 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTA-Agent: An Open Recipe for Multimodal Deep Search Agents
Apr 07, 2026Multimodal large language models (MLLMs) have demonstrated strong capabilities in visual understanding, yet they remain limited in complex, multi-step reasoning that requires deep searching and integrating visual evidence with external knowledge. In this work, we address this challenge by constructing high-quality, verified multi-hop vision-language training data for multimodal deep-search agents. We propose a Multi-hop Tool-Augmented Agent for Evidence-based QA Synthesis (MTA-Agent), which automatically selects tools and their parameters to retrieve and validate evidence from both visual and textual sources and generates structured multi-hop question-answer trajectories. Starting from diverse VQA seed datasets, our pipeline produces a large-scale training dataset, MTA-Vision-DeepSearch, containing 21K high-quality multi-hop examples. The data is filtered through a multi-stage verification process to ensure factual consistency and answer uniqueness. Using MTA-Vision-DeepSearch, a 32B open-source multimodal search agent achieves state-of-the-art performance, reaching an average of 54.63\% across six challenging benchmarks, outperforming GPT-5 (51.86\%), Gemini-2.5-Pro (50.98\%), and Gemini-3-Pro (54.46\%) under the same tool settings. We further show that training on our data improves both reasoning depth and tool-use behavior, increasing the average number of steps from 2.27 to 4.28, and leading to more systematic and persistent search strategies. Additionally, we demonstrate that training can be performed without real-time tool calls by replaying cached interactions, significantly reducing training cost. Importantly, we present MTA-Agent as a fully open recipe for multimodal deep search: we release the entire dataset, training trajectories, and implementation details to enable reproducibility and future research on open multimodal search agents.
How Far Are Vision-Language Models from Constructing the Real World? A Benchmark for Physical Generative Reasoning
Mar 25, 2026The physical world is not merely visual; it is governed by rigorous structural and procedural constraints. Yet, the evaluation of vision-language models (VLMs) remains heavily skewed toward perceptual realism, prioritizing the generation of visually plausible 3D layouts, shapes, and appearances. Current benchmarks rarely test whether models grasp the step-by-step processes and physical dependencies required to actually build these artifacts, a capability essential for automating design-to-construction pipelines. To address this, we introduce DreamHouse, a novel benchmark for physical generative reasoning: the capacity to synthesize artifacts that concurrently satisfy geometric, structural, constructability, and code-compliance constraints. We ground this benchmark in residential timber-frame construction, a domain with fully codified engineering standards and objectively verifiable correctness. We curate over 26,000 structures spanning 13 architectural styles, ach verified to construction-document standards (LOD 350) and develop a deterministic 10-test structural validation framework. Unlike static benchmarks that assess only final outputs, DreamHouse supports iterative agentic interaction. Models observe intermediate build states, generate construction actions, and receive structured environmental feedback, enabling a fine-grained evaluation of planning, structural reasoning, and self-correction. Extensive experiments with state-of-the-art VLMs reveal substantial capability gaps that are largely invisible on existing leaderboards. These findings establish physical validity as a critical evaluation axis orthogonal to visual realism, highlighting physical generative reasoning as a distinct and underdeveloped frontier in multimodal intelligence. Available at https://luluyuyuyang.github.io/dreamhouse
Real Money, Fake Models: Deceptive Model Claims in Shadow APIs
Mar 05, 2026Access to frontier large language models (LLMs), such as GPT-5 and Gemini-2.5, is often hindered by high pricing, payment barriers, and regional restrictions. These limitations drive the proliferation of $\textit{shadow APIs}$, third-party services that claim to provide access to official model services without regional limitations via indirect access. Despite their widespread use, it remains unclear whether shadow APIs deliver outputs consistent with those of the official APIs, raising concerns about the reliability of downstream applications and the validity of research findings that depend on them. In this paper, we present the first systematic audit between official LLM APIs and corresponding shadow APIs. We first identify 17 shadow APIs that have been utilized in 187 academic papers, with the most popular one reaching 5,966 citations and 58,639 GitHub stars by December 6, 2025. Through multidimensional auditing of three representative shadow APIs across utility, safety, and model verification, we uncover both indirect and direct evidence of deception practices in shadow APIs. Specifically, we reveal performance divergence reaching up to $47.21\%$, significant unpredictability in safety behaviors, and identity verification failures in $45.83\%$ of fingerprint tests. These deceptive practices critically undermine the reproducibility and validity of scientific research, harm the interests of shadow API users, and damage the reputation of official model providers.
