 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Emerging Trends of Multi-Label Learning
Dec 02, 2020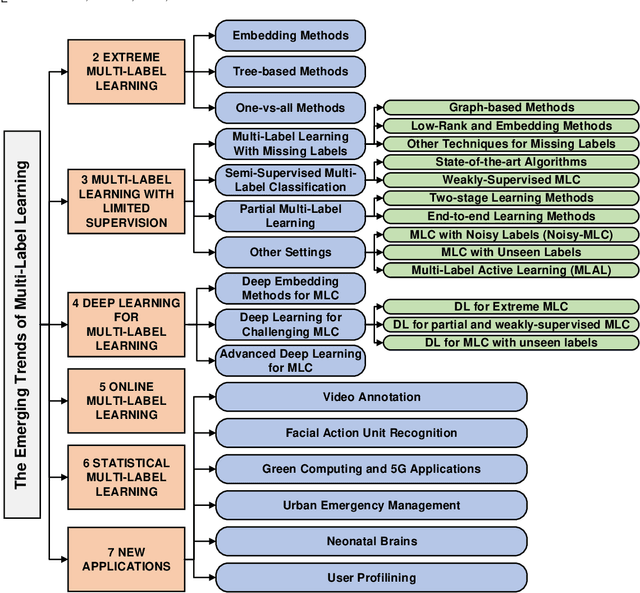
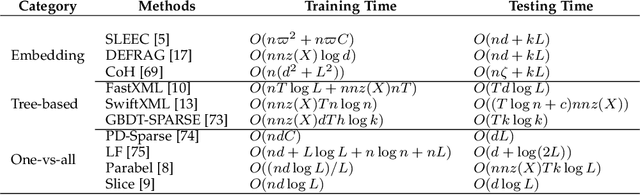


Exabytes of data are generated daily by humans, leading to the growing need for new efforts in dealing with the grand challenges for multi-label learning brought by big data. For example, extreme multi-label classification is an active and rapidly growing research area that deals with classification tasks with an extremely large number of classes or labels; utilizing massive data with limited supervision to build a multi-label classification model becomes valuable for practical applications, etc. Besides these, there are tremendous efforts on how to harvest the strong learning capability of deep learning to better capture the label dependencies in multi-label learning, which is the key for deep learning to address real-world classification tasks. However, it is noted that there has been a lack of systemic studies that focus explicitly on analyzing the emerging trends and new challenges of multi-label learning in the era of big data. It is imperative to call for a comprehensive survey to fulfill this mission and delineate future research directions and new applications.
Scalable Gaussian Process Classification with Additive Noise for Various Likelihoods
Sep 14, 2019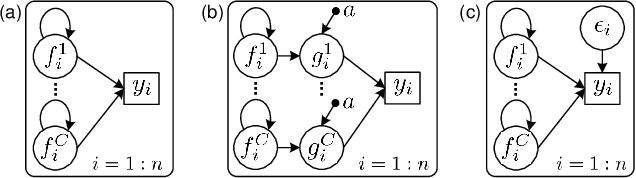
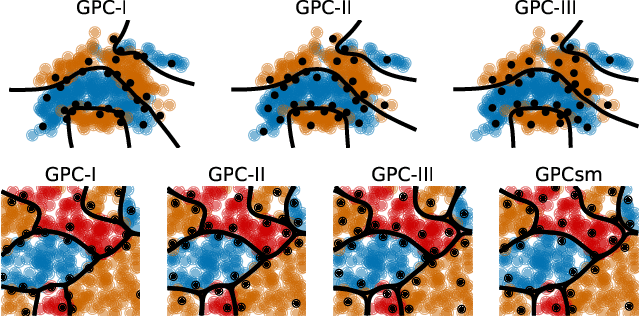
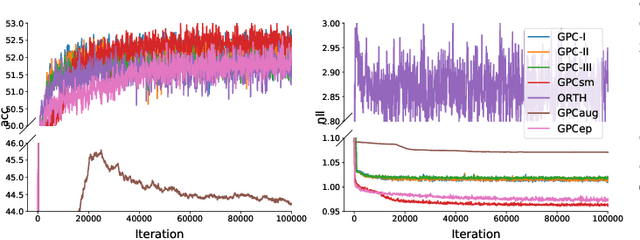
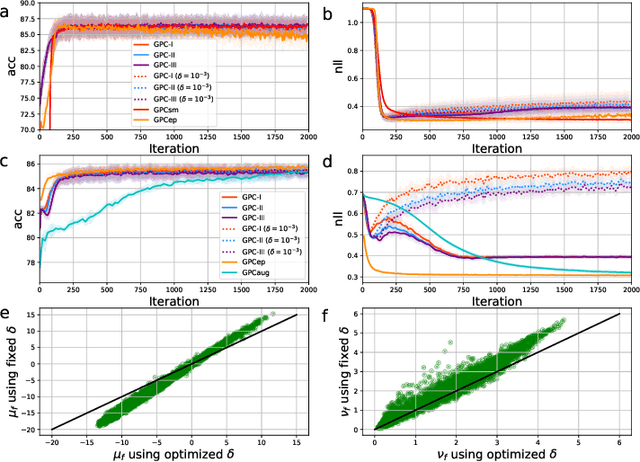
Gaussian process classification (GPC) provides a flexible and powerful statistical framework describing joint distributions over function space. Conventional GPCs however suffer from (i) poor scalability for big data due to the full kernel matrix, and (ii) intractable inference due to the non-Gaussian likelihoods. Hence, various scalable GPCs have been proposed through (i) the sparse approximation built upon a small inducing set to reduce the time complexity; and (ii) the approximate inference to derive analytical evidence lower bound (ELBO). However, these scalable GPCs equipped with analytical ELBO are limited to specific