 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAST: Gradient-aligned Sparse Tuning of Large Language Models with Data-layer Selection
Mar 10, 2026Parameter-Efficient Fine-Tuning (PEFT) has become a key strategy for adapting large language models, with recent advances in sparse tuning reducing overhead by selectively updating key parameters or subsets of data. Existing approaches generally focus on two distinct paradigms: layer-selective methods aiming to fine-tune critical layers to minimize computational load, and data-selective methods aiming to select effective training subsets to boost training. However, current methods typically overlook the fact that different data points contribute varying degrees to distinct model layers, and they often discard potentially valuable information from data perceived as of low quality. To address these limitations, we propose Gradient-aligned Sparse Tuning (GAST), an innovative method that simultaneously performs selective fine-tuning at both data and layer dimensions as integral components of a unified optimization strategy. GAST specifically targets redundancy in information by employing a layer-sparse strategy that adaptively selects the most impactful data points for each layer, providing a more comprehensive and sophisticated solution than approaches restricted to a single dimension. Experiments demonstrate that GAST consistently outperforms baseline methods, establishing a promising direction for future research in PEFT strategies.
Alleviating LLM-based Generative Retrieval Hallucination in Alipay Search
Mar 27, 2025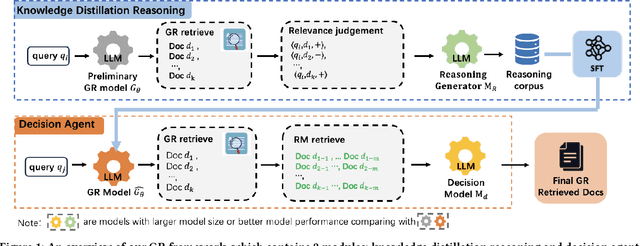
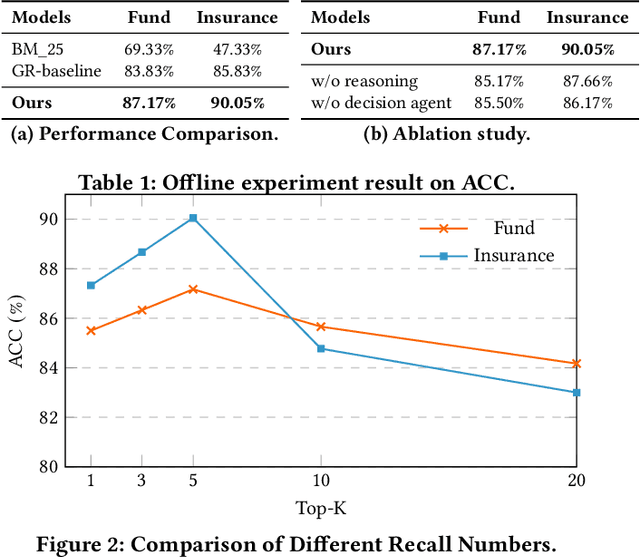

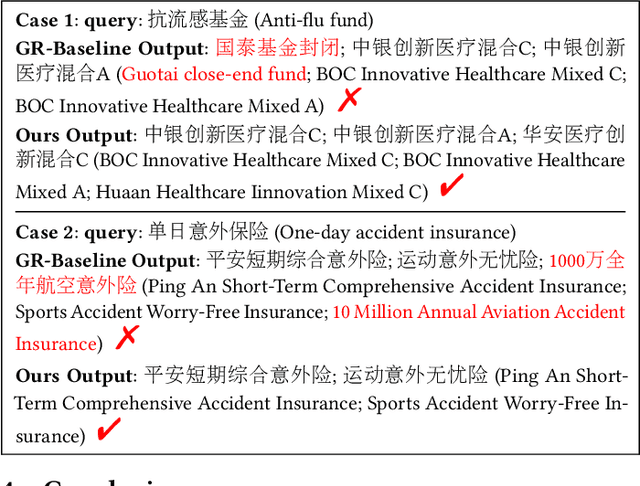
Generative retrieval (GR) has revolutionized document retrieval with the advent of large language models (LLMs), and LLM-based GR is gradually being adopted by the industry. Despite its remarkable advantages and potential, LLM-based GR suffers from hallucination and generates documents that are irrelevant to the query in some instances, severely challenging its credibility in practical applications. We thereby propose an optimized GR framework designed to alleviate retrieval hallucination, which integrates knowledge distillation reasoning in model training and incorporate decision agent to further improve retrieval precision. Specifically, we employ LLMs to assess and reason GR retrieved query-document (q-d) pairs, and then distill the reasoning data as transferred knowledge to the GR model. Moreover, we utilize a decision agent as post-processing to extend the GR retrieved documents through retrieval model and select the most relevant ones from multi perspectives as the final generative retrieval result. Extensive offline experiments on real-world datasets and online A/B tests on Fund Search and Insurance Search in Alipay demonstrate our framework's superiority and effectiveness in improving search quality and conversion gains.