CADGrasp: Learning Contact and Collision Aware General Dexterous Grasping in Cluttered Scenes
Jan 21, 2026Dexterous grasping in cluttered environments presents substantial challenges due to the high degrees of freedom of dexterous hands, occlusion, and potential collisions arising from diverse object geometries and complex layouts. To address these challenges, we propose CADGrasp, a two-stage algorithm for general dexterous grasping using single-view point cloud inputs. In the first stage, we predict sparse IBS, a scene-decoupled, contact- and collision-aware representation, as the optimization target. Sparse IBS compactly encodes the geometric and contact relationships between the dexterous hand and the scene, enabling stable and collision-free dexterous grasp pose optimization. To enhance the prediction of this high-dimensional representation, we introduce an occupancy-diffusion model with voxel-level conditional guidance and force closure score filtering. In the second stage, we develop several energy functions and ranking strategies for optimization based on sparse IBS to generate high-quality dexterous grasp poses. Extensive experiments in both simulated and real-world settings validate the effectiveness of our approach, demonstrating its capability to mitigate collisions while maintaining a high grasp success rate across diverse objects and complex scenes.
Soft Tail-dropping for Adaptive Visual Tokenization
Jan 20, 2026We present Soft Tail-dropping Adaptive Tokenizer (STAT), a 1D discrete visual tokenizer that adaptively chooses the number of output tokens per image according to its structural complexity and level of detail. STAT encodes an image into a sequence of discrete codes together with per-token keep probabilities. Beyond standard autoencoder objectives, we regularize these keep probabilities to be monotonically decreasing along the sequence and explicitly align their distribution with an image-level complexity measure. As a result, STAT produces length-adaptive 1D visual tokens that are naturally compatible with causal 1D autoregressive (AR) visual generative models. On ImageNet-1k, equipping vanilla causal AR models with STAT yields competitive or superior visual generation quality compared to other probabilistic model families, while also exhibiting favorable scaling behavior that has been elusive in prior vanilla AR visual generation attempts.
APEX: Academic Poster Editing Agentic Expert
Jan 08, 2026Designing academic posters is a labor-intensive process requiring the precise balance of high-density content and sophisticated layout. While existing paper-to-poster generation methods automate initial drafting, they are typically single-pass and non-interactive, often fail to align with complex, subjective user intent. To bridge this gap, we propose APEX (Academic Poster Editing agentic eXpert), the first agentic framework for interactive academic poster editing, supporting fine-grained control with robust multi-level API-based editing and a review-and-adjustment Mechanism. In addition, we introduce APEX-Bench, the first systematic benchmark comprising 514 academic poster editing instructions, categorized by a multi-dimensional taxonomy including operation type, difficulty, and abstraction level, constructed via reference-guided and reference-free strategies to ensure realism and diversity. We further establish a multi-dimensional VLM-as-a-judge evaluation protocol to assess instruction fulfillment, modification scope, and visual consistency & harmony. Experimental results demonstrate that APEX significantly outperforms baseline methods. Our implementation is available at https://github.com/Breesiu/APEX.
CVP: Central-Peripheral Vision-Inspired Multimodal Model for Spatial Reasoning
Dec 09, 2025We present a central-peripheral vision-inspired framework (CVP), a simple yet effective multimodal model for spatial reasoning that draws inspiration from the two types of human visual fields -- central vision and peripheral vision. Existing approaches primarily rely on unstructured representations, such as point clouds, voxels, or patch features, and inject scene context implicitly via coordinate embeddings. However, this often results in limited spatial reasoning capabilities due to the lack of explicit, high-level structural understanding. To address this limitation, we introduce two complementary components into a Large Multimodal Model-based architecture: target-affinity token, analogous to central vision, that guides the model's attention toward query-relevant objects; and allocentric grid, akin to peripheral vision, that captures global scene context and spatial arrangements. These components work in tandem to enable structured, context-aware understanding of complex 3D environments. Experiments show that CVP achieves state-of-the-art performance across a range of 3D scene understanding benchmarks.
