 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Multi-sensor Conditioning for Street-view Novel-view Synthesis
Jun 01, 2026Modern vehicle platforms are equipped with a rich sensor suite, including LiDAR, calibrated multi-camera rigs, and accurate ego-motion, that in principle offers strong signal for re-rendering a driving scene from novel viewpoints. A growing line of recent work leverages video diffusion models for this task, using their generative priors to synthesize plausible novel views from sparse vehicle observations. In practice, however, existing methods exploit only a fragment of this signal, and their quality tends to degrade as the target trajectory departs from the recorded driving path. We argue that this is fundamentally a multi-sensor fusion problem: sparse LiDAR reprojections supply accurate but incomplete metric geometry, surround-view reference imagery supplies dense appearance but no metric depth, and camera poses tie the two together across views. We introduce StreetNVS, a video diffusion framework that jointly conditions on all three signals through a Reference-Enhanced Camera Attention module based on a relative ray-level positional encoding. We develop a two-stage curriculum training strategy that gradually exposes the model to increasingly sparse LiDAR. On the Waymo Open Dataset, StreetNVS substantially outperforms state-of-the-art baselines under sparse LiDAR conditioning, matches methods that rely on 10-100 times denser point clouds. We further show capabilities of synthesizing coherent videos along extreme out-of-trajectory paths such as elevation, lane-shift, pullback, and rotation. Our website: https://streetnvs.github.io
GeoFlow: Enforcing Implicit Geometric Consistency in Video Generation
May 18, 2026Generating geometrically consistent videos remains an open challenge: text-to-video diffusion models trained on web-scale data treat geometry only implicitly, leading to object deformation, texture drift, and non-rigid backgrounds under camera motion. Existing solutions either improve consistency as a byproduct, apply only to static scenes or realign the latent space of the model completely. We introduce a geometry-consistency reward that directly measures whether motion in a generated video is compatible with a coherent scene. Our key insight is that in physically consistent videos, background motion should be explainable by rigid camera-induced flow, while independently moving objects should preserve appearance identity along motion trajectories. We operationalize this using optical flow, depth--pose predictions, and feature-based correspondence to separate rigid and dynamic regions and evaluate their respective consistency. Integrating this reward with reinforcement fine-tuning transforms geometric consistency from an emergent property into an explicit optimization objective for video generators. The approach is model agnostic and applies to diverse dynamic scenes containing both camera and object motion. Experiments show substantial reductions in temporal geometric artifacts over strong baselines while preserving perceptual quality. Code and model weights are published.
Mode Seeking meets Mean Seeking for Fast Long Video Generation
Feb 27, 2026Scaling video generation from seconds to minutes faces a critical bottleneck: while short-video data is abundant and high-fidelity, coherent long-form data is scarce and limited to narrow domains. To address this, we propose a training paradigm where Mode Seeking meets Mean Seeking, decoupling local fidelity from long-term coherence based on a unified representation via a Decoupled Diffusion Transformer. Our approach utilizes a global Flow Matching head trained via supervised learning on long videos to capture narrative structure, while simultaneously employing a local Distribution Matching head that aligns sliding windows to a frozen short-video teacher via a mode-seeking reverse-KL divergence. This strategy enables the synthesis of minute-scale videos that learns long-range coherence and motions from limited long videos via supervised flow matching, while inheriting local realism by aligning every sliding-window segment of the student to a frozen short-video teacher, resulting in a few-step fast long video generator. Evaluations show that our method effectively closes the fidelity-horizon gap by jointly improving local sharpness, motion and long-range consistency. Project website: https://primecai.github.io/mmm/.
Pretraining Frame Preservation in Autoregressive Video Memory Compression
Dec 29, 2025We present PFP, a neural network structure to compress long videos into short contexts, with an explicit pretraining objective to preserve the high-frequency details of single frames at arbitrary temporal positions. The baseline model can compress a 20-second video into a context at about 5k length, where random frames can be retrieved with perceptually preserved appearances. Such pretrained models can be directly fine-tuned as memory encoders for autoregressive video models, enabling long history memory with low context cost and relatively low fidelity loss. We evaluate the framework with ablative settings and discuss the trade-offs of possible neural architecture designs.
Mixture of Contexts for Long Video Generation
Aug 28, 2025Long video generation is fundamentally a long context memory problem: models must retain and retrieve salient events across a long range without collapsing or drifting. However, scaling diffusion transformers to generate long-context videos is fundamentally limited by the quadratic cost of self-attention, which makes memory and computation intractable and difficult to optimize for long sequences. We recast long-context video generation as an internal information retrieval task and propose a simple, learnable sparse attention routing module, Mixture of Contexts (MoC), as an effective long-term memory retrieval engine. In MoC, each query dynamically selects a few informative chunks plus mandatory anchors (caption, local windows) to attend to, with causal routing that prevents loop closures. As we scale the data and gradually sparsify the routing, the model allocates compute to salient history, preserving identities, actions, and scenes over minutes of content. Efficiency follows as a byproduct of retrieval (near-linear scaling), which enables practical training and synthesis, and the emergence of memory and consistency at the scale of minutes.
