 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAST: Gradient-aligned Sparse Tuning of Large Language Models with Data-layer Selection
Mar 10, 2026Parameter-Efficient Fine-Tuning (PEFT) has become a key strategy for adapting large language models, with recent advances in sparse tuning reducing overhead by selectively updating key parameters or subsets of data. Existing approaches generally focus on two distinct paradigms: layer-selective methods aiming to fine-tune critical layers to minimize computational load, and data-selective methods aiming to select effective training subsets to boost training. However, current methods typically overlook the fact that different data points contribute varying degrees to distinct model layers, and they often discard potentially valuable information from data perceived as of low quality. To address these limitations, we propose Gradient-aligned Sparse Tuning (GAST), an innovative method that simultaneously performs selective fine-tuning at both data and layer dimensions as integral components of a unified optimization strategy. GAST specifically targets redundancy in information by employing a layer-sparse strategy that adaptively selects the most impactful data points for each layer, providing a more comprehensive and sophisticated solution than approaches restricted to a single dimension. Experiments demonstrate that GAST consistently outperforms baseline methods, establishing a promising direction for future research in PEFT strategies.
Bridge the Gap between Past and Future: Siamese Model Optimization for Context-Aware Document Ranking
May 20, 2025In the realm of information retrieval, users often engage in multi-turn interactions with search engines to acquire information, leading to the formation of sequences of user feedback behaviors. Leveraging the session context has proven to be beneficial for inferring user search intent and document ranking. A multitude of approaches have been proposed to exploit in-session context for improved document ranking. Despite these advances, the limitation of historical session data for capturing evolving user intent remains a challenge. In this work, we explore the integration of future contextual information into the session context to enhance document ranking. We present the siamese model optimization framework, comprising a history-conditioned model and a future-aware model. The former processes only the historical behavior sequence, while the latter integrates both historical and anticipated future behaviors. Both models are trained collaboratively using the supervised labels and pseudo labels predicted by the other. The history-conditioned model, referred to as ForeRanker, progressively learns future-relevant information to enhance ranking, while it singly uses historical session at inference time. To mitigate inconsistencies during training, we introduce the peer knowledge distillation method with a dynamic gating mechanism, allowing models to selectively incorporate contextual information. Experimental results on benchmark datasets demonstrate the effectiveness of our ForeRanker, showcasing its superior performance compared to existing methods.
Alleviating LLM-based Generative Retrieval Hallucination in Alipay Search
Mar 27, 2025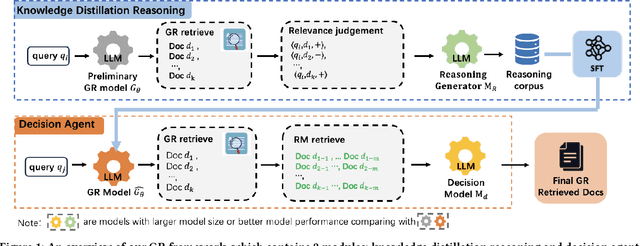
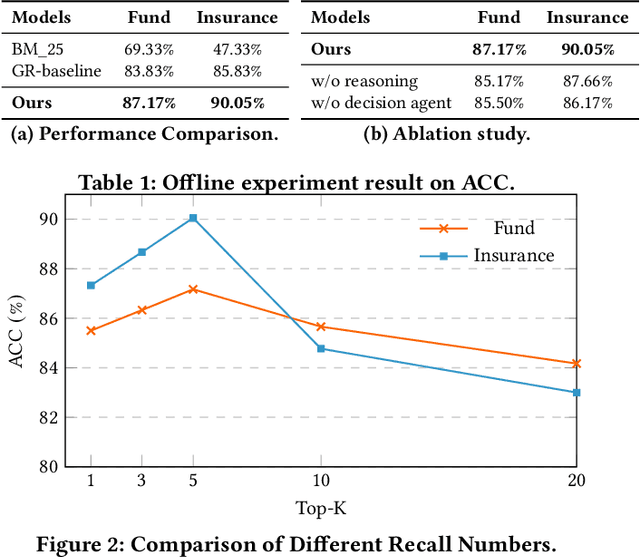

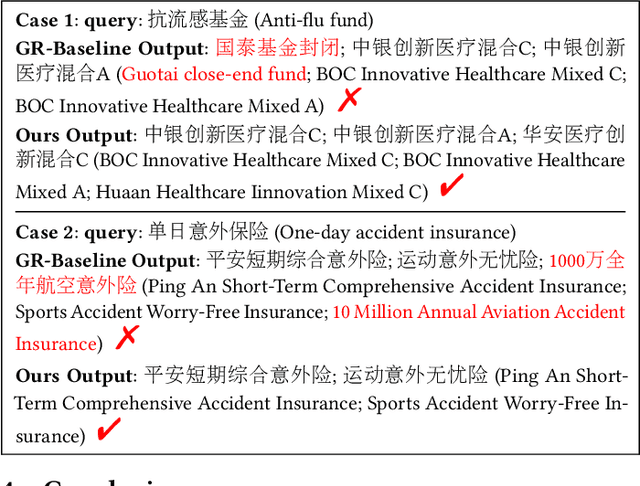
