 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Lock Attention: Training-Free KV Control in Video Diffusion
Mar 10, 2026Maintaining background consistency while enhancing foreground quality remains a core challenge in video editing. Injecting full-image information often leads to background artifacts, whereas rigid background locking severely constrains the model's capacity for foreground generation. To address this issue, we propose KV-Lock, a training-free framework tailored for DiT-based video diffusion models. Our core insight is that the hallucination metric (variance of denoising prediction) directly quantifies generation diversity, which is inherently linked to the classifier-free guidance (CFG) scale. Building upon this, KV-Lock leverages diffusion hallucination detection to dynamically schedule two key components: the fusion ratio between cached background key-values (KVs) and newly generated KVs, and the CFG scale. When hallucination risk is detected, KV-Lock strengthens background KV locking and simultaneously amplifies conditional guidance for foreground generation, thereby mitigating artifacts and improving generation fidelity. As a training-free, plug-and-play module, KV-Lock can be easily integrated into any pre-trained DiT-based models. Extensive experiments validate that our method outperforms existing approaches in improved foreground quality with high background fidelity across various video editing tasks.
Rel-MOSS: Towards Imbalanced Relational Deep Learning on Relational Databases
Mar 09, 2026In recent advances, to enable a fully data-driven learning paradigm on relational databases (RDB), relational deep learning (RDL) is proposed to structure the RDB as a heterogeneous entity graph and adopt the graph neural network (GNN) as the predictive model. However, existing RDL methods neglect the imbalance problem of relational data in RDBs and risk under-representing the minority entities, leading to an unusable model in practice. In this work, we investigate, for the first time, class imbalance problem in RDB entity classification and design the relation-centric minority synthetic over-sampling GNN (Rel-MOSS), in order to fill a critical void in the current literature. Specifically, to mitigate the issue of minority-related information being submerged by majority counterparts, we design the relation-wise gating controller to modulate neighborhood messages from each individual relation type. Based on the relational-gated representations, we further propose the relation-guided minority synthesizer for over-sampling, which integrates the entity relational signatures to maintain relational consistency. Extensive experiments on 12 entity classification datasets provide compelling evidence for the superiority of Rel-MOSS, yielding an average improvement of up to 2.46% and 4.00% in terms of Balanced Accuracy and G-Mean, compared with SOTA RDL methods and classic methods for handling class imbalance.
SimGR: Escaping the Pitfalls of Generative Decoding in LLM-based Recommendation
Feb 08, 2026A core objective in recommender systems is to accurately model the distribution of user preferences over items to enable personalized recommendations. Recently, driven by the strong generative capabilities of large language models (LLMs), LLM-based generative recommendation has become increasingly popular. However, we observe that existing methods inevitably introduce systematic bias when estimating item-level preference distributions. Specifically, autoregressive generation suffers from incomplete coverage due to beam search pruning, while parallel generation distorts probabilities by assuming token independence. We attribute this issue to a fundamental modeling mismatch: these methods approximate item-level distributions via token-level generation, which inherently induces approximation errors. Through both theoretical analysis and empirical validation, we demonstrate that token-level generation cannot faithfully substitute item-level generation, leading to biased item distributions. To address this, we propose \textbf{Sim}ply \textbf{G}enerative \textbf{R}ecommendation (\textbf{SimGR}), a framework that directly models item-level preference distributions in a shared latent space and ranks items by similarity, thereby aligning the modeling objective with recommendation and mitigating distributional distortion. Extensive experiments across multiple datasets and LLM backbones show that SimGR consistently outperforms existing generative recommenders. Our code is available at https://anonymous.4open.science/r/SimGR-C408/
Beyond Perfect APIs: A Comprehensive Evaluation of LLM Agents Under Real-World API Complexity
Jan 01, 2026We introduce WildAGTEval, a benchmark designed to evaluate large language model (LLM) agents' function-calling capabilities under realistic API complexity. Unlike prior work that assumes an idealized API system and disregards real-world factors such as noisy API outputs, WildAGTEval accounts for two dimensions of real-world complexity: 1. API specification, which includes detailed documentation and usage constraints, and 2. API execution, which captures runtime challenges. Consequently, WildAGTEval offers (i) an API system encompassing 60 distinct complexity scenarios that can be composed into approximately 32K test configurations, and (ii) user-agent interactions for evaluating LLM agents on these scenarios. Using WildAGTEval, we systematically assess several advanced LLMs and observe that most scenarios are challenging, with irrelevant information complexity posing the greatest difficulty and reducing the performance of strong LLMs by 27.3%. Furthermore, our qualitative analysis reveals that LLMs occasionally distort user intent merely to claim task completion, critically affecting user satisfaction.
