 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMI-DPG: Decomposable Parameter Generation Network Based on Mutual Information for Multi-Scenario Recommendation
Mar 22, 2026Conversion rate (CVR) prediction models play a vital role in recommendation and advertising systems. Recent research on multi-scenario recommendation shows that learning a unified model to serve multiple scenarios is effective for improving overall performance. However, it remains challenging to improve model prediction performance across scenarios at low model parameter cost, and current solutions are hard to robustly model multi-scenario diversity. In this paper, we propose MI-DPG for the multi-scenario CVR prediction, which learns scenario-conditioned dynamic model parameters for each scenario in a more efficient and effective manner. Specifically, we introduce an auxiliary network to generate scenario-conditioned dynamic weighting matrices, which are obtained by combining decomposed scenario-specific and scenario-shared low-rank matrices with parameter efficiency. For each scene, weighting the backbone model parameters by the weighting matrix helps to specialize the model parameters for different scenarios. It can not only modulate the complete parameter space of the backbone model but also improve the model effectiveness. Furthermore, we design a mutual information regularization to enhance the diversity of model parameters across different scenarios by maximizing the mutual information between the scenario-aware input and the scene-conditioned dynamic weighting matrix. Experiments from three real-world datasets show that MI-DPG significantly outperforms previous multi-scenario recommendation models.
* Accepted by CIKM 2023
MiniAppBench: Evaluating the Shift from Text to Interactive HTML Responses in LLM-Powered Assistants
Mar 10, 2026With the rapid advancement of Large Language Models (LLMs) in code generation, human-AI interaction is evolving from static text responses to dynamic, interactive HTML-based applications, which we term MiniApps. These applications require models to not only render visual interfaces but also construct customized interaction logic that adheres to real-world principles. However, existing benchmarks primarily focus on algorithmic correctness or static layout reconstruction, failing to capture the capabilities required for this new paradigm. To address this gap, we introduce MiniAppBench, the first comprehensive benchmark designed to evaluate principle-driven, interactive application generation. Sourced from a real-world application with 10M+ generations, MiniAppBench distills 500 tasks across six domains (e.g., Games, Science, and Tools). Furthermore, to tackle the challenge of evaluating open-ended interactions where no single ground truth exists, we propose MiniAppEval, an agentic evaluation framework. Leveraging browser automation, it performs human-like exploratory testing to systematically assess applications across three dimensions: Intention, Static, and Dynamic. Our experiments reveal that current LLMs still face significant challenges in generating high-quality MiniApps, while MiniAppEval demonstrates high alignment with human judgment, establishing a reliable standard for future research. Our code is available in github.com/MiniAppBench.
A Learnable Fully Interacted Two-Tower Model for Pre-Ranking System
Sep 16, 2025Pre-ranking plays a crucial role in large-scale recommender systems by significantly improving the efficiency and scalability within the constraints of providing high-quality candidate sets in real time. The two-tower model is widely used in pre-ranking systems due to a good balance between efficiency and effectiveness with decoupled architecture, which independently processes user and item inputs before calculating their interaction (e.g. dot product or similarity measure). However, this independence also leads to the lack of information interaction between the two towers, resulting in less effectiveness. In this paper, a novel architecture named learnable Fully Interacted Two-tower Model (FIT) is proposed, which enables rich information interactions while ensuring inference efficiency. FIT mainly consists of two parts: Meta Query Module (MQM) and Lightweight Similarity Scorer (LSS). Specifically, MQM introduces a learnable item meta matrix to achieve expressive early interaction between user and item features. Moreover, LSS is designed to further obtain effective late interaction between the user and item towers. Finally, experimental results on several public datasets show that our proposed FIT significantly outperforms the state-of-the-art baseline pre-ranking models.