Generative retrieval (GR) has revolutionized document retrieval with the advent of large language models (LLMs), and LLM-based GR is gradually being adopted by the industry. Despite its remarkable advantages and potential, LLM-based GR suffers from hallucination and generates documents that are irrelevant to the query in some instances, severely challenging its credibility in practical applications. We thereby propose an optimized GR framework designed to alleviate retrieval hallucination, which integrates knowledge distillation reasoning in model training and incorporate decision agent to further improve retrieval precision. Specifically, we employ LLMs to assess and reason GR retrieved query-document (q-d) pairs, and then distill the reasoning data as transferred knowledge to the GR model. Moreover, we utilize a decision agent as post-processing to extend the GR retrieved documents through retrieval model and select the most relevant ones from multi perspectives as the final generative retrieval result. Extensive offline experiments on real-world datasets and online A/B tests on Fund Search and Insurance Search in Alipay demonstrate our framework's superiority and effectiveness in improving search quality and conversion gains.
Towards Boosting LLMs-driven Relevance Modeling with Progressive Retrieved Behavior-augmented Prompting
Aug 18, 2024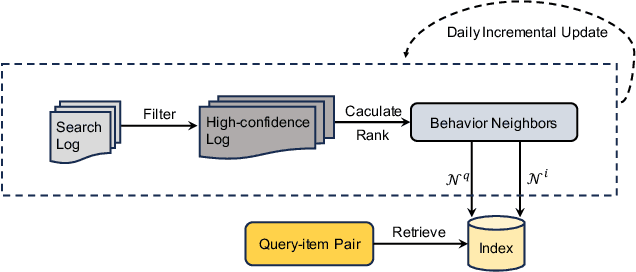

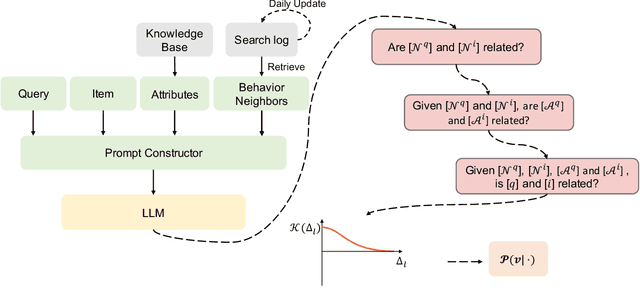
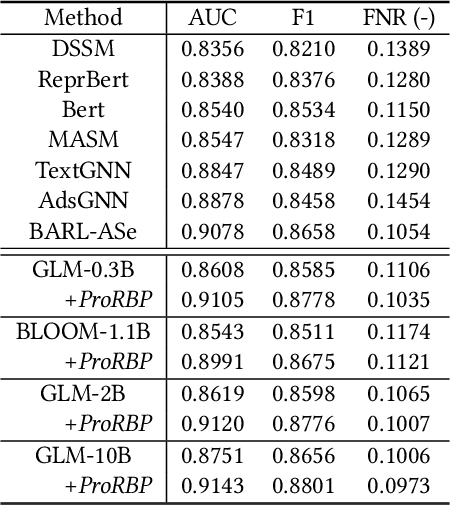
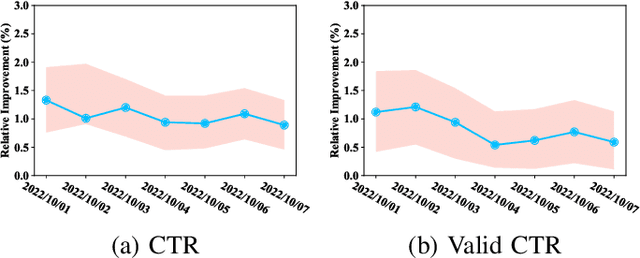
Relevance modeling is a critical component for enhancing user experience in search engines, with the primary objective of identifying items that align with users' queries. Traditional models only rely on the semantic congruence between queries and items to ascertain relevance. However, this approach represents merely one aspect of the relevance judgement, and is insufficient in isolation. Even powerful Large Language Models (LLMs) still cannot accurately judge the relevance of a query and an item from a semantic perspective. To augment LLMs-driven relevance modeling, this study proposes leveraging user interactions recorded in search logs to yield insights into users' implicit search intentions. The challenge lies in the effective prompting of LLMs to capture dynamic search intentions, which poses several obstacles in real-world relevance scenarios, i.e., the absence of domain-specific knowledge, the inadequacy of an isolated prompt, and the prohibitive costs associated with deploying LLMs. In response, we propose ProRBP, a novel Progressive Retrieved Behavior-augmented Prompting framework for integrating search scenario-oriented knowledge with LLMs effectively. Specifically, we perform the user-driven behavior neighbors retrieval from the daily search logs to obtain domain-specific knowledge in time, retrieving candidates that users consider to meet their expectations. Then, we guide LLMs for relevance modeling by employing advanced prompting techniques that progressively improve the outputs of the LLMs, followed by a progressive aggregation with comprehensive consideration of diverse aspects. For online serving, we have developed an industrial application framework tailored for the deployment of LLMs in relevance modeling. Experiments on real-world industry data and online A/B testing demonstrate our proposal achieves promising performance.
