 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Structure-Agnostic Co-Tuning Framework for LLMs and SLMs in Cloud-Edge Systems
Nov 12, 2025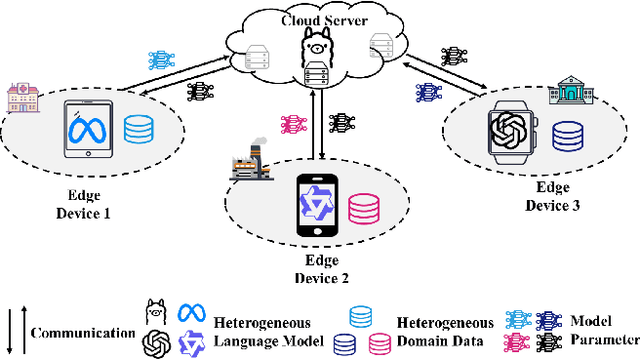
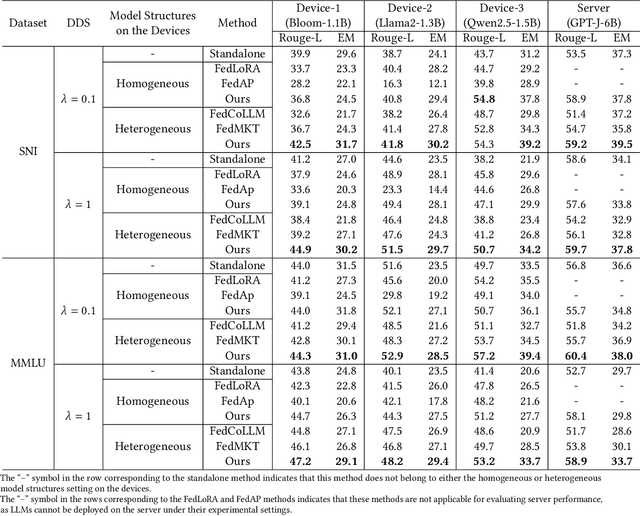
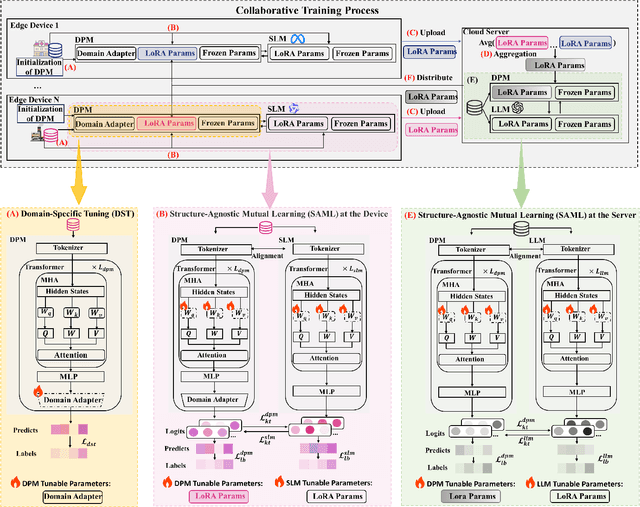
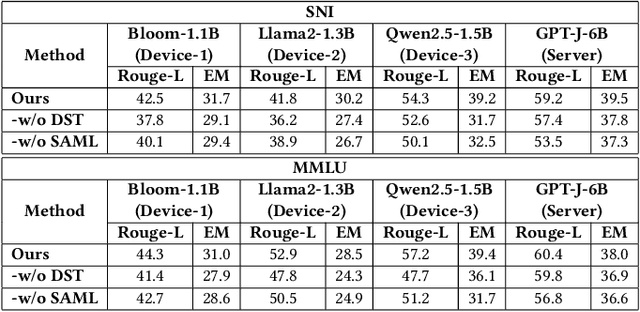
The surge in intelligent applications driven by large language models (LLMs) has made it increasingly difficult for bandwidth-limited cloud servers to process extensive LLM workloads in real time without compromising user data privacy. To solve these problems, recent research has focused on constructing cloud-edge consortia that integrate server-based LLM with small language models (SLMs) on mobile edge devices. Furthermore, designing collaborative training mechanisms within such consortia to enhance inference performance has emerged as a promising research direction. However, the cross-domain deployment of SLMs, coupled with structural heterogeneity in SLMs architectures, poses significant challenges to enhancing model performance. To this end, we propose Co-PLMs, a novel co-tuning framework for collaborative training of large and small language models, which integrates the process of structure-agnostic mutual learning to realize knowledge exchange between the heterogeneous language models. This framework employs distilled proxy models (DPMs) as bridges to enable collaborative training between the heterogeneous server-based LLM and on-device SLMs, while preserving the domain-specific insights of each device. The experimental results show that Co-PLMs outperform state-of-the-art methods, achieving average increases of 5.38% in Rouge-L and 4.88% in EM.