MCPToolBench++: A Large Scale AI Agent Model Context Protocol MCP Tool Use Benchmark
Aug 11, 2025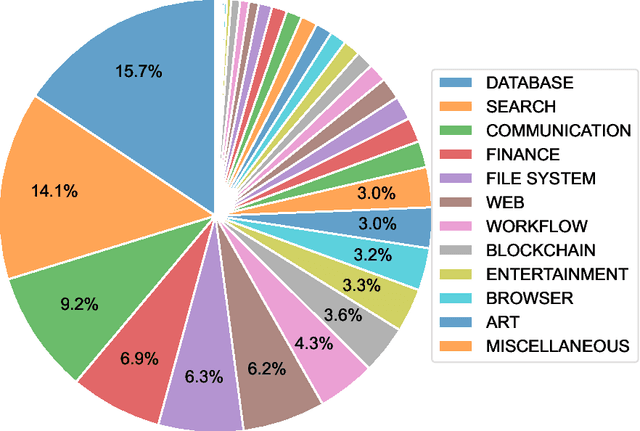
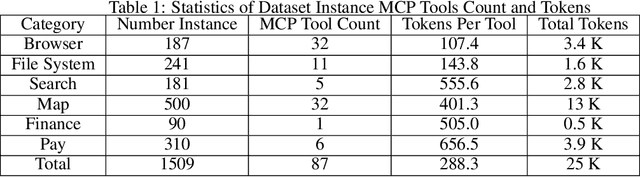
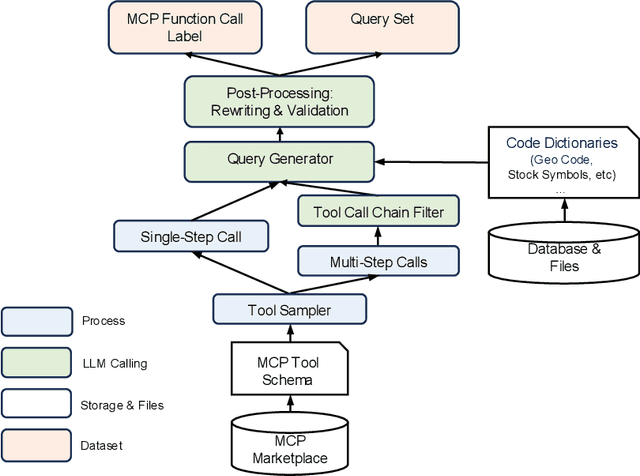
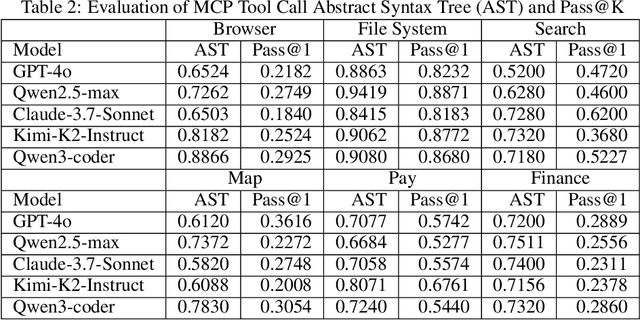
LLMs' capabilities are enhanced by using function calls to integrate various data sources or API results into the context window. Typical tools include search, web crawlers, maps, financial data, file systems, and browser usage, etc. Integrating these data sources or functions requires a standardized method. The Model Context Protocol (MCP) provides a standardized way to supply context to LLMs. However, the evaluation of LLMs and AI Agents' MCP tool use abilities suffer from several issues. First, there's a lack of comprehensive datasets or benchmarks to evaluate various MCP tools. Second, the diverse formats of response from MCP tool call execution further increase the difficulty of evaluation. Additionally, unlike existing tool-use benchmarks with high success rates in functions like programming and math functions, the success rate of real-world MCP tool is not guaranteed and varies across different MCP servers. Furthermore, the LLMs' context window also limits the number of available tools that can be called in a single run, because the textual descriptions of tool and the parameters have long token length for an LLM to process all at once. To help address the challenges of evaluating LLMs' performance on calling MCP tools, we propose MCPToolBench++, a large-scale, multi-domain AI Agent tool use benchmark. As of July 2025, this benchmark is build upon marketplace of over 4k MCP servers from more than 40 categories, collected from the MCP marketplaces and GitHub communities. The datasets consist of both single-step and multi-step tool calls across different categories. We evaluated SOTA LLMs with agentic abilities on this benchmark and reported the results.
