 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Learnable Fully Interacted Two-Tower Model for Pre-Ranking System
Sep 16, 2025Pre-ranking plays a crucial role in large-scale recommender systems by significantly improving the efficiency and scalability within the constraints of providing high-quality candidate sets in real time. The two-tower model is widely used in pre-ranking systems due to a good balance between efficiency and effectiveness with decoupled architecture, which independently processes user and item inputs before calculating their interaction (e.g. dot product or similarity measure). However, this independence also leads to the lack of information interaction between the two towers, resulting in less effectiveness. In this paper, a novel architecture named learnable Fully Interacted Two-tower Model (FIT) is proposed, which enables rich information interactions while ensuring inference efficiency. FIT mainly consists of two parts: Meta Query Module (MQM) and Lightweight Similarity Scorer (LSS). Specifically, MQM introduces a learnable item meta matrix to achieve expressive early interaction between user and item features. Moreover, LSS is designed to further obtain effective late interaction between the user and item towers. Finally, experimental results on several public datasets show that our proposed FIT significantly outperforms the state-of-the-art baseline pre-ranking models.
semi-PD: Towards Efficient LLM Serving via Phase-Wise Disaggregated Computation and Unified Storage
Apr 28, 2025Existing large language model (LLM) serving systems fall into two categories: 1) a unified system where prefill phase and decode phase are co-located on the same GPU, sharing the unified computational resource and storage, and 2) a disaggregated system where the two phases are disaggregated to different GPUs. The design of the disaggregated system addresses the latency interference and sophisticated scheduling issues in the unified system but leads to storage challenges including 1) replicated weights for both phases that prevent flexible deployment, 2) KV cache transfer overhead between the two phases, 3) storage imbalance that causes substantial wasted space of the GPU capacity, and 4) suboptimal resource adjustment arising from the difficulties in migrating KV cache. Such storage inefficiency delivers poor serving performance under high request rates. In this paper, we identify that the advantage of the disaggregated system lies in the disaggregated computation, i.e., partitioning the computational resource to enable the asynchronous computation of two phases. Thus, we propose a novel LLM serving system, semi-PD, characterized by disaggregated computation and unified storage. In semi-PD, we introduce a computation resource controller to achieve disaggregated computation at the streaming multi-processor (SM) level, and a unified memory manager to manage the asynchronous memory access from both phases. semi-PD has a low-overhead resource adjustment mechanism between the two phases, and a service-level objective (SLO) aware dynamic partitioning algorithm to optimize the SLO attainment. Compared to state-of-the-art systems, semi-PD maintains lower latency at higher request rates, reducing the average end-to-end latency per request by 1.27-2.58x on DeepSeek series models, and serves 1.55-1.72x more requests adhering to latency constraints on Llama series models.
GDOD: Effective Gradient Descent using Orthogonal Decomposition for Multi-Task Learning
Jan 31, 2023Multi-task learning (MTL) aims at solving multiple related tasks simultaneously and has experienced rapid growth in recent years. However, MTL models often suffer from performance degeneration with negative transfer due to learning several tasks simultaneously. Some related work attributed the source of the problem is the conflicting gradients. In this case, it is needed to select useful gradient updates for all tasks carefully. To this end, we propose a novel optimization approach for MTL, named GDOD, which manipulates gradients of each task using an orthogonal basis decomposed from the span of all task gradients. GDOD decomposes gradients into task-shared and task-conflict components explicitly and adopts a general update rule for avoiding interference across all task gradients. This allows guiding the update directions depending on the task-shared components. Moreover, we prove the convergence of GDOD theoretically under both convex and non-convex assumptions. Experiment results on several multi-task datasets not only demonstrate the significant improvement of GDOD performed to existing MTL models but also prove that our algorithm outperforms state-of-the-art optimization methods in terms of AUC and Logloss metrics.
Sequential Sentence Matching Network for Multi-turn Response Selection in Retrieval-based Chatbots
May 16, 2020

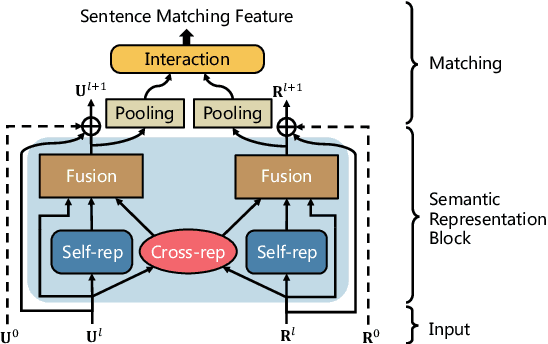

Recently, open domain multi-turn chatbots have attracted much interest from lots of researchers in both academia and industry. The dominant retrieval-based methods use context-response matching mechanisms for multi-turn response selection. Specifically, the state-of-the-art methods perform the context-response matching by word or segment similarity. However, these models lack a full exploitation of the sentence-level semantic information, and make simple mistakes that humans can easily avoid. In this work, we propose a matching network, called sequential sentence matching network (S2M), to use the sentence-level semantic information to address the problem. Firstly and most importantly, we find that by using the sentence-level semantic information, the network successfully addresses the problem and gets a significant improvement on matching, resulting in a state-of-the-art performance. Furthermore, we integrate the sentence matching we introduced here and the usual word similarity matching reported in the current literature, to match at different semantic levels. Experiments on three public data sets show that such integration further improves the model performance.