A Semi-Supervised Federated Learning Framework with Hierarchical Clustering Aggregation for Heterogeneous Satellite Networks
Jul 30, 2025



Low Earth Orbit (LEO) satellites are emerging as key components of 6G networks, with many already deployed to support large-scale Earth observation and sensing related tasks. Federated Learning (FL) presents a promising paradigm for enabling distributed intelligence in these resource-constrained and dynamic environments. However, achieving reliable convergence, while minimizing both processing time and energy consumption, remains a substantial challenge, particularly in heterogeneous and partially unlabeled satellite networks. To address this challenge, we propose a novel semi-supervised federated learning framework tailored for LEO satellite networks with hierarchical clustering aggregation. To further reduce communication overhead, we integrate sparsification and adaptive weight quantization techniques. In addition, we divide the FL clustering into two stages: satellite cluster aggregation stage and Ground Stations (GSs) aggregation stage. The supervised learning at GSs guides selected Parameter Server (PS) satellites, which in turn support fully unlabeled satellites during the federated training process. Extensive experiments conducted on a satellite network testbed demonstrate that our proposal can significantly reduce processing time (up to 3x) and energy consumption (up to 4x) compared to other comparative methods while maintaining model accuracy.
SAMA: Towards Multi-Turn Referential Grounded Video Chat with Large Language Models
May 24, 2025Achieving fine-grained spatio-temporal understanding in videos remains a major challenge for current Video Large Multimodal Models (Video LMMs). Addressing this challenge requires mastering two core capabilities: video referring understanding, which captures the semantics of video regions, and video grounding, which segments object regions based on natural language descriptions. However, most existing approaches tackle these tasks in isolation, limiting progress toward unified, referentially grounded video interaction. We identify a key bottleneck in the lack of high-quality, unified video instruction data and a comprehensive benchmark for evaluating referentially grounded video chat. To address these challenges, we contribute in three core aspects: dataset, model, and benchmark. First, we introduce SAMA-239K, a large-scale dataset comprising 15K videos specifically curated to enable joint learning of video referring understanding, grounding, and multi-turn video chat. Second, we propose the SAMA model, which incorporates a versatile spatio-temporal context aggregator and a Segment Anything Model to jointly enhance fine-grained video comprehension and precise grounding capabilities. Finally, we establish SAMA-Bench, a meticulously designed benchmark consisting of 5,067 questions from 522 videos, to comprehensively evaluate the integrated capabilities of Video LMMs in multi-turn, spatio-temporal referring understanding and grounded dialogue. Extensive experiments and benchmarking results show that SAMA not only achieves strong performance on SAMA-Bench but also sets a new state-of-the-art on general grounding benchmarks, while maintaining highly competitive performance on standard visual understanding benchmarks.
MetaSTH-Sleep: Towards Effective Few-Shot Sleep Stage Classification with Spatial-Temporal Hypergraph Enhanced Meta-Learning
May 22, 2025Accurate classification of sleep stages based on bio-signals is fundamental for automatic sleep stage annotation. Traditionally, this task relies on experienced clinicians to manually annotate data, a process that is both time-consuming and labor-intensive. In recent years, deep learning methods have shown promise in automating this task. However, three major challenges remain: (1) deep learning models typically require large-scale labeled datasets, making them less effective in real-world settings where annotated data is limited; (2) significant inter-individual variability in bio-signals often results in inconsistent model performance when applied to new subjects, limiting generalization; and (3) existing approaches often overlook the high-order relationships among bio-signals, failing to simultaneously capture signal heterogeneity and spatial-temporal dependencies. To address these issues, we propose MetaSTH-Sleep, a few-shot sleep stage classification framework based on spatial-temporal hypergraph enhanced meta-learning. Our approach enables rapid adaptation to new subjects using only a few labeled samples, while the hypergraph structure effectively models complex spatial interconnections and temporal dynamics simultaneously in EEG signals. Experimental results demonstrate that MetaSTH-Sleep achieves substantial performance improvements across diverse subjects, offering valuable insights to support clinicians in sleep stage annotation.