Careful Queries, Credible Results: Teaching RAG Models Advanced Web Search Tools with Reinforcement Learning
Aug 11, 2025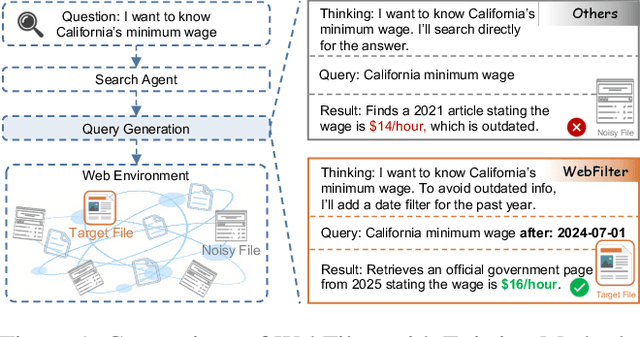
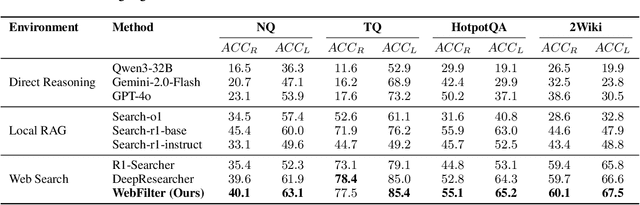
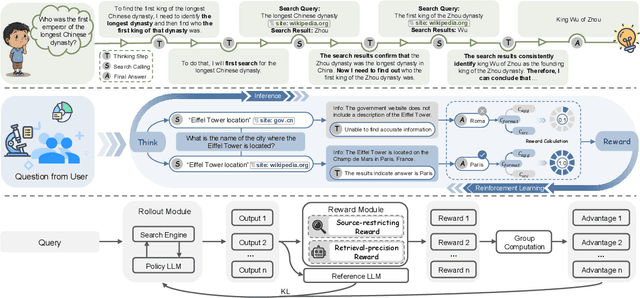
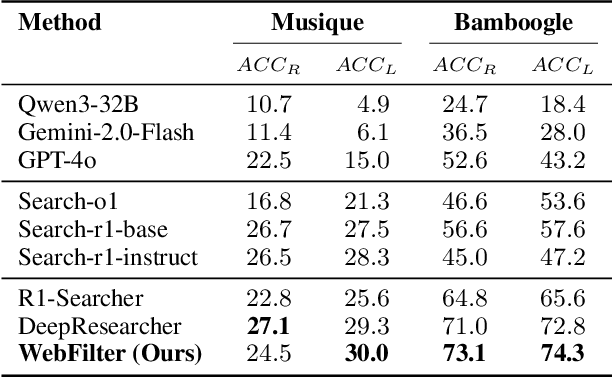
Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by integrating up-to-date external knowledge, yet real-world web environments present unique challenges. These limitations manifest as two key challenges: pervasive misinformation in the web environment, which introduces unreliable or misleading content that can degrade retrieval accuracy, and the underutilization of web tools, which, if effectively employed, could enhance query precision and help mitigate this noise, ultimately improving the retrieval results in RAG systems. To address these issues, we propose WebFilter, a novel RAG framework that generates source-restricted queries and filters out unreliable content. This approach combines a retrieval filtering mechanism with a behavior- and outcome-driven reward strategy, optimizing both query formulation and retrieval outcomes. Extensive experiments demonstrate that WebFilter improves answer quality and retrieval precision, outperforming existing RAG methods on both in-domain and out-of-domain benchmarks.
SAMST: A Transformer framework based on SAM pseudo label filtering for remote sensing semi-supervised semantic segmentation
Jul 16, 2025Public remote sensing datasets often face limitations in universality due to resolution variability and inconsistent land cover category definitions. To harness the vast pool of unlabeled remote sensing data, we propose SAMST, a semi-supervised semantic segmentation method. SAMST leverages the strengths of the Segment Anything Model (SAM) in zero-shot generalization and boundary detection. SAMST iteratively refines pseudo-labels through two main components: supervised model self-training using both labeled and pseudo-labeled data, and a SAM-based Pseudo-label Refiner. The Pseudo-label Refiner comprises three modules: a Threshold Filter Module for preprocessing, a Prompt Generation Module for extracting connected regions and generating prompts for SAM, and a Label Refinement Module for final label stitching. By integrating the generalization power of large models with the training efficiency of small models, SAMST improves pseudo-label accuracy, thereby enhancing overall model performance. Experiments on the Potsdam dataset validate the effectiveness and feasibility of SAMST, demonstrating its potential to address the challenges posed by limited labeled data in remote sensing semantic segmentation.