Alleviating LLM-based Generative Retrieval Hallucination in Alipay Search
Mar 27, 2025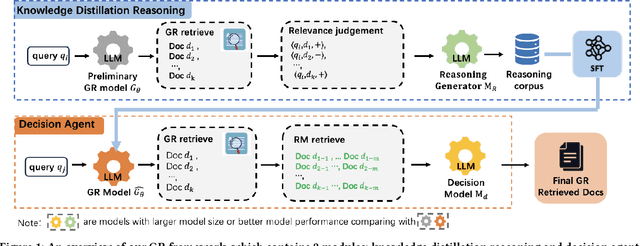
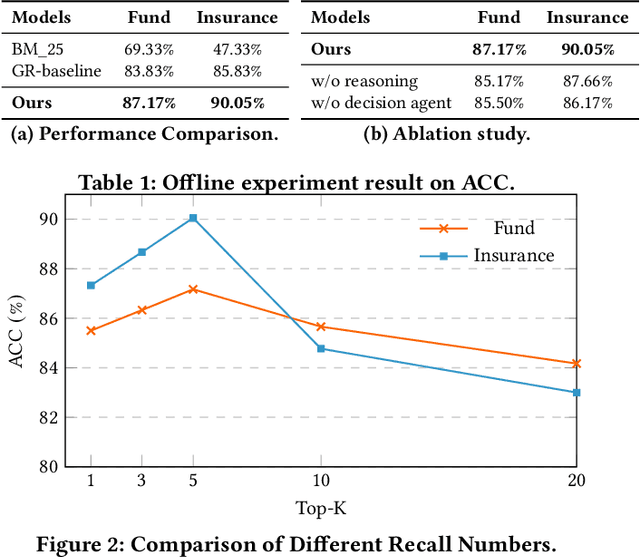

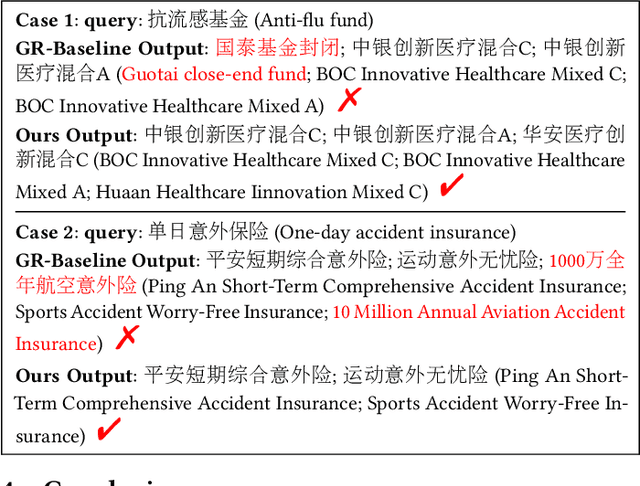
Generative retrieval (GR) has revolutionized document retrieval with the advent of large language models (LLMs), and LLM-based GR is gradually being adopted by the industry. Despite its remarkable advantages and potential, LLM-based GR suffers from hallucination and generates documents that are irrelevant to the query in some instances, severely challenging its credibility in practical applications. We thereby propose an optimized GR framework designed to alleviate retrieval hallucination, which integrates knowledge distillation reasoning in model training and incorporate decision agent to further improve retrieval precision. Specifically, we employ LLMs to assess and reason GR retrieved query-document (q-d) pairs, and then distill the reasoning data as transferred knowledge to the GR model. Moreover, we utilize a decision agent as post-processing to extend the GR retrieved documents through retrieval model and select the most relevant ones from multi perspectives as the final generative retrieval result. Extensive offline experiments on real-world datasets and online A/B tests on Fund Search and Insurance Search in Alipay demonstrate our framework's superiority and effectiveness in improving search quality and conversion gains.
DOGR: Leveraging Document-Oriented Contrastive Learning in Generative Retrieval
Feb 12, 2025



Generative retrieval constitutes an innovative approach in information retrieval, leveraging generative language models (LM) to generate a ranked list of document identifiers (docid) for a given query. It simplifies the retrieval pipeline by replacing the large external index with model parameters. However, existing works merely learned the relationship between queries and document identifiers, which is unable to directly represent the relevance between queries and documents. To address the above problem, we propose a novel and general generative retrieval framework, namely Leveraging Document-Oriented Contrastive Learning in Generative Retrieval (DOGR), which leverages contrastive learning to improve generative retrieval tasks. It adopts a two-stage learning strategy that captures the relationship between queries and documents comprehensively through direct interactions. Furthermore, negative sampling methods and corresponding contrastive learning objectives are implemented to enhance the learning of semantic representations, thereby promoting a thorough comprehension of the relationship between queries and documents. Experimental results demonstrate that DOGR achieves state-of-the-art performance compared to existing generative retrieval methods on two public benchmark datasets. Further experiments have shown that our framework is generally effective for common identifier construction techniques.
