 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Structure-Agnostic Co-Tuning Framework for LLMs and SLMs in Cloud-Edge Systems
Nov 12, 2025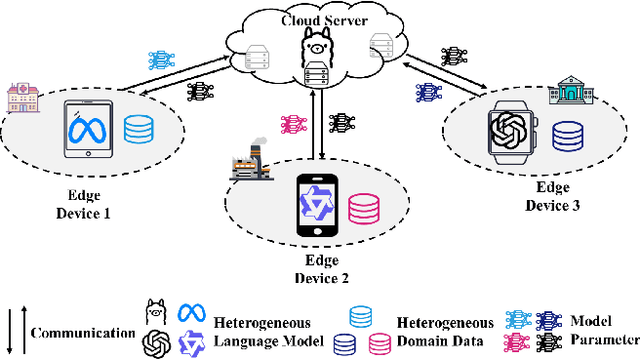
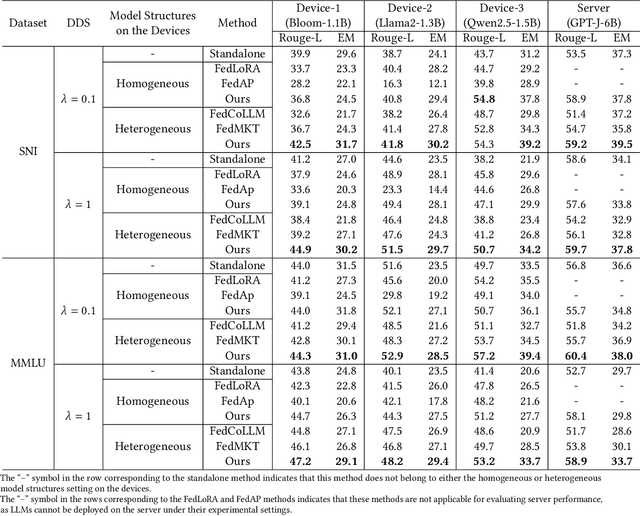
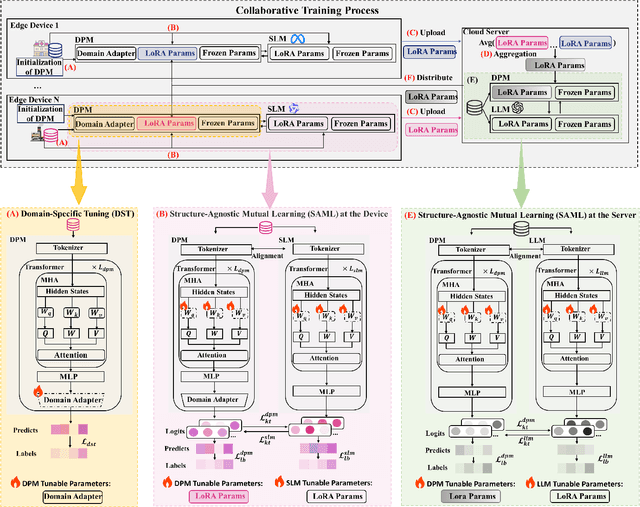
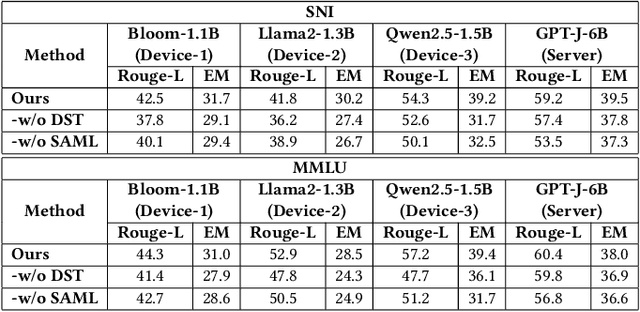
The surge in intelligent applications driven by large language models (LLMs) has made it increasingly difficult for bandwidth-limited cloud servers to process extensive LLM workloads in real time without compromising user data privacy. To solve these problems, recent research has focused on constructing cloud-edge consortia that integrate server-based LLM with small language models (SLMs) on mobile edge devices. Furthermore, designing collaborative training mechanisms within such consortia to enhance inference performance has emerged as a promising research direction. However, the cross-domain deployment of SLMs, coupled with structural heterogeneity in SLMs architectures, poses significant challenges to enhancing model performance. To this end, we propose Co-PLMs, a novel co-tuning framework for collaborative training of large and small language models, which integrates the process of structure-agnostic mutual learning to realize knowledge exchange between the heterogeneous language models. This framework employs distilled proxy models (DPMs) as bridges to enable collaborative training between the heterogeneous server-based LLM and on-device SLMs, while preserving the domain-specific insights of each device. The experimental results show that Co-PLMs outperform state-of-the-art methods, achieving average increases of 5.38% in Rouge-L and 4.88% in EM.