HyperMAN: Hypergraph-enhanced Meta-learning Adaptive Network for Next POI Recommendation
Mar 27, 2025Next Point-of-Interest (POI) recommendation aims to predict users' next locations by leveraging historical check-in sequences. Although existing methods have shown promising results, they often struggle to capture complex high-order relationships and effectively adapt to diverse user behaviors, particularly when addressing the cold-start issue. To address these challenges, we propose Hypergraph-enhanced Meta-learning Adaptive Network (HyperMAN), a novel framework that integrates heterogeneous hypergraph modeling with a difficulty-aware meta-learning mechanism for next POI recommendation. Specifically, three types of heterogeneous hyperedges are designed to capture high-order relationships: user visit behaviors at specific times (Temporal behavioral hyperedge), spatial correlations among POIs (spatial functional hyperedge), and user long-term preferences (user preference hyperedge). Furthermore, a diversity-aware meta-learning mechanism is introduced to dynamically adjust learning strategies, considering users behavioral diversity. Extensive experiments on real-world datasets demonstrate that HyperMAN achieves superior performance, effectively addressing cold start challenges and significantly enhancing recommendation accuracy.
Towards Constraint-Based Adaptive Hypergraph Learning for Solving Vehicle Routing: An End-to-End Solution
Mar 13, 2025



The application of learning based methods to vehicle routing problems has emerged as a pivotal area of research in combinatorial optimization. These problems are characterized by vast solution spaces and intricate constraints, making traditional approaches such as exact mathematical models or heuristic methods prone to high computational overhead or reliant on the design of complex heuristic operators to achieve optimal or near optimal solutions. Meanwhile, although some recent learning-based methods can produce good performance for VRP with straightforward constraint scenarios, they often fail to effectively handle hard constraints that are common in practice. This study introduces a novel end-to-end framework that combines constraint-oriented hypergraphs with reinforcement learning to address vehicle routing problems. A central innovation of this work is the development of a constraint-oriented dynamic hyperedge reconstruction strategy within an encoder, which significantly enhances hypergraph representation learning. Additionally, the decoder leverages a double-pointer attention mechanism to iteratively generate solutions. The proposed model is trained by incorporating asynchronous parameter updates informed by hypergraph constraints and optimizing a dual loss function comprising constraint loss and policy gradient loss. The experiment results on benchmark datasets demonstrate that the proposed approach not only eliminates the need for sophisticated heuristic operators but also achieves substantial improvements in solution quality.
GRL-Prompt: Towards Knowledge Graph based Prompt Optimization via Reinforcement Learning
Nov 19, 2024



Large language models (LLMs) have demonstrated impressive success in a wide range of natural language processing (NLP) tasks due to their extensive general knowledge of the world. Recent works discovered that the performance of LLMs is heavily dependent on the input prompt. However, prompt engineering is usually done manually in a trial-and-error fashion, which can be labor-intensive and challenging in order to find the optimal prompts. To address these problems and unleash the utmost potential of LLMs, we propose a novel LLMs-agnostic framework for prompt optimization, namely GRL-Prompt, which aims to automatically construct optimal prompts via reinforcement learning (RL) in an end-to-end manner. To provide structured action/state representation for optimizing prompts, we construct a knowledge graph (KG) that better encodes the correlation between the user query and candidate in-context examples. Furthermore, a policy network is formulated to generate the optimal action by selecting a set of in-context examples in a rewardable order to construct the prompt. Additionally, the embedding-based reward shaping is utilized to stabilize the RL training process. The experimental results show that GRL-Prompt outperforms recent state-of-the-art methods, achieving an average increase of 0.10 in ROUGE-1, 0.07 in ROUGE-2, 0.07 in ROUGE-L, and 0.05 in BLEU.
Leveraging Auxiliary Task Relevance for Enhanced Industrial Fault Diagnosis through Curriculum Meta-learning
Oct 27, 2024The accurate diagnosis of machine breakdowns is crucial for maintaining operational safety in smart manufacturing. Despite the promise shown by deep learning in automating fault identification, the scarcity of labeled training data, particularly for equipment failure instances, poses a significant challenge. This limitation hampers the development of robust classification models. Existing methods like model-agnostic meta-learning (MAML) do not adequately address variable working conditions, affecting knowledge transfer. To address these challenges, a Related Task Aware Curriculum Meta-learning (RT-ACM) enhanced fault diagnosis framework is proposed in this paper, inspired by human cognitive learning processes. RT-ACM improves training by considering the relevance of auxiliary working conditions, adhering to the principle of ``paying more attention to more relevant knowledge", and focusing on ``easier first, harder later" curriculum sampling. This approach aids the meta-learner in achieving a superior convergence state. Extensive experiments on two real-world datasets demonstrate the superiority of RT-ACM framework.
