 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncover and Unlearn Nuisances: Agnostic Fully Test-Time Adaptation
Nov 16, 2025Fully Test-Time Adaptation (FTTA) addresses domain shifts without access to source data and training protocols of the pre-trained models. Traditional strategies that align source and target feature distributions are infeasible in FTTA due to the absence of training data and unpredictable target domains. In this work, we exploit a dual perspective on FTTA, and propose Agnostic FTTA (AFTTA) as a novel formulation that enables the usage of off-the-shelf domain transformations during test-time to enable direct generalization to unforeseeable target data. To address this, we develop an uncover-and-unlearn approach. First, we uncover potential unwanted shifts between source and target domains by simulating them through predefined mappings and consider them as nuisances. Then, during test-time prediction, the model is enforced to unlearn these nuisances by regularizing the consequent shifts in latent representations and label predictions. Specifically, a mutual information-based criterion is devised and applied to guide nuisances unlearning in the feature space and encourage confident and consistent prediction in label space. Our proposed approach explicitly addresses agnostic domain shifts, enabling superior model generalization under FTTA constraints. Extensive experiments on various tasks, involving corruption and style shifts, demonstrate that our method consistently outperforms existing approaches.
* 26 pages, 4 figures
UTSGAN: Unseen Transition Suss GAN for Transition-Aware Image-to-image Translation
Apr 24, 2023



In the field of Image-to-Image (I2I) translation, ensuring consistency between input images and their translated results is a key requirement for producing high-quality and desirable outputs. Previous I2I methods have relied on result consistency, which enforces consistency between the translated results and the ground truth output, to achieve this goal. However, result consistency is limited in its ability to handle complex and unseen attribute changes in translation tasks. To address this issue, we introduce a transition-aware approach to I2I translation, where the data translation mapping is explicitly parameterized with a transition variable, allowing for the modelling of unobserved translations triggered by unseen transitions. Furthermore, we propose the use of transition consistency, defined on the transition variable, to enable regularization of consistency on unobserved translations, which is omitted in previous works. Based on these insights, we present Unseen Transition Suss GAN (UTSGAN), a generative framework that constructs a manifold for the transition with a stochastic transition encoder and coherently regularizes and generalizes result consistency and transition consistency on both training and unobserved translations with tailor-designed constraints. Extensive experiments on four different I2I tasks performed on five different datasets demonstrate the efficacy of our proposed UTSGAN in performing consistent translations.
Generative Transition Mechanism to Image-to-Image Translation via Encoded Transformation
Mar 09, 2021

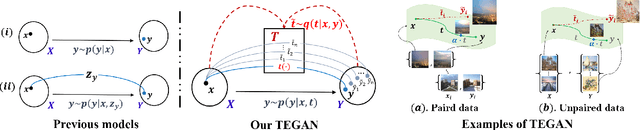
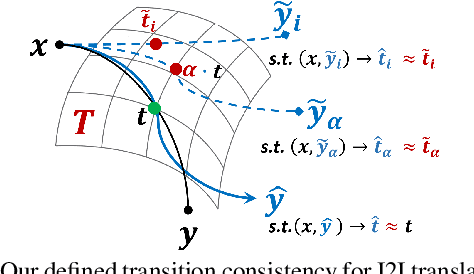
In this paper, we revisit the Image-to-Image (I2I) translation problem with transition consistency, namely the consistency defined on the conditional data mapping between each data pairs. Explicitly parameterizing each data mappings with a transition variable $t$, i.e., $x \overset{t(x,y)}{\mapsto}y$, we discover that existing I2I translation models mainly focus on maintaining consistency on results, e.g., image reconstruction or attribute prediction, named result consistency in our paper. This restricts their generalization ability to generate satisfactory results with unseen transitions in the test phase. Consequently, we propose to enforce both result consistency and transition consistency for I2I translation, to benefit the problem with a closer consistency between the input and output. To benefit the generalization ability of the translation model, we propose transition encoding to facilitate explicit regularization of these two {kinds} of consistencies on unseen transitions. We further generalize such explicitly regularized consistencies to distribution-level, thus facilitating a generalized overall consistency for I2I translation problems. With the above design, our proposed model, named Transition Encoding GAN (TEGAN), can poss superb generalization ability to generate realistic and semantically consistent translation results with unseen transitions in the test phase. It also provides a unified understanding of the existing GAN-based I2I transition models with our explicitly modeling of the data mapping, i.e., transition. Experiments on four different I2I translation tasks demonstrate the efficacy and generality of TEGAN.
Multi-view Alignment and Generation in CCA via Consistent Latent Encoding
May 24, 2020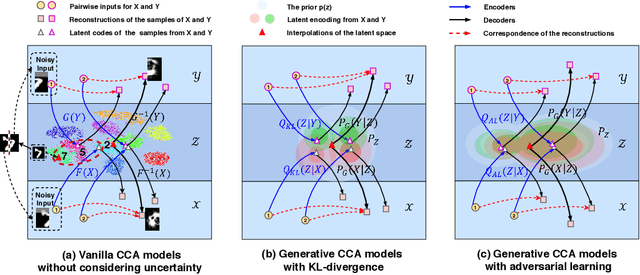
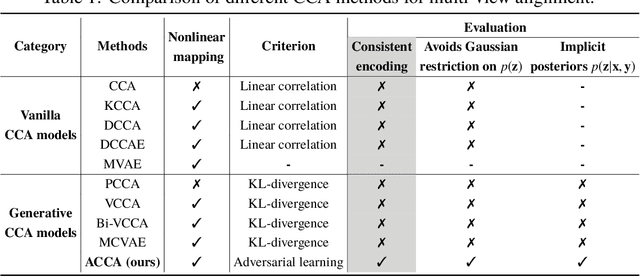
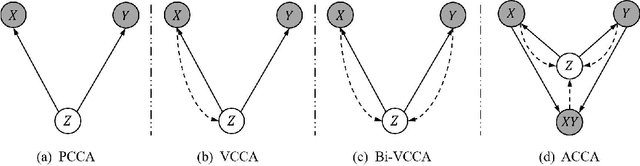
Multi-view alignment, achieving one-to-one correspondence of multi-view inputs, is critical in many real-world multi-view applications, especially for cross-view data analysis problems. Recently, an increasing number of works study this alignment problem with Canonical Correlation Analysis (CCA). However, existing CCA models are prone to misalign the multiple views due to either the neglect of uncertainty or the inconsistent encoding of the multiple views. To tackle these two issues, this paper studies multi-view alignment from the Bayesian perspective. Delving into the impairments of inconsistent encodings, we propose to recover correspondence of the multi-view inputs by matching the marginalization of the joint distribution of multi-view random variables under different forms of factorization. To realize our design, we present Adversarial CCA (ACCA) which achieves consistent latent encodings by matching the marginalized latent encodings through the adversarial training paradigm. Our analysis based on conditional mutual information reveals that ACCA is flexible for handling implicit distributions. Extensive experiments on correlation analysis and cross-view generation under noisy input settings demonstrate the superiority of our model.
Probabilistic CCA with Implicit Distributions
Jul 04, 2019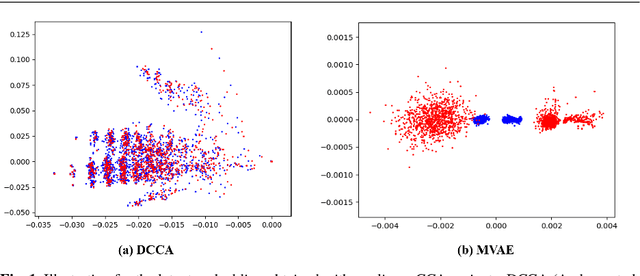
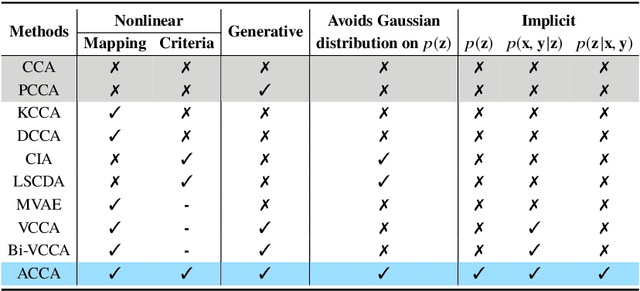
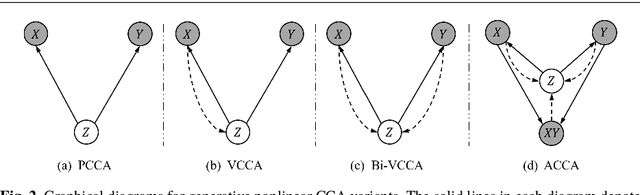
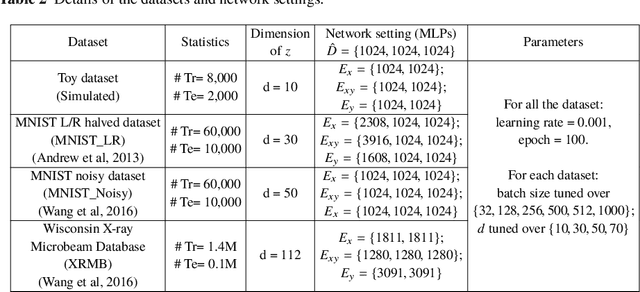
Canonical Correlation Analysis (CCA) is a classic technique for multi-view data analysis. To overcome the deficiency of linear correlation in practical multi-view learning tasks, various CCA variants were proposed to capture nonlinear dependency. However, it is non-trivial to have an in-principle understanding of these variants due to their inherent restrictive assumption on the data and latent code distributions. Although some works have studied probabilistic interpretation for CCA, these models still require the explicit form of the distributions to achieve a tractable solution for the inference. In this work, we study probabilistic interpretation for CCA based on implicit distributions. We present Conditional Mutual Information (CMI) as a new criterion for CCA to consider both linear and nonlinear dependency for arbitrarily distributed data. To eliminate direct estimation for CMI, in which explicit form of the distributions is still required, we derive an objective which can provide an estimation for CMI with efficient inference methods. To facilitate Bayesian inference of multi-view analysis, we propose Adversarial CCA (ACCA), which achieves consistent encoding for multi-view data with the consistent constraint imposed on the marginalization of the implicit posteriors. Such a model would achieve superiority in the alignment of the multi-view data with implicit distributions. It is interesting to note that most of the existing CCA variants can be connected with our proposed CCA model by assigning specific form for the posterior and likelihood distributions. Extensive experiments on nonlinear correlation analysis and cross-view generation on benchmark and real-world datasets demonstrate the superiority of our model.
A Survey on Multi-output Learning
Jan 02, 2019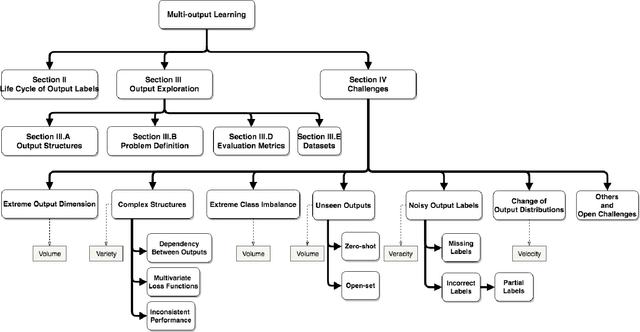
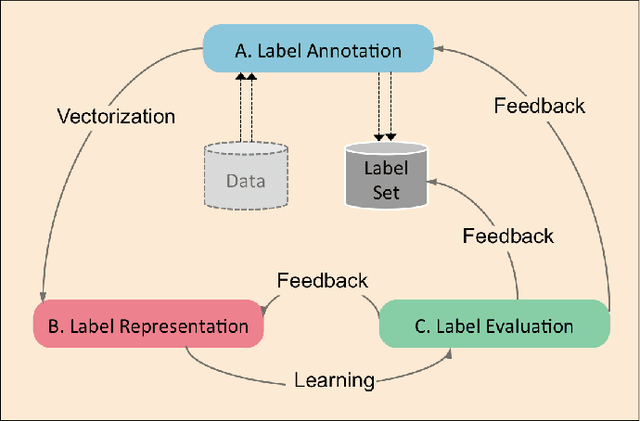
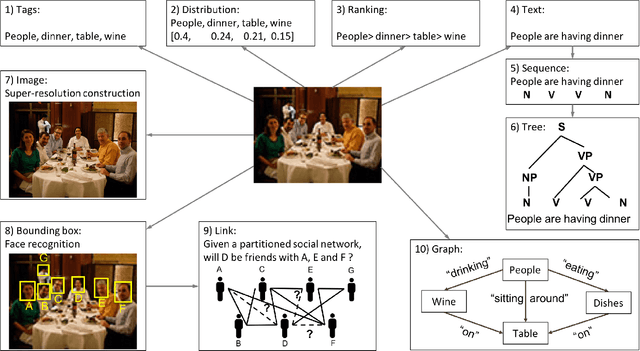
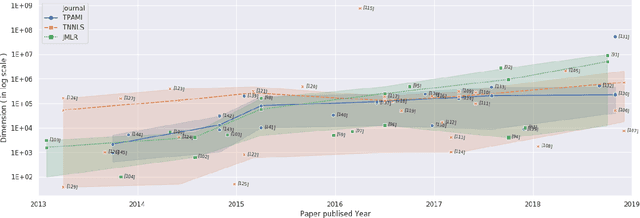
Multi-output learning aims to simultaneously predict multiple outputs given an input. It is an important learning problem due to the pressing need for sophisticated decision making in real-world applications. Inspired by big data, the 4Vs characteristics of multi-output imposes a set of challenges to multi-output learning, in terms of the volume, velocity, variety and veracity of the outputs. Increasing number of works in the literature have been devoted to the study of multi-output learning and the development of novel approaches for addressing the challenges encountered. However, it lacks a comprehensive overview on different types of challenges of multi-output learning brought by the characteristics of the multiple outputs and the techniques proposed to overcome the challenges. This paper thus attempts to fill in this gap to provide a comprehensive review on this area. We first introduce different stages of the life cycle of the output labels. Then we present the paradigm on multi-output learning, including its myriads of output structures, definitions of its different sub-problems, model evaluation metrics and popular data repositories used in the study. Subsequently, we review a number of state-of-the-art multi-output learning methods, which are categorized based on the challenges.