likelihoods or additional assumptions. In this work, we present a unifying framework which accommodates scalable GPCs using various likelihoods. Analogous to GP regression (GPR), we introduce additive noises to augment the probability space for (i) the GPCs with step, (multinomial) probit and logit likelihoods via the internal variables; and particularly, (ii) the GPC using softmax likelihood via the noise variables themselves. This leads to unified scalable GPCs with analytical ELBO by using variational inference. Empirically, our GPCs showcase better results than state-of-the-art scalable GPCs for extensive binary/multi-class classification tasks with up to two million data points.
A Survey on Multi-output Learning
Jan 02, 2019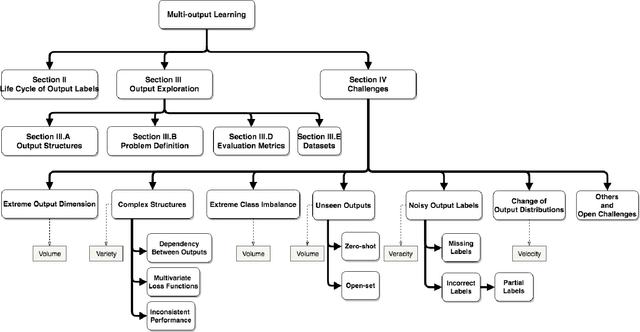
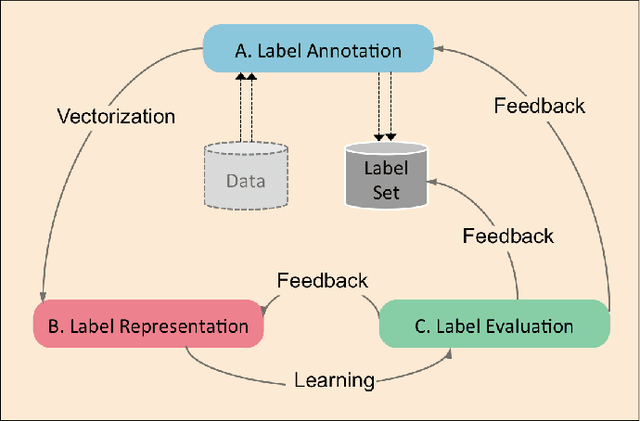
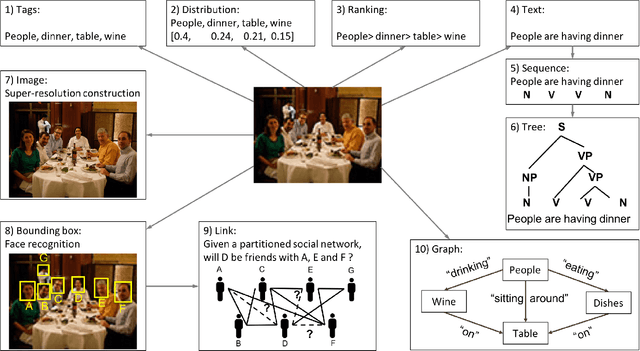
Multi-output learning aims to simultaneously predict multiple outputs given an input. It is an important learning problem due to the pressing need for sophisticated decision making in real-world applications. Inspired by big data, the 4Vs characteristics of multi-output imposes a set of challenges to multi-output learning, in terms of the volume, velocity, variety and veracity of the outputs. Increasing number of works in the literature have been devoted to the study of multi-output learning and the development of novel approaches for addressing the challenges encountered. However, it lacks a comprehensive overview on different types of challenges of multi-output learning brought by the characteristics of the multiple outputs and the techniques proposed to overcome the challenges. This paper thus attempts to fill in this gap to provide a comprehensive review on this area. We first introduce different stages of the life cycle of the output labels. Then we present the paradigm on multi-output learning, including its myriads of output structures, definitions of its different sub-problems, model evaluation metrics and popular data repositories used in the study. Subsequently, we review a number of state-of-the-art multi-output learning methods, which are categorized based on the challenges.