UnSeg: One Universal Unlearnable Example Generator is Enough against All Image Segmentation
Oct 13, 2024



Image segmentation is a crucial vision task that groups pixels within an image into semantically meaningful segments, which is pivotal in obtaining a fine-grained understanding of real-world scenes. However, an increasing privacy concern exists regarding training large-scale image segmentation models on unauthorized private data. In this work, we exploit the concept of unlearnable examples to make images unusable to model training by generating and adding unlearnable noise into the original images. Particularly, we propose a novel Unlearnable Segmentation (UnSeg) framework to train a universal unlearnable noise generator that is capable of transforming any downstream images into their unlearnable version. The unlearnable noise generator is finetuned from the Segment Anything Model (SAM) via bilevel optimization on an interactive segmentation dataset towards minimizing the training error of a surrogate model that shares the same architecture with SAM but is trained from scratch. We empirically verify the effectiveness of UnSeg across 6 mainstream image segmentation tasks, 10 widely used datasets, and 7 different network architectures, and show that the unlearnable images can reduce the segmentation performance by a large margin. Our work provides useful insights into how to leverage foundation models in a data-efficient and computationally affordable manner to protect images against image segmentation models.
HyperSMOTE: A Hypergraph-based Oversampling Approach for Imbalanced Node Classifications
Sep 09, 2024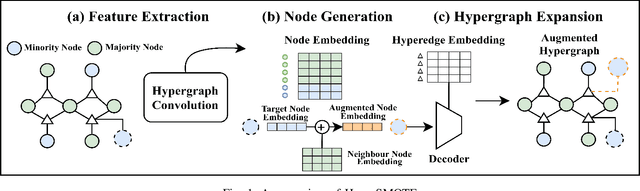
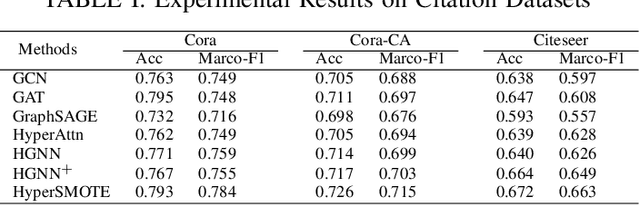
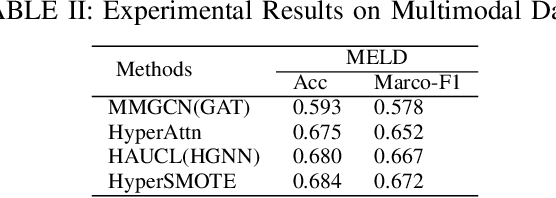
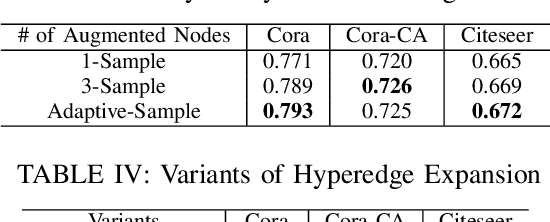
Hypergraphs are increasingly utilized in both unimodal and multimodal data scenarios due to their superior ability to model and extract higher-order relationships among nodes, compared to traditional graphs. However, current hypergraph models are encountering challenges related to imbalanced data, as this imbalance can lead to biases in the model towards the more prevalent classes. While the existing techniques, such as GraphSMOTE, have improved classification accuracy for minority samples in graph data, they still fall short when addressing the unique structure of hypergraphs. Inspired by SMOTE concept, we propose HyperSMOTE as a solution to alleviate the class imbalance issue in hypergraph learning. This method involves a two-step process: initially synthesizing minority class nodes, followed by the nodes integration into the original hypergraph. We synthesize new nodes based on samples from minority classes and their neighbors. At the same time, in order to solve the problem on integrating the new node into the hypergraph, we train a decoder based on the original hypergraph incidence matrix to adaptively associate the augmented node to hyperedges. We conduct extensive evaluation on multiple single-modality datasets, such as Cora, Cora-CA and Citeseer, as well as multimodal conversation dataset MELD to verify the effectiveness of HyperSMOTE, showing an average performance gain of 3.38% and 2.97% on accuracy, respectively.