Captain Cinema: Towards Short Movie Generation
Jul 24, 2025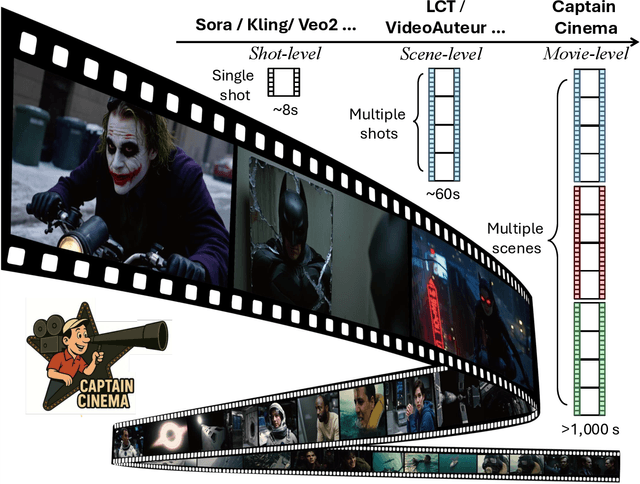
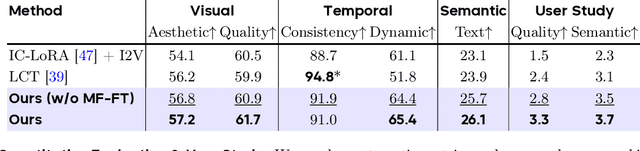

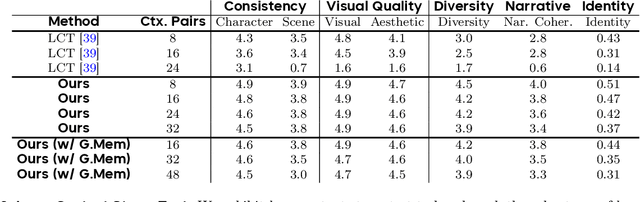
We present Captain Cinema, a generation framework for short movie generation. Given a detailed textual description of a movie storyline, our approach firstly generates a sequence of keyframes that outline the entire narrative, which ensures long-range coherence in both the storyline and visual appearance (e.g., scenes and characters). We refer to this step as top-down keyframe planning. These keyframes then serve as conditioning signals for a video synthesis model, which supports long context learning, to produce the spatio-temporal dynamics between them. This step is referred to as bottom-up video synthesis. To support stable and efficient generation of multi-scene long narrative cinematic works, we introduce an interleaved training strategy for Multimodal Diffusion Transformers (MM-DiT), specifically adapted for long-context video data. Our model is trained on a specially curated cinematic dataset consisting of interleaved data pairs. Our experiments demonstrate that Captain Cinema performs favorably in the automated creation of visually coherent and narrative consistent short movies in high quality and efficiency. Project page: https://thecinema.ai
X-Dyna: Expressive Dynamic Human Image Animation
Jan 20, 2025We introduce X-Dyna, a novel zero-shot, diffusion-based pipeline for animating a single human image using facial expressions and body movements derived from a driving video, that generates realistic, context-aware dynamics for both the subject and the surrounding environment. Building on prior approaches centered on human pose control, X-Dyna addresses key shortcomings causing the loss of dynamic details, enhancing the lifelike qualities of human video animations. At the core of our approach is the Dynamics-Adapter, a lightweight module that effectively integrates reference appearance context into the spatial attentions of the diffusion backbone while preserving the capacity of motion modules in synthesizing fluid and intricate dynamic details. Beyond body pose control, we connect a local control module with our model to capture identity-disentangled facial expressions, facilitating accurate expression transfer for enhanced realism in animated scenes. Together, these components form a unified framework capable of learning physical human motion and natural scene dynamics from a diverse blend of human and scene videos. Comprehensive qualitative and quantitative evaluations demonstrate that X-Dyna outperforms state-of-the-art methods, creating highly lifelike and expressive animations. The code is available at https://github.com/bytedance/X-Dyna.