Test-time Computing: from System-1 Thinking to System-2 Thinking
Jan 05, 2025



The remarkable performance of the o1 model in complex reasoning demonstrates that test-time computing scaling can further unlock the model's potential, enabling powerful System-2 thinking. However, there is still a lack of comprehensive surveys for test-time computing scaling. We trace the concept of test-time computing back to System-1 models. In System-1 models, test-time computing addresses distribution shifts and improves robustness and generalization through parameter updating, input modification, representation editing, and output calibration. In System-2 models, it enhances the model's reasoning ability to solve complex problems through repeated sampling, self-correction, and tree search. We organize this survey according to the trend of System-1 to System-2 thinking, highlighting the key role of test-time computing in the transition from System-1 models to weak System-2 models, and then to strong System-2 models. We also point out a few possible future directions.
Boosting LLM-based Relevance Modeling with Distribution-Aware Robust Learning
Dec 17, 2024With the rapid advancement of pre-trained large language models (LLMs), recent endeavors have leveraged the capabilities of LLMs in relevance modeling, resulting in enhanced performance. This is usually done through the process of fine-tuning LLMs on specifically annotated datasets to determine the relevance between queries and items. However, there are two limitations when LLMs are naively employed for relevance modeling through fine-tuning and inference. First, it is not inherently efficient for performing nuanced tasks beyond simple yes or no answers, such as assessing search relevance. It may therefore tend to be overconfident and struggle to distinguish fine-grained degrees of relevance (e.g., strong relevance, weak relevance, irrelevance) used in search engines. Second, it exhibits significant performance degradation when confronted with data distribution shift in real-world scenarios. In this paper, we propose a novel Distribution-Aware Robust Learning framework (DaRL) for relevance modeling in Alipay Search. Specifically, we design an effective loss function to enhance the discriminability of LLM-based relevance modeling across various fine-grained degrees of query-item relevance. To improve the generalizability of LLM-based relevance modeling, we first propose the Distribution-Aware Sample Augmentation (DASA) module. This module utilizes out-of-distribution (OOD) detection techniques to actively select appropriate samples that are not well covered by the original training set for model fine-tuning. Furthermore, we adopt a multi-stage fine-tuning strategy to simultaneously improve in-distribution (ID) and OOD performance, bridging the performance gap between them. DaRL has been deployed online to serve the Alipay's insurance product search...
* 8 pages
CPRM: A LLM-based Continual Pre-training Framework for Relevance Modeling in Commercial Search
Dec 03, 2024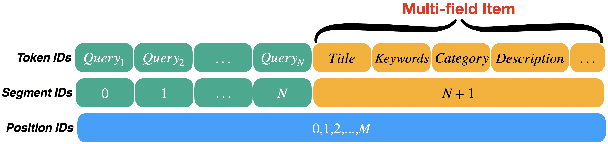
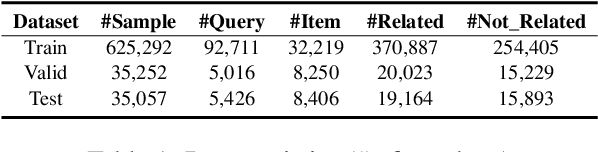
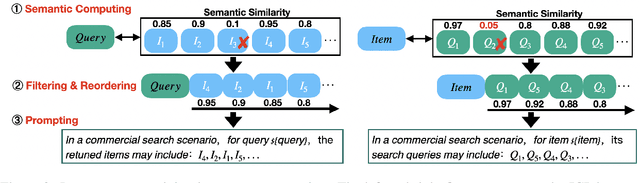
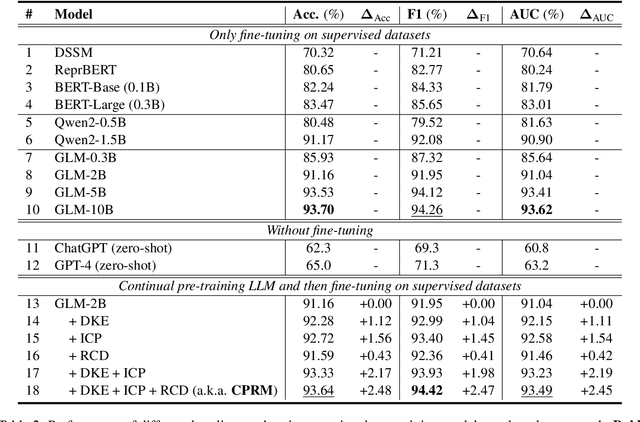
Relevance modeling between queries and items stands as a pivotal component in commercial search engines, directly affecting the user experience. Given the remarkable achievements of large language models (LLMs) in various natural language processing (NLP) tasks, LLM-based relevance modeling is gradually being adopted within industrial search systems. Nevertheless, foundational LLMs lack domain-specific knowledge and do not fully exploit the potential of in-context learning. Furthermore, structured item text remains underutilized, and there is a shortage in the supply of corresponding queries and background knowledge. We thereby propose CPRM (Continual Pre-training for Relevance Modeling), a framework designed for the continual pre-training of LLMs to address these issues. Our CPRM framework includes three modules: 1) employing both queries and multi-field item to jointly pre-train for enhancing domain knowledge, 2) applying in-context pre-training, a novel approach where LLMs are pre-trained on a sequence of related queries or items, and 3) conducting reading comprehension on items to produce associated domain knowledge and background information (e.g., generating summaries and corresponding queries) to further strengthen LLMs. Results on offline experiments and online A/B testing demonstrate that our model achieves convincing performance compared to strong baselines.