Test-time Computing: from System-1 Thinking to System-2 Thinking
Jan 05, 2025



The remarkable performance of the o1 model in complex reasoning demonstrates that test-time computing scaling can further unlock the model's potential, enabling powerful System-2 thinking. However, there is still a lack of comprehensive surveys for test-time computing scaling. We trace the concept of test-time computing back to System-1 models. In System-1 models, test-time computing addresses distribution shifts and improves robustness and generalization through parameter updating, input modification, representation editing, and output calibration. In System-2 models, it enhances the model's reasoning ability to solve complex problems through repeated sampling, self-correction, and tree search. We organize this survey according to the trend of System-1 to System-2 thinking, highlighting the key role of test-time computing in the transition from System-1 models to weak System-2 models, and then to strong System-2 models. We also point out a few possible future directions.
CPRM: A LLM-based Continual Pre-training Framework for Relevance Modeling in Commercial Search
Dec 03, 2024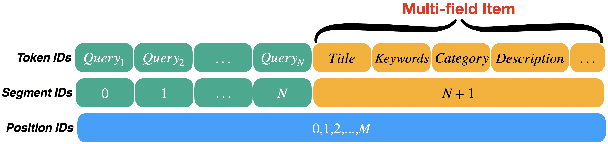
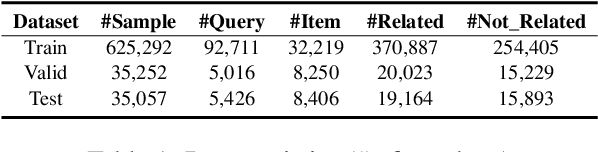
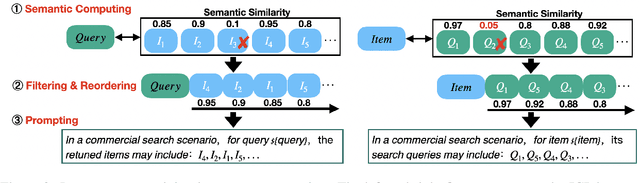
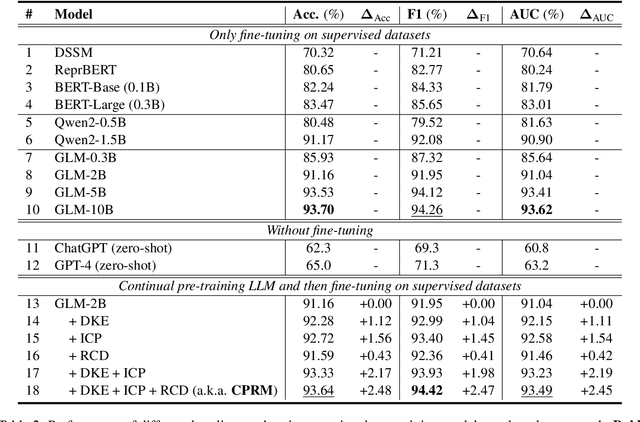
Relevance modeling between queries and items stands as a pivotal component in commercial search engines, directly affecting the user experience. Given the remarkable achievements of large language models (LLMs) in various natural language processing (NLP) tasks, LLM-based relevance modeling is gradually being adopted within industrial search systems. Nevertheless, foundational LLMs lack domain-specific knowledge and do not fully exploit the potential of in-context learning. Furthermore, structured item text remains underutilized, and there is a shortage in the supply of corresponding queries and background knowledge. We thereby propose CPRM (Continual Pre-training for Relevance Modeling), a framework designed for the continual pre-training of LLMs to address these issues. Our CPRM framework includes three modules: 1) employing both queries and multi-field item to jointly pre-train for enhancing domain knowledge, 2) applying in-context pre-training, a novel approach where LLMs are pre-trained on a sequence of related queries or items, and 3) conducting reading comprehension on items to produce associated domain knowledge and background information (e.g., generating summaries and corresponding queries) to further strengthen LLMs. Results on offline experiments and online A/B testing demonstrate that our model achieves convincing performance compared to strong baselines.