When Gaussian Process Meets Big Data: A Review of Scalable GPs
Jul 03, 2018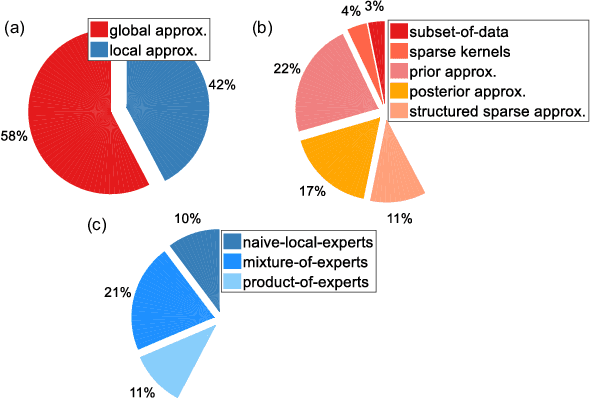
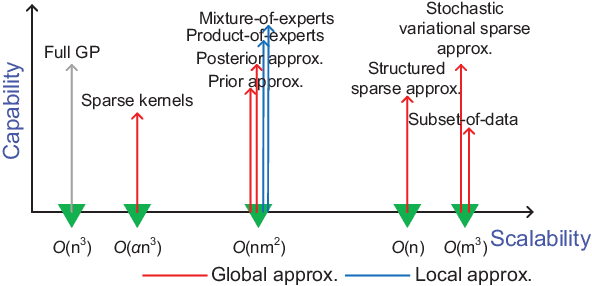
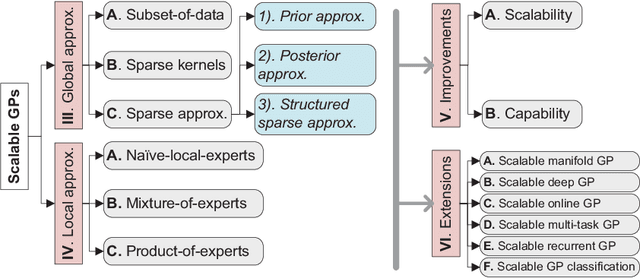
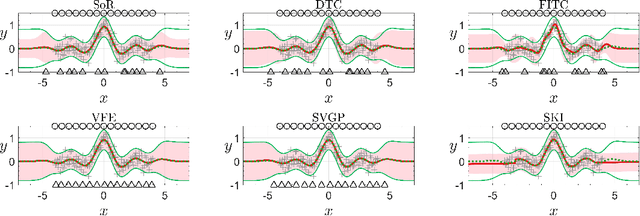
The vast quantity of information brought by big data as well as the evolving computer hardware encourages success stories in the machine learning community. In the meanwhile, it poses challenges for the Gaussian process (GP), a well-known non-parametric and interpretable Bayesian model, which suffers from cubic complexity to training size. To improve the scalability while retaining the desirable prediction quality, a variety of scalable GPs have been presented. But they have not yet been comprehensively reviewed and discussed in a unifying way in order to be well understood by both academia and industry. To this end, this paper devotes to reviewing state-of-the-art scalable GPs involving two main categories: global approximations which distillate the entire data and local approximations which divide the data for subspace learning. Particularly, for global approximations, we mainly focus on sparse approximations comprising prior approximations which modify the prior but perform exact inference, and posterior approximations which retain exact prior but perform approximate inference; for local approximations, we highlight the mixture/product of experts that conducts model averaging from multiple local experts to boost predictions. To present a complete review, recent advances for improving the scalability and model capability of scalable GPs are reviewed. Finally, the extensions and open issues regarding the implementation of scalable GPs in various scenarios are reviewed and discussed to inspire novel ideas for future research avenues.