GARCIA: Powering Representations of Long-tail Query with Multi-granularity Contrastive Learning
Apr 25, 2023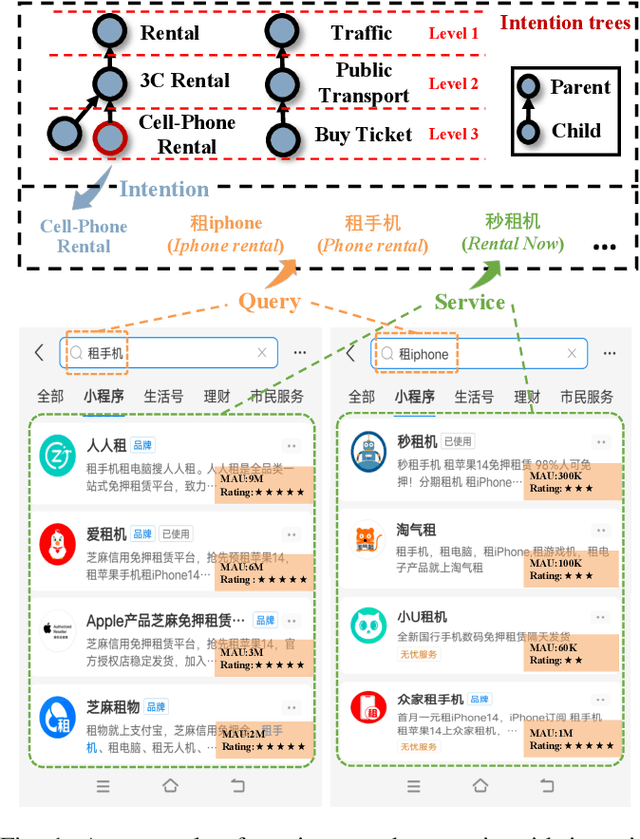
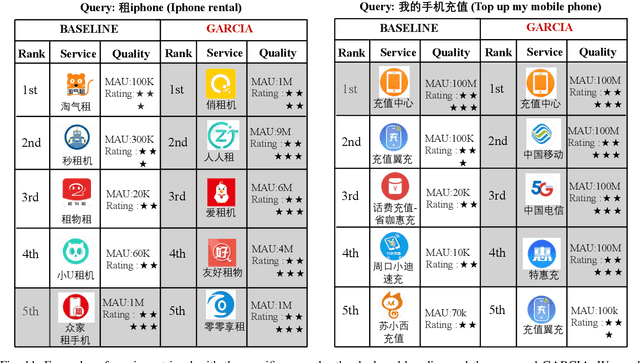
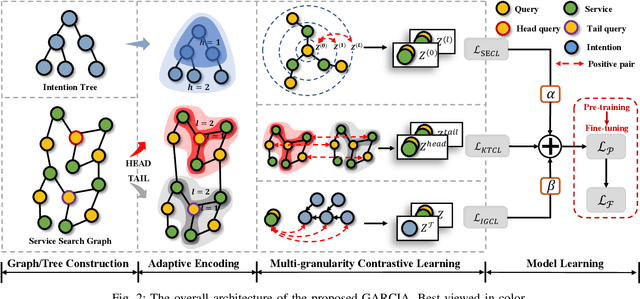
Recently, the growth of service platforms brings great convenience to both users and merchants, where the service search engine plays a vital role in improving the user experience by quickly obtaining desirable results via textual queries. Unfortunately, users' uncontrollable search customs usually bring vast amounts of long-tail queries, which severely threaten the capability of search models. Inspired by recently emerging graph neural networks (GNNs) and contrastive learning (CL), several efforts have been made in alleviating the long-tail issue and achieve considerable performance. Nevertheless, they still face a few major weaknesses. Most importantly, they do not explicitly utilize the contextual structure between heads and tails for effective knowledge transfer, and intention-level information is commonly ignored for more generalized representations. To this end, we develop a novel framework GARCIA, which exploits the graph based knowledge transfer and intention based representation generalization in a contrastive setting. In particular, we employ an adaptive encoder to produce informative representations for queries and services, as well as hierarchical structure aware representations of intentions. To fully understand tail queries and services, we equip GARCIA with a novel multi-granularity contrastive learning module, which powers representations through knowledge transfer, structure enhancement and intention generalization. Subsequently, the complete GARCIA is well trained in a pre-training&fine-tuning manner. At last, we conduct extensive experiments on both offline and online environments, which demonstrates the superior capability of GARCIA in improving tail queries and overall performance in service search scenarios.