A Semi-Supervised Federated Learning Framework with Hierarchical Clustering Aggregation for Heterogeneous Satellite Networks
Jul 30, 2025



Low Earth Orbit (LEO) satellites are emerging as key components of 6G networks, with many already deployed to support large-scale Earth observation and sensing related tasks. Federated Learning (FL) presents a promising paradigm for enabling distributed intelligence in these resource-constrained and dynamic environments. However, achieving reliable convergence, while minimizing both processing time and energy consumption, remains a substantial challenge, particularly in heterogeneous and partially unlabeled satellite networks. To address this challenge, we propose a novel semi-supervised federated learning framework tailored for LEO satellite networks with hierarchical clustering aggregation. To further reduce communication overhead, we integrate sparsification and adaptive weight quantization techniques. In addition, we divide the FL clustering into two stages: satellite cluster aggregation stage and Ground Stations (GSs) aggregation stage. The supervised learning at GSs guides selected Parameter Server (PS) satellites, which in turn support fully unlabeled satellites during the federated training process. Extensive experiments conducted on a satellite network testbed demonstrate that our proposal can significantly reduce processing time (up to 3x) and energy consumption (up to 4x) compared to other comparative methods while maintaining model accuracy.
MetaSTH-Sleep: Towards Effective Few-Shot Sleep Stage Classification with Spatial-Temporal Hypergraph Enhanced Meta-Learning
May 22, 2025Accurate classification of sleep stages based on bio-signals is fundamental for automatic sleep stage annotation. Traditionally, this task relies on experienced clinicians to manually annotate data, a process that is both time-consuming and labor-intensive. In recent years, deep learning methods have shown promise in automating this task. However, three major challenges remain: (1) deep learning models typically require large-scale labeled datasets, making them less effective in real-world settings where annotated data is limited; (2) significant inter-individual variability in bio-signals often results in inconsistent model performance when applied to new subjects, limiting generalization; and (3) existing approaches often overlook the high-order relationships among bio-signals, failing to simultaneously capture signal heterogeneity and spatial-temporal dependencies. To address these issues, we propose MetaSTH-Sleep, a few-shot sleep stage classification framework based on spatial-temporal hypergraph enhanced meta-learning. Our approach enables rapid adaptation to new subjects using only a few labeled samples, while the hypergraph structure effectively models complex spatial interconnections and temporal dynamics simultaneously in EEG signals. Experimental results demonstrate that MetaSTH-Sleep achieves substantial performance improvements across diverse subjects, offering valuable insights to support clinicians in sleep stage annotation.
GRL-Prompt: Towards Knowledge Graph based Prompt Optimization via Reinforcement Learning
Nov 19, 2024



Large language models (LLMs) have demonstrated impressive success in a wide range of natural language processing (NLP) tasks due to their extensive general knowledge of the world. Recent works discovered that the performance of LLMs is heavily dependent on the input prompt. However, prompt engineering is usually done manually in a trial-and-error fashion, which can be labor-intensive and challenging in order to find the optimal prompts. To address these problems and unleash the utmost potential of LLMs, we propose a novel LLMs-agnostic framework for prompt optimization, namely GRL-Prompt, which aims to automatically construct optimal prompts via reinforcement learning (RL) in an end-to-end manner. To provide structured action/state representation for optimizing prompts, we construct a knowledge graph (KG) that better encodes the correlation between the user query and candidate in-context examples. Furthermore, a policy network is formulated to generate the optimal action by selecting a set of in-context examples in a rewardable order to construct the prompt. Additionally, the embedding-based reward shaping is utilized to stabilize the RL training process. The experimental results show that GRL-Prompt outperforms recent state-of-the-art methods, achieving an average increase of 0.10 in ROUGE-1, 0.07 in ROUGE-2, 0.07 in ROUGE-L, and 0.05 in BLEU.
HyperSMOTE: A Hypergraph-based Oversampling Approach for Imbalanced Node Classifications
Sep 09, 2024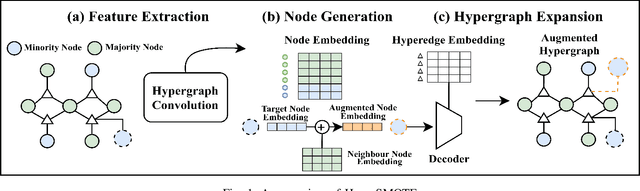
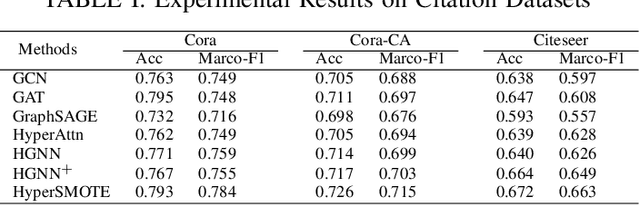
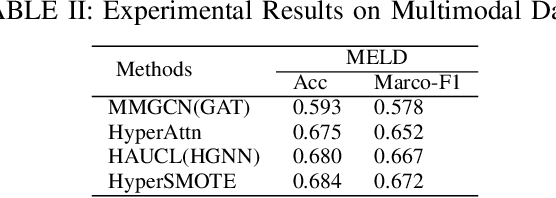
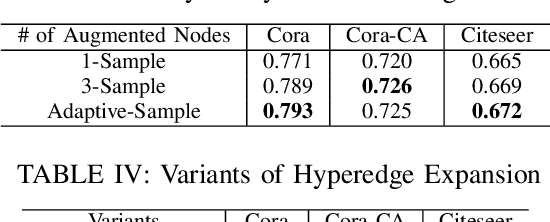
Hypergraphs are increasingly utilized in both unimodal and multimodal data scenarios due to their superior ability to model and extract higher-order relationships among nodes, compared to traditional graphs. However, current hypergraph models are encountering challenges related to imbalanced data, as this imbalance can lead to biases in the model towards the more prevalent classes. While the existing techniques, such as GraphSMOTE, have improved classification accuracy for minority samples in graph data, they still fall short when addressing the unique structure of hypergraphs. Inspired by SMOTE concept, we propose HyperSMOTE as a solution to alleviate the class imbalance issue in hypergraph learning. This method involves a two-step process: initially synthesizing minority class nodes, followed by the nodes integration into the original hypergraph. We synthesize new nodes based on samples from minority classes and their neighbors. At the same time, in order to solve the problem on integrating the new node into the hypergraph, we train a decoder based on the original hypergraph incidence matrix to adaptively associate the augmented node to hyperedges. We conduct extensive evaluation on multiple single-modality datasets, such as Cora, Cora-CA and Citeseer, as well as multimodal conversation dataset MELD to verify the effectiveness of HyperSMOTE, showing an average performance gain of 3.38% and 2.97% on accuracy, respectively.
CHASE: A Causal Heterogeneous Graph based Framework for Root Cause Analysis in Multimodal Microservice Systems
Jun 28, 2024In recent years, the widespread adoption of distributed microservice architectures within the industry has significantly increased the demand for enhanced system availability and robustness. Due to the complex service invocation paths and dependencies at enterprise-level microservice systems, it is challenging to locate the anomalies promptly during service invocations, thus causing intractable issues for normal system operations and maintenance. In this paper, we propose a Causal Heterogeneous grAph baSed framEwork for root cause analysis, namely CHASE, for microservice systems with multimodal data, including traces, logs, and system monitoring metrics. Specifically, related information is encoded into representative embeddings and further modeled by a multimodal invocation graph. Following that, anomaly detection is performed on each instance node with attentive heterogeneous message passing from its adjacent metric and log nodes. Finally, CHASE learns from the constructed hypergraph with hyperedges representing the flow of causality and performs root cause localization. We evaluate the proposed framework on two public microservice datasets with distinct attributes and compare with the state-of-the-art methods. The results show that CHASE achieves the average performance gain up to 36.2%(A@1) and 29.4%(Percentage@1), respectively to its best counterpart.
Exploiting Spatial-temporal Data for Sleep Stage Classification via Hypergraph Learning
Sep 05, 2023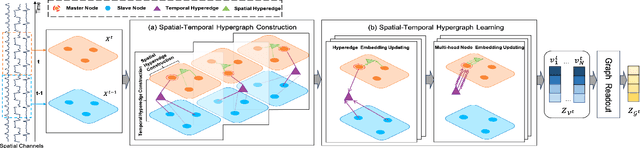
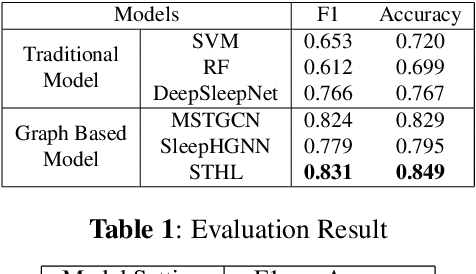

Sleep stage classification is crucial for detecting patients' health conditions. Existing models, which mainly use Convolutional Neural Networks (CNN) for modelling Euclidean data and Graph Convolution Networks (GNN) for modelling non-Euclidean data, are unable to consider the heterogeneity and interactivity of multimodal data as well as the spatial-temporal correlation simultaneously, which hinders a further improvement of classification performance. In this paper, we propose a dynamic learning framework STHL, which introduces hypergraph to encode spatial-temporal data for sleep stage classification. Hypergraphs can construct multi-modal/multi-type data instead of using simple pairwise between two subjects. STHL creates spatial and temporal hyperedges separately to build node correlations, then it conducts type-specific hypergraph learning process to encode the attributes into the embedding space. Extensive experiments show that our proposed STHL outperforms the state-of-the-art models in sleep stage classification tasks.
Learning from Heterogeneity: A Dynamic Learning Framework for Hypergraphs
Jul 07, 2023
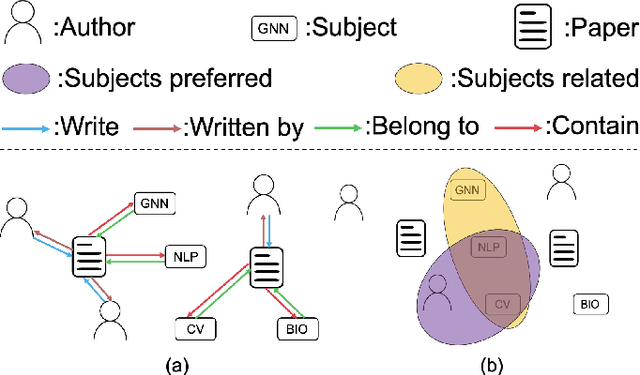
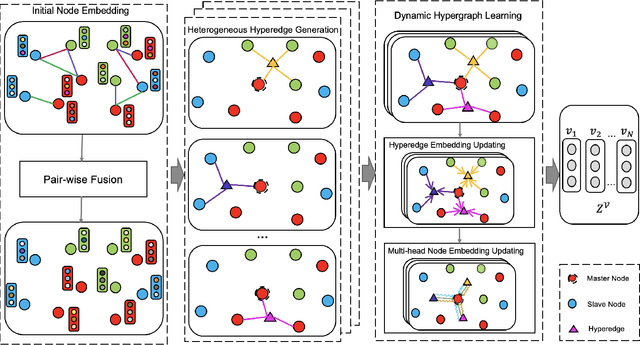
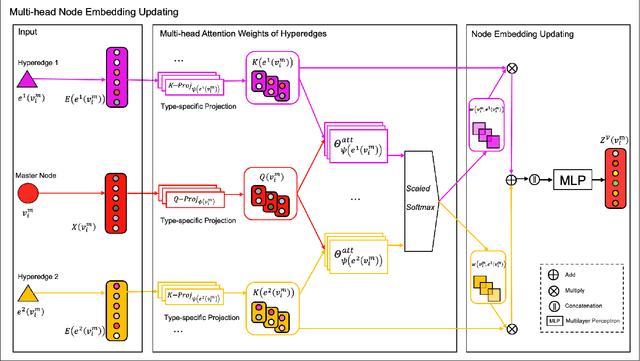
Graph neural network (GNN) has gained increasing popularity in recent years owing to its capability and flexibility in modeling complex graph structure data. Among all graph learning methods, hypergraph learning is a technique for exploring the implicit higher-order correlations when training the embedding space of the graph. In this paper, we propose a hypergraph learning framework named LFH that is capable of dynamic hyperedge construction and attentive embedding update utilizing the heterogeneity attributes of the graph. Specifically, in our framework, the high-quality features are first generated by the pairwise fusion strategy that utilizes explicit graph structure information when generating initial node embedding. Afterwards, a hypergraph is constructed through the dynamic grouping of implicit hyperedges, followed by the type-specific hypergraph learning process. To evaluate the effectiveness of our proposed framework, we conduct comprehensive experiments on several popular datasets with eleven state-of-the-art models on both node classification and link prediction tasks, which fall into categories of homogeneous pairwise graph learning, heterogeneous pairwise graph learning, and hypergraph learning. The experiment results demonstrate a significant performance gain (average 12.5% in node classification and 13.3% in link prediction) compared with recent state-of-the-art methods.
FedRel: An Adaptive Federated Relevance Framework for Spatial Temporal Graph Learning
Jun 07, 2022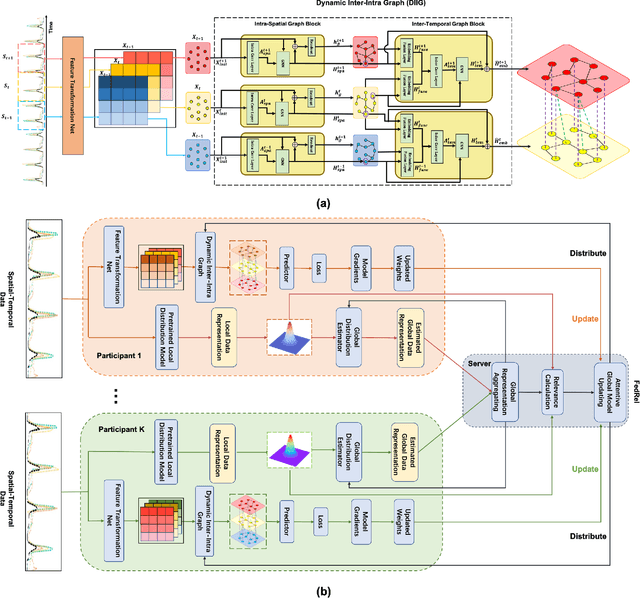
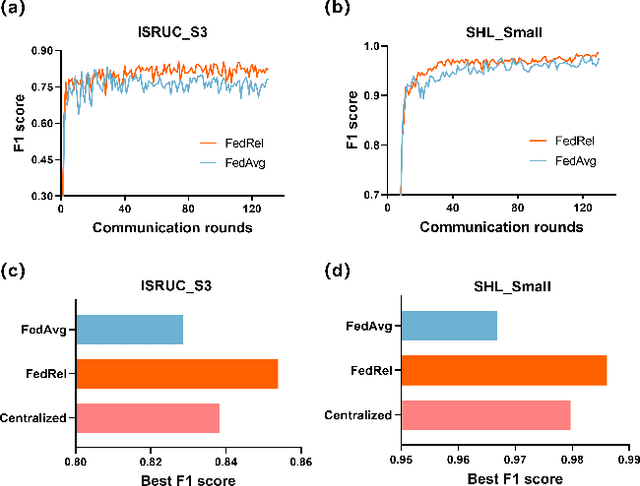

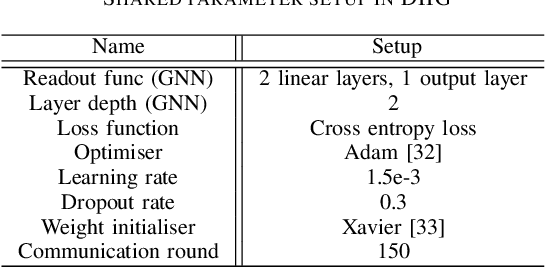
Spatial-temporal data contains rich information and has been widely studied in recent years due to the rapid development of relevant applications in many fields. For instance, medical institutions often use electrodes attached to different parts of a patient to analyse the electorencephal data rich with spatial and temporal features for health assessment and disease diagnosis. Existing research has mainly used deep learning techniques such as convolutional neural network (CNN) or recurrent neural network (RNN) to extract hidden spatial-temporal features. Yet, it is challenging to incorporate both inter-dependencies spatial information and dynamic temporal changes simultaneously. In reality, for a model that leverages these spatial-temporal features to fulfil complex prediction tasks, it often requires a colossal amount of training data in order to obtain satisfactory model performance. Considering the above-mentioned challenges, we propose an adaptive federated relevance framework, namely FedRel, for spatial-temporal graph learning in this paper. After transforming the raw spatial-temporal data into high quality features, the core Dynamic Inter-Intra Graph (DIIG) module in the framework is able to use these features to generate the spatial-temporal graphs capable of capturing the hidden topological and long-term temporal correlation information in these graphs. To improve the model generalization ability and performance while preserving the local data privacy, we also design a relevance-driven federated learning module in our framework to leverage diverse data distributions from different participants with attentive aggregations of their models.