Diffusion Self-Distillation for Zero-Shot Customized Image Generation
Nov 27, 2024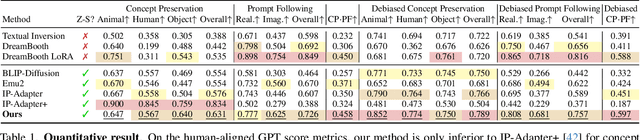
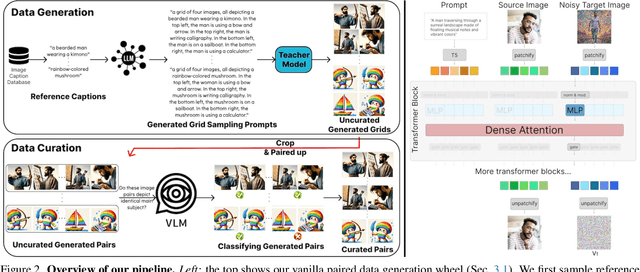
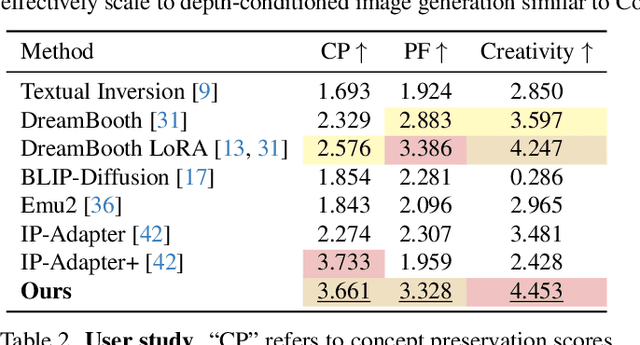

Text-to-image diffusion models produce impressive results but are frustrating tools for artists who desire fine-grained control. For example, a common use case is to create images of a specific instance in novel contexts, i.e., "identity-preserving generation". This setting, along with many other tasks (e.g., relighting), is a natural fit for image+text-conditional generative models. However, there is insufficient high-quality paired data to train such a model directly. We propose Diffusion Self-Distillation, a method for using a pre-trained text-to-image model to generate its own dataset for text-conditioned image-to-image tasks. We first leverage a text-to-image diffusion model's in-context generation ability to create grids of images and curate a large paired dataset with the help of a Visual-Language Model. We then fine-tune the text-to-image model into a text+image-to-image model using the curated paired dataset. We demonstrate that Diffusion Self-Distillation outperforms existing zero-shot methods and is competitive with per-instance tuning techniques on a wide range of identity-preservation generation tasks, without requiring test-time optimization.
Collaborative Video Diffusion: Consistent Multi-video Generation with Camera Control
May 27, 2024



Research on video generation has recently made tremendous progress, enabling high-quality videos to be generated from text prompts or images. Adding control to the video generation process is an important goal moving forward and recent approaches that condition video generation models on camera trajectories make strides towards it. Yet, it remains challenging to generate a video of the same scene from multiple different camera trajectories. Solutions to this multi-video generation problem could enable large-scale 3D scene generation with editable camera trajectories, among other applications. We introduce collaborative video diffusion (CVD) as an important step towards this vision. The CVD framework includes a novel cross-video synchronization module that promotes consistency between corresponding frames of the same video rendered from different camera poses using an epipolar attention mechanism. Trained on top of a state-of-the-art camera-control module for video generation, CVD generates multiple videos rendered from different camera trajectories with significantly better consistency than baselines, as shown in extensive experiments. Project page: https://collaborativevideodiffusion.github.io/.
Generative Rendering: Controllable 4D-Guided Video Generation with 2D Diffusion Models
Dec 03, 2023
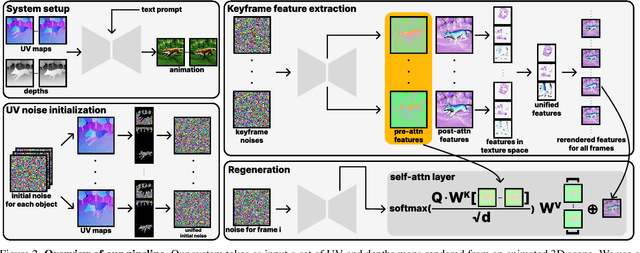


Traditional 3D content creation tools empower users to bring their imagination to life by giving them direct control over a scene's geometry, appearance, motion, and camera path. Creating computer-generated videos, however, is a tedious manual process, which can be automated by emerging text-to-video diffusion models. Despite great promise, video diffusion models are difficult to control, hindering a user to apply their own creativity rather than amplifying it. To address this challenge, we present a novel approach that combines the controllability of dynamic 3D meshes with the expressivity and editability of emerging diffusion models. For this purpose, our approach takes an animated, low-fidelity rendered mesh as input and injects the ground truth correspondence information obtained from the dynamic mesh into various stages of a pre-trained text-to-image generation model to output high-quality and temporally consistent frames. We demonstrate our approach on various examples where motion can be obtained by animating rigged assets or changing the camera path.