DCMT: A Direct Entire-Space Causal Multi-Task Framework for Post-Click Conversion Estimation
Feb 13, 2023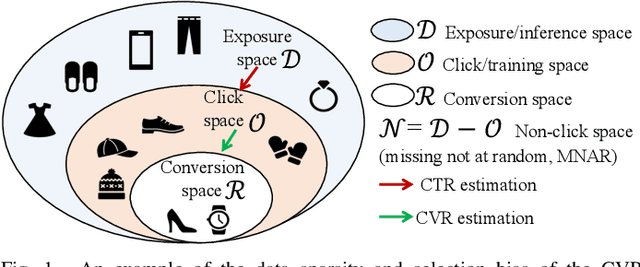
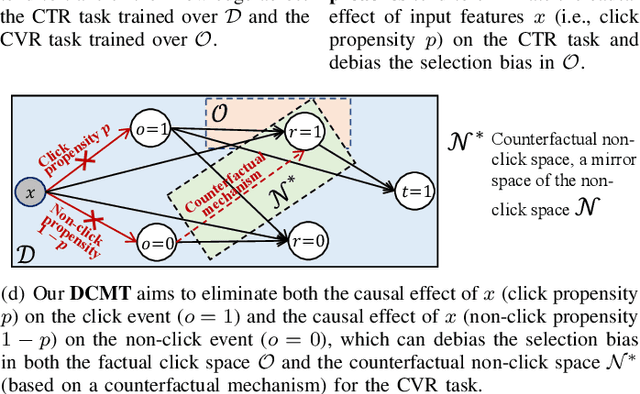
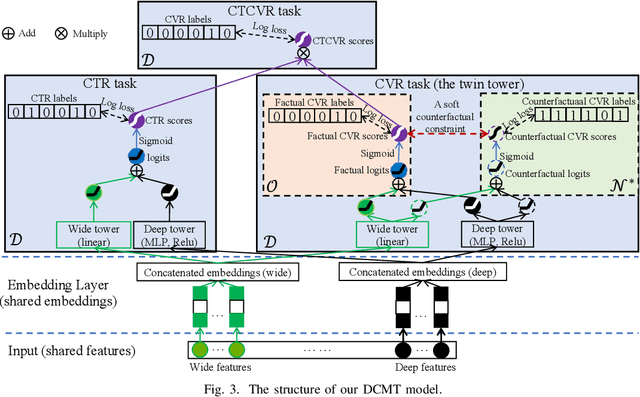

In recommendation scenarios, there are two long-standing challenges, i.e., selection bias and data sparsity, which lead to a significant drop in prediction accuracy for both Click-Through Rate (CTR) and post-click Conversion Rate (CVR) tasks. To cope with these issues, existing works emphasize on leveraging Multi-Task Learning (MTL) frameworks (Category 1) or causal debiasing frameworks (Category 2) to incorporate more auxiliary data in the entire exposure/inference space D or debias the selection bias in the click/training space O. However, these two kinds of solutions cannot effectively address the not-missing-at-random problem and debias the selection bias in O to fit the inference in D. To fill the research gaps, we propose a Direct entire-space Causal Multi-Task framework, namely DCMT, for post-click conversion prediction in this paper. Specifically, inspired by users' decision process of conversion, we propose a new counterfactual mechanism to debias the selection bias in D, which can predict the factual CVR and the counterfactual CVR under the soft constraint of a counterfactual prior knowledge. Extensive experiments demonstrate that our DCMT can improve the state-of-the-art methods by an average of 1.07% in terms of CVR AUC on the five offline datasets and 0.75% in terms of PV-CVR on the online A/B test (the Alipay Search). Such improvements can increase millions of conversions per week in real industrial applications, e.g., the Alipay Search.