Towards Boosting LLMs-driven Relevance Modeling with Progressive Retrieved Behavior-augmented Prompting
Aug 18, 2024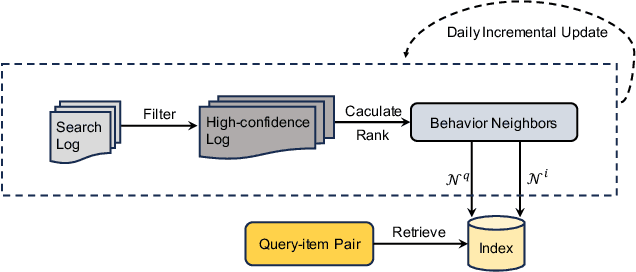

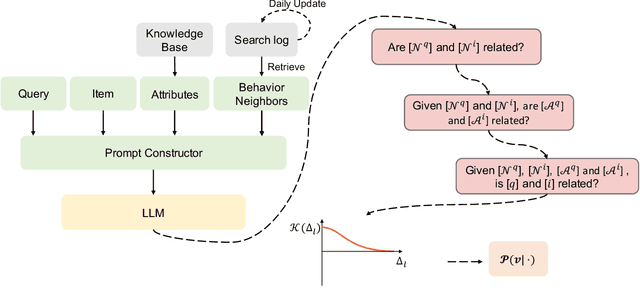
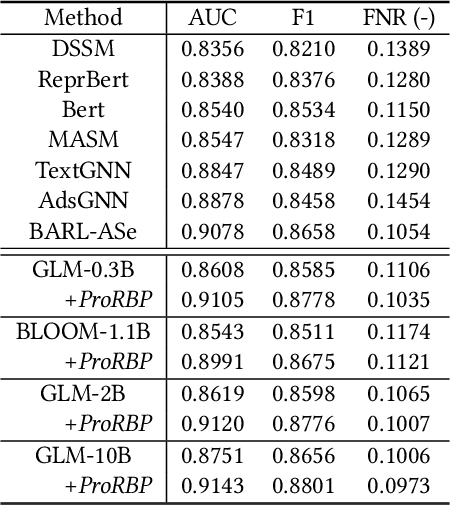
Relevance modeling is a critical component for enhancing user experience in search engines, with the primary objective of identifying items that align with users' queries. Traditional models only rely on the semantic congruence between queries and items to ascertain relevance. However, this approach represents merely one aspect of the relevance judgement, and is insufficient in isolation. Even powerful Large Language Models (LLMs) still cannot accurately judge the relevance of a query and an item from a semantic perspective. To augment LLMs-driven relevance modeling, this study proposes leveraging user interactions recorded in search logs to yield insights into users' implicit search intentions. The challenge lies in the effective prompting of LLMs to capture dynamic search intentions, which poses several obstacles in real-world relevance scenarios, i.e., the absence of domain-specific knowledge, the inadequacy of an isolated prompt, and the prohibitive costs associated with deploying LLMs. In response, we propose ProRBP, a novel Progressive Retrieved Behavior-augmented Prompting framework for integrating search scenario-oriented knowledge with LLMs effectively. Specifically, we perform the user-driven behavior neighbors retrieval from the daily search logs to obtain domain-specific knowledge in time, retrieving candidates that users consider to meet their expectations. Then, we guide LLMs for relevance modeling by employing advanced prompting techniques that progressively improve the outputs of the LLMs, followed by a progressive aggregation with comprehensive consideration of diverse aspects. For online serving, we have developed an industrial application framework tailored for the deployment of LLMs in relevance modeling. Experiments on real-world industry data and online A/B testing demonstrate our proposal achieves promising performance.