C3Editor: Achieving Controllable Consistency in 2D Model for 3D Editing
Oct 06, 2025Existing 2D-lifting-based 3D editing methods often encounter challenges related to inconsistency, stemming from the lack of view-consistent 2D editing models and the difficulty of ensuring consistent editing across multiple views. To address these issues, we propose C3Editor, a controllable and consistent 2D-lifting-based 3D editing framework. Given an original 3D representation and a text-based editing prompt, our method selectively establishes a view-consistent 2D editing model to achieve superior 3D editing results. The process begins with the controlled selection of a ground truth (GT) view and its corresponding edited image as the optimization target, allowing for user-defined manual edits. Next, we fine-tune the 2D editing model within the GT view and across multiple views to align with the GT-edited image while ensuring multi-view consistency. To meet the distinct requirements of GT view fitting and multi-view consistency, we introduce separate LoRA modules for targeted fine-tuning. Our approach delivers more consistent and controllable 2D and 3D editing results than existing 2D-lifting-based methods, outperforming them in both qualitative and quantitative evaluations.
WALT: Web Agents that Learn Tools
Oct 01, 2025Web agents promise to automate complex browser tasks, but current methods remain brittle -- relying on step-by-step UI interactions and heavy LLM reasoning that break under dynamic layouts and long horizons. Humans, by contrast, exploit website-provided functionality through high-level operations like search, filter, and sort. We introduce WALT (Web Agents that Learn Tools), a framework that reverse-engineers latent website functionality into reusable invocable tools. Rather than hypothesizing ad-hoc skills, WALT exposes robust implementations of automations already designed into websites -- spanning discovery (search, filter, sort), communication (post, comment, upvote), and content management (create, edit, delete). Tools abstract away low-level execution: instead of reasoning about how to click and type, agents simply call search(query) or create(listing). This shifts the computational burden from fragile step-by-step reasoning to reliable tool invocation. On VisualWebArena and WebArena, WALT achieves higher success with fewer steps and less LLM-dependent reasoning, establishing a robust and generalizable paradigm for browser automation.
SCUBA: Salesforce Computer Use Benchmark
Sep 30, 2025

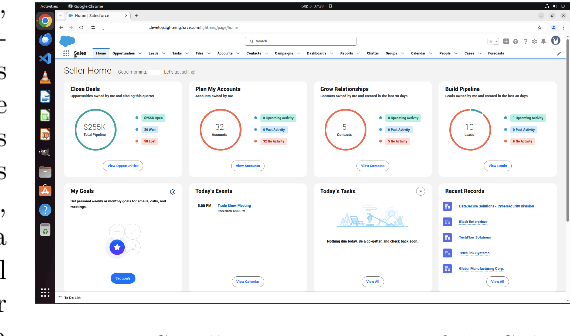

We introduce SCUBA, a benchmark designed to evaluate computer-use agents on customer relationship management (CRM) workflows within the Salesforce platform. SCUBA contains 300 task instances derived from real user interviews, spanning three primary personas, platform administrators, sales representatives, and service agents. The tasks test a range of enterprise-critical abilities, including Enterprise Software UI navigation, data manipulation, workflow automation, information retrieval, and troubleshooting. To ensure realism, SCUBA operates in Salesforce sandbox environments with support for parallel execution and fine-grained evaluation metrics to capture milestone progress. We benchmark a diverse set of agents under both zero-shot and demonstration-augmented settings. We observed huge performance gaps in different agent design paradigms and gaps between the open-source model and the closed-source model. In the zero-shot setting, open-source model powered computer-use agents that have strong performance on related benchmarks like OSWorld only have less than 5\% success rate on SCUBA, while methods built on closed-source models can still have up to 39% task success rate. In the demonstration-augmented settings, task success rates can be improved to 50\% while simultaneously reducing time and costs by 13% and 16%, respectively. These findings highlight both the challenges of enterprise tasks automation and the promise of agentic solutions. By offering a realistic benchmark with interpretable evaluation, SCUBA aims to accelerate progress in building reliable computer-use agents for complex business software ecosystems.