 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNL2Contact: Natural Language Guided 3D Hand-Object Contact Modeling with Diffusion Model
Jul 17, 2024Modeling the physical contacts between the hand and object is standard for refining inaccurate hand poses and generating novel human grasp in 3D hand-object reconstruction. However, existing methods rely on geometric constraints that cannot be specified or controlled. This paper introduces a novel task of controllable 3D hand-object contact modeling with natural language descriptions. Challenges include i) the complexity of cross-modal modeling from language to contact, and ii) a lack of descriptive text for contact patterns. To address these issues, we propose NL2Contact, a model that generates controllable contacts by leveraging staged diffusion models. Given a language description of the hand and contact, NL2Contact generates realistic and faithful 3D hand-object contacts. To train the model, we build \textit{ContactDescribe}, the first dataset with hand-centered contact descriptions. It contains multi-level and diverse descriptions generated by large language models based on carefully designed prompts (e.g., grasp action, grasp type, contact location, free finger status). We show applications of our model to grasp pose optimization and novel human grasp generation, both based on a textual contact description.
Overcoming the Trade-off Between Accuracy and Plausibility in 3D Hand Shape Reconstruction
May 01, 2023



Direct mesh fitting for 3D hand shape reconstruction is highly accurate. However, the reconstructed meshes are prone to artifacts and do not appear as plausible hand shapes. Conversely, parametric models like MANO ensure plausible hand shapes but are not as accurate as the non-parametric methods. In this work, we introduce a novel weakly-supervised hand shape estimation framework that integrates non-parametric mesh fitting with MANO model in an end-to-end fashion. Our joint model overcomes the tradeoff in accuracy and plausibility to yield well-aligned and high-quality 3D meshes, especially in challenging two-hand and hand-object interaction scenarios.
An Implicit Alignment for Video Super-Resolution
Apr 29, 2023

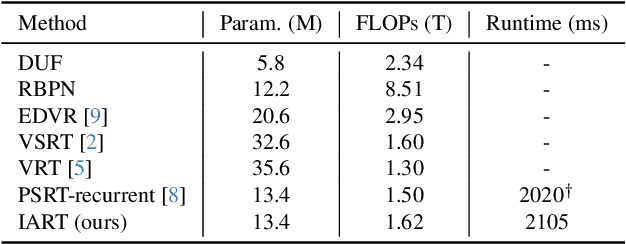

Video super-resolution commonly uses a frame-wise alignment to support the propagation of information over time. The role of alignment is well-studied for low-level enhancement in video, but existing works have overlooked one critical step -- re-sampling. Most works, regardless of how they compensate for motion between frames, be it flow-based warping or deformable convolution/attention, use the default choice of bilinear interpolation for re-sampling. However, bilinear interpolation acts effectively as a low-pass filter and thus hinders the aim of recovering high-frequency content for super-resolution. This paper studies the impact of re-sampling on alignment for video super-resolution. Extensive experiments reveal that for alignment to be effective, the re-sampling should preserve the original sharpness of the features and prevent distortions. From these observations, we propose an implicit alignment method that re-samples through a window-based cross-attention with sampling positions encoded by sinusoidal positional encoding. The re-sampling is implicitly computed by learned network weights. Experiments show that the proposed implicit alignment enhances the performance of state-of-the-art frameworks with minimal impact on both synthetic and real-world datasets.
UV-Based 3D Hand-Object Reconstruction with Grasp Optimization
Nov 24, 2022



