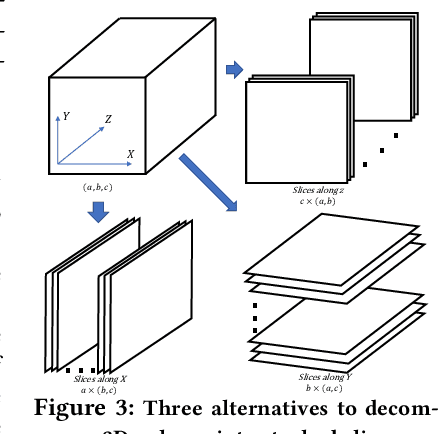
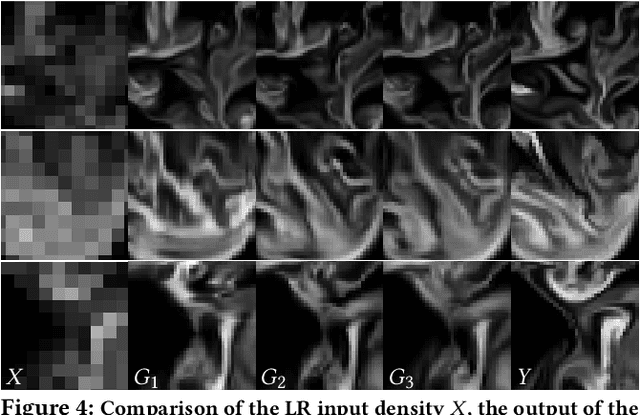
We propose a novel method to up-sample volumetric functions with generative neural networks using several orthogonal passes. Our method decomposes generative problems on Cartesian field functions into multiple smaller sub-problems that can be learned more efficiently. Specifically, we utilize two separate generative adversarial networks: the first one up-scales slices which are parallel to the XY-plane, whereas the second one refines the whole volume along the Z-axis working on slices in the YZ-plane. In this way, we obtain full coverage for the 3D target function and can leverage spatio-temporal supervision with a set of discriminators. Additionally, we demonstrate that our method can be combined with curriculum learning and progressive growing approaches. We arrive at a first method that can up-sample volumes by a factor of eight along each dimension, i.e., increasing the number of degrees of freedom by 512. Large volumetric up-scaling factors such as this one have previously not been attainable as the required number of weights in the neural networks renders adversarial training runs prohibitively difficult. We demonstrate the generality of our trained networks with a series of comparisons to previous work, a variety of complex 3D results, and an analysis of the resulting performance.