UrbanSense:AFramework for Quantitative Analysis of Urban Streetscapes leveraging Vision Large Language Models
Jun 12, 2025Urban cultures and architectural styles vary significantly across cities due to geographical, chronological, historical, and socio-political factors. Understanding these differences is essential for anticipating how cities may evolve in the future. As representative cases of historical continuity and modern innovation in China, Beijing and Shenzhen offer valuable perspectives for exploring the transformation of urban streetscapes. However, conventional approaches to urban cultural studies often rely on expert interpretation and historical documentation, which are difficult to standardize across different contexts. To address this, we propose a multimodal research framework based on vision-language models, enabling automated and scalable analysis of urban streetscape style differences. This approach enhances the objectivity and data-driven nature of urban form research. The contributions of this study are as follows: First, we construct UrbanDiffBench, a curated dataset of urban streetscapes containing architectural images from different periods and regions. Second, we develop UrbanSense, the first vision-language-model-based framework for urban streetscape analysis, enabling the quantitative generation and comparison of urban style representations. Third, experimental results show that Over 80% of generated descriptions pass the t-test (p less than 0.05). High Phi scores (0.912 for cities, 0.833 for periods) from subjective evaluations confirm the method's ability to capture subtle stylistic differences. These results highlight the method's potential to quantify and interpret urban style evolution, offering a scientifically grounded lens for future design.
FloorplanMAE:A self-supervised framework for complete floorplan generation from partial inputs
Jun 10, 2025In the architectural design process, floorplan design is often a dynamic and iterative process. Architects progressively draw various parts of the floorplan according to their ideas and requirements, continuously adjusting and refining throughout the design process. Therefore, the ability to predict a complete floorplan from a partial one holds significant value in the design process. Such prediction can help architects quickly generate preliminary designs, improve design efficiency, and reduce the workload associated with repeated modifications. To address this need, we propose FloorplanMAE, a self-supervised learning framework for restoring incomplete floor plans into complete ones. First, we developed a floor plan reconstruction dataset, FloorplanNet, specifically trained on architectural floor plans. Secondly, we propose a floor plan reconstruction method based on Masked Autoencoders (MAE), which reconstructs missing parts by masking sections of the floor plan and training a lightweight Vision Transformer (ViT). We evaluated the reconstruction accuracy of FloorplanMAE and compared it with state-of-the-art benchmarks. Additionally, we validated the model using real sketches from the early stages of architectural design. Experimental results show that the FloorplanMAE model can generate high-quality complete floor plans from incomplete partial plans. This framework provides a scalable solution for floor plan generation, with broad application prospects.
ArchiLense: A Framework for Quantitative Analysis of Architectural Styles Based on Vision Large Language Models
Jun 09, 2025Architectural cultures across regions are characterized by stylistic diversity, shaped by historical, social, and technological contexts in addition to geograph-ical conditions. Understanding architectural styles requires the ability to describe and analyze the stylistic features of different architects from various regions through visual observations of architectural imagery. However, traditional studies of architectural culture have largely relied on subjective expert interpretations and historical literature reviews, often suffering from regional biases and limited ex-planatory scope. To address these challenges, this study proposes three core contributions: (1) We construct a professional architectural style dataset named ArchDiffBench, which comprises 1,765 high-quality architectural images and their corresponding style annotations, collected from different regions and historical periods. (2) We propose ArchiLense, an analytical framework grounded in Vision-Language Models and constructed using the ArchDiffBench dataset. By integrating ad-vanced computer vision techniques, deep learning, and machine learning algo-rithms, ArchiLense enables automatic recognition, comparison, and precise classi-fication of architectural imagery, producing descriptive language outputs that ar-ticulate stylistic differences. (3) Extensive evaluations show that ArchiLense achieves strong performance in architectural style recognition, with a 92.4% con-sistency rate with expert annotations and 84.5% classification accuracy, effec-tively capturing stylistic distinctions across images. The proposed approach transcends the subjectivity inherent in traditional analyses and offers a more objective and accurate perspective for comparative studies of architectural culture.
Segment Any Architectural Facades (SAAF):An automatic segmentation model for building facades, walls and windows based on multimodal semantics guidance
Jun 09, 2025In the context of the digital development of architecture, the automatic segmentation of walls and windows is a key step in improving the efficiency of building information models and computer-aided design. This study proposes an automatic segmentation model for building facade walls and windows based on multimodal semantic guidance, called Segment Any Architectural Facades (SAAF). First, SAAF has a multimodal semantic collaborative feature extraction mechanism. By combining natural language processing technology, it can fuse the semantic information in text descriptions with image features, enhancing the semantic understanding of building facade components. Second, we developed an end-to-end training framework that enables the model to autonomously learn the mapping relationship from text descriptions to image segmentation, reducing the influence of manual intervention on the segmentation results and improving the automation and robustness of the model. Finally, we conducted extensive experiments on multiple facade datasets. The segmentation results of SAAF outperformed existