 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Gaussian Process Meets Big Data: A Review of Scalable GPs
Paper and Code
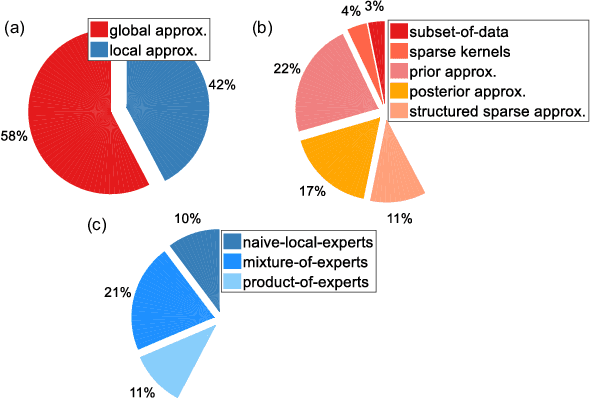
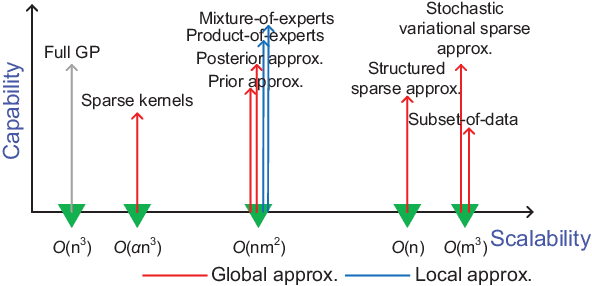
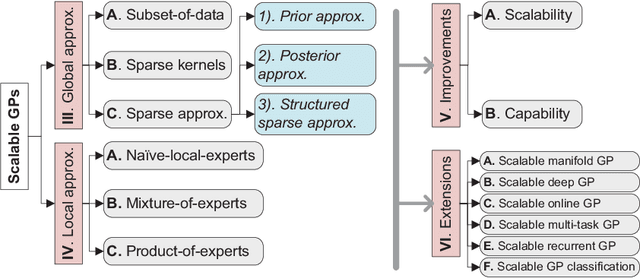
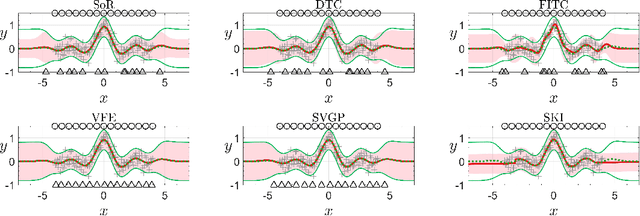
The vast quantity of information brought by big data as well as the evolving computer hardware encourages success stories in the machine learning community. In the meanwhile, it poses challenges for the Gaussian process (GP), a well-known non-parametric and interpretable Bayesian model, which suffers from cubic complexity to training size. To improve the scalability while retaining the desirable prediction quality, a variety of scalable GPs have been presented. But they have not yet been comprehensively reviewed and discussed in a unifying way in order to be well understood by both academia and industry. To this end, this paper devotes to reviewing state-of-the-art scalable GPs involving two main categories: global approximations which distillate the entire data and local approximations which divide the data for subspace learning. Particularly, for global approximations, we mainly focus on sparse approximations comprising prior approximations which modify the prior but perform exact inference, and posterior approximations which retain exact prior but perform approximate inference; for local approximations, we highlight the mixture/product of experts that conducts model averaging from multiple local experts to boost predictions. To present a complete review, recent advances for improving the scalability and model capability of scalable GPs are reviewed. Finally, the extensions and open issues regarding the implementation of scalable GPs in various scenarios are reviewed and discussed to inspire novel ideas for future research avenues.