Breaking the Length Barrier: LLM-Enhanced CTR Prediction in Long Textual User Behaviors
Mar 28, 2024With the rise of large language models (LLMs), recent works have leveraged LLMs to improve the performance of click-through rate (CTR) prediction. However, we argue that a critical obstacle remains in deploying LLMs for practical use: the efficiency of LLMs when processing long textual user behaviors. As user sequences grow longer, the current efficiency of LLMs is inadequate for training on billions of users and items. To break through the efficiency barrier of LLMs, we propose Behavior Aggregated Hierarchical Encoding (BAHE) to enhance the efficiency of LLM-based CTR modeling. Specifically, BAHE proposes a novel hierarchical architecture that decouples the encoding of user behaviors from inter-behavior interactions. Firstly, to prevent computational redundancy from repeated encoding of identical user behaviors, BAHE employs the LLM's pre-trained shallow layers to extract embeddings of the most granular, atomic user behaviors from extensive user sequences and stores them in the offline database. Subsequently, the deeper, trainable layers of the LLM facilitate intricate inter-behavior interactions, thereby generating comprehensive user embeddings. This separation allows the learning of high-level user representations to be independent of low-level behavior encoding, significantly reducing computational complexity. Finally, these refined user embeddings, in conjunction with correspondingly processed item embeddings, are incorporated into the CTR model to compute the CTR scores. Extensive experimental results show that BAHE reduces training time and memory by five times for CTR models using LLMs, especially with longer user sequences. BAHE has been deployed in a real-world system, allowing for daily updates of 50 million CTR data on 8 A100 GPUs, making LLMs practical for industrial CTR prediction.
AntM$^{2}$C: A Large Scale Dataset For Multi-Scenario Multi-Modal CTR Prediction
Aug 31, 2023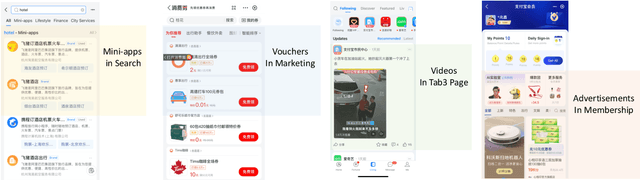

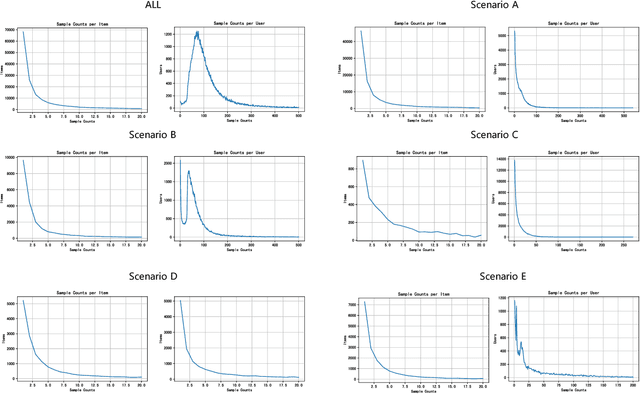

Click-through rate (CTR) prediction is a crucial issue in recommendation systems. There has been an emergence of various public CTR datasets. However, existing datasets primarily suffer from the following limitations. Firstly, users generally click different types of items from multiple scenarios, and modeling from multiple scenarios can provide a more comprehensive understanding of users. Existing datasets only include data for the same type of items from a single scenario. Secondly, multi-modal features are essential in multi-scenario prediction as they address the issue of inconsistent ID encoding between different scenarios. The existing datasets are based on ID features and lack multi-modal features. Third, a large-scale dataset can provide a more reliable evaluation of models, fully reflecting the performance differences between models. The scale of existing datasets is around 100 million, which is relatively small compared to the real-world CTR prediction. To address these limitations, we propose AntM$^{2}$C, a Multi-Scenario Multi-Modal CTR dataset based on industrial data from Alipay. Specifically, AntM$^{2}$C provides the following advantages: 1) It covers CTR data of 5 different types of items, providing insights into the preferences of users for different items, including advertisements, vouchers, mini-programs, contents, and videos. 2) Apart from ID-based features, AntM$^{2}$C also provides 2 multi-modal features, raw text and image features, which can effectively establish connections between items with different IDs. 3) AntM$^{2}$C provides 1 billion CTR data with 200 features, including 200 million users and 6 million items. It is currently the largest-scale CTR dataset available. Based on AntM$^{2}$C, we construct several typical CTR tasks and provide comparisons with baseline methods. The dataset homepage is available at https://www.atecup.cn/home.