Multi-Context Label Embedding
May 03, 2018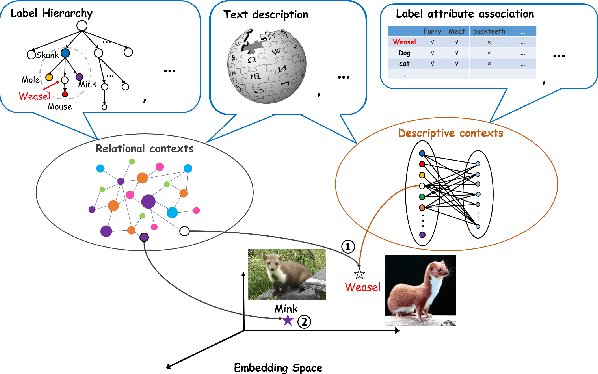
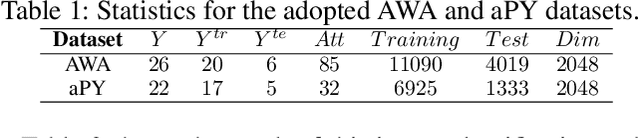
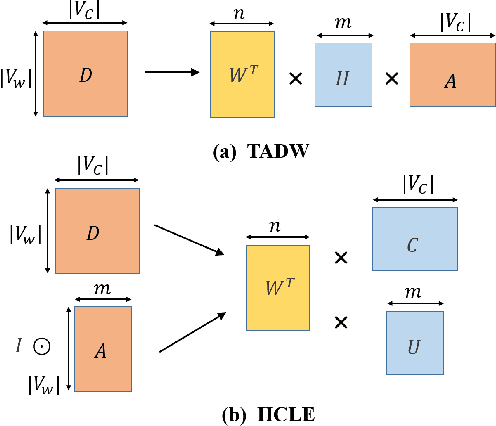
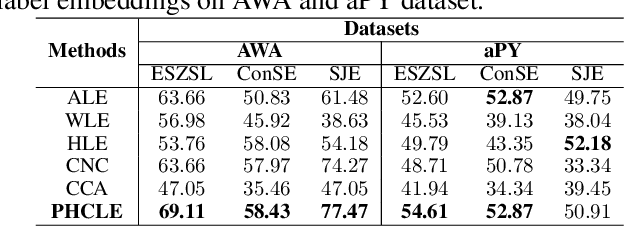
Label embedding plays an important role in zero-shot learning. Side information such as attributes, semantic text representations, and label hierarchy are commonly used as the label embedding in zero-shot classification tasks. However, the label embedding used in former works considers either only one single context of the label, or multiple contexts without dependency. Therefore, different contexts of the label may not be well aligned in the embedding space to preserve the relatedness between labels, which will result in poor interpretability of the label embedding. In this paper, we propose a Multi-Context Label Embedding (MCLE) approach to incorporate multiple label contexts, e.g., label hierarchy and attributes, within a unified matrix factorization framework. To be specific, we model each single context by a matrix factorization formula and introduce a shared variable to capture the dependency among different contexts. Furthermore, we enforce sparsity constraint on our multi-context framework to strengthen the interpretability of the learned label embedding. Extensive experiments on two real-world datasets demonstrate the superiority of our MCLE in label description and zero-shot image classification.