 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Implicit Alignment for Video Super-Resolution
Paper and Code


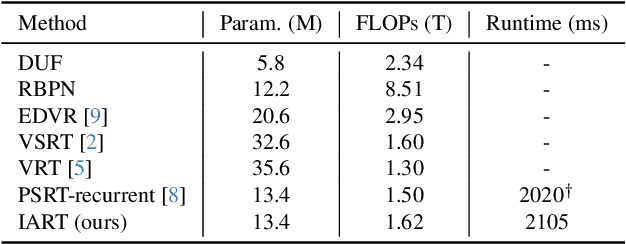

Video super-resolution commonly uses a frame-wise alignment to support the propagation of information over time. The role of alignment is well-studied for low-level enhancement in video, but existing works have overlooked one critical step -- re-sampling. Most works, regardless of how they compensate for motion between frames, be it flow-based warping or deformable convolution/attention, use the default choice of bilinear interpolation for re-sampling. However, bilinear interpolation acts effectively as a low-pass filter and thus hinders the aim of recovering high-frequency content for super-resolution. This paper studies the impact of re-sampling on alignment for video super-resolution. Extensive experiments reveal that for alignment to be effective, the re-sampling should preserve the original sharpness of the features and prevent distortions. From these observations, we propose an implicit alignment method that re-samples through a window-based cross-attention with sampling positions encoded by sinusoidal positional encoding. The re-sampling is implicitly computed by learned network weights. Experiments show that the proposed implicit alignment enhances the performance of state-of-the-art frameworks with minimal impact on both synthetic and real-world datasets.