We propose a novel framework for 3D hand shape reconstruction and hand-object grasp optimization from a single RGB image. The representation of hand-object contact regions is critical for accurate reconstructions. Instead of approximating the contact regions with sparse points, as in previous works, we propose a dense representation in the form of a UV coordinate map. Furthermore, we introduce inference-time optimization to fine-tune the grasp and improve interactions between the hand and the object. Our pipeline increases hand shape reconstruction accuracy and produces a vibrant hand texture. Experiments on datasets such as Ho3D, FreiHAND, and DexYCB reveal that our proposed method outperforms the state-of-the-art.
Local and Global Point Cloud Reconstruction for 3D Hand Pose Estimation
Dec 13, 2021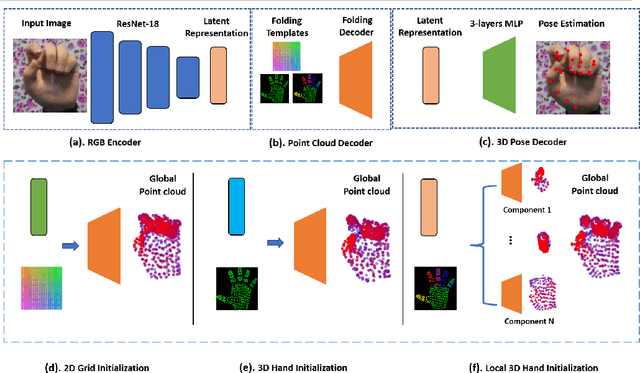
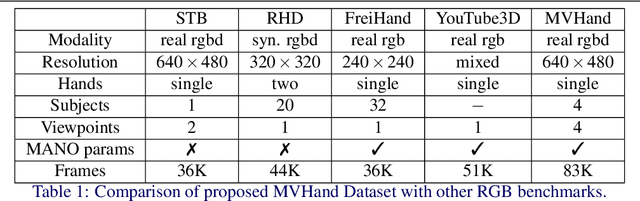
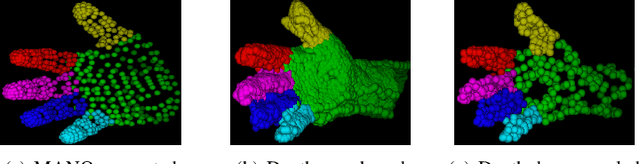
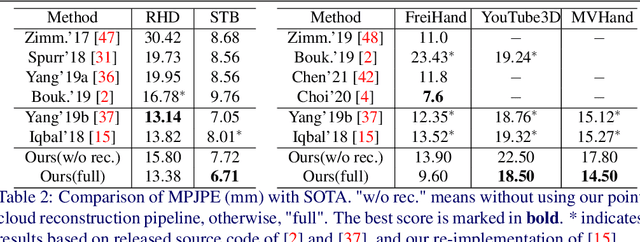
This paper addresses the 3D point cloud reconstruction and 3D pose estimation of the human hand from a single RGB image. To that end, we present a novel pipeline for local and global point cloud reconstruction using a 3D hand template while learning a latent representation for pose estimation. To demonstrate our method, we introduce a new multi-view hand posture dataset to obtain complete 3D point clouds of the hand in the real world. Experiments on our newly proposed dataset and four public benchmarks demonstrate the model's strengths. Our method outperforms competitors in 3D pose estimation while reconstructing realistic-looking complete 3D hand point clouds.
Scalable Gaussian Process Classification with Additive Noise for Various Likelihoods
Sep 14, 2019
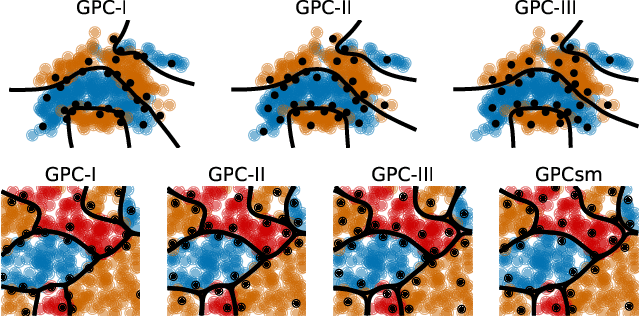
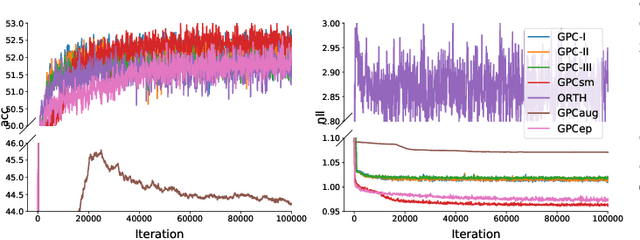
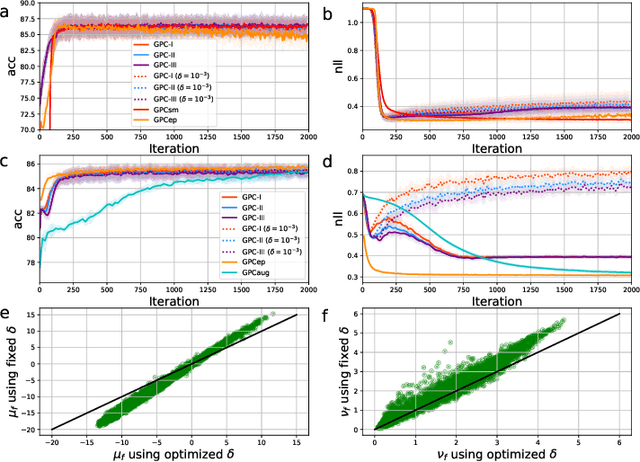
Gaussian process classification (GPC) provides a flexible and powerful statistical framework describing joint distributions over function space. Conventional GPCs however suffer from (i) poor scalability for big data due to the full kernel matrix, and (ii) intractable inference due to the non-Gaussian likelihoods. Hence, various scalable GPCs have been proposed through (i) the sparse approximation built upon a small inducing set to reduce the time complexity; and (ii) the approximate inference to derive analytical evidence lower bound (ELBO). However, these scalable GPCs equipped with analytical ELBO are limited to specific likelihoods or additional assumptions. In this work, we present a unifying framework which accommodates scalable GPCs using various likelihoods. Analogous to GP regression (GPR), we introduce additive noises to augment the probability space for (i) the GPCs with step, (multinomial) probit and logit likelihoods via the internal variables; and particularly, (ii) the GPC using softmax likelihood via the noise variables themselves. This leads to unified scalable GPCs with analytical ELBO by using variational inference. Empirically, our GPCs showcase better results than state-of-the-art scalable GPCs for extensive binary/multi-class classification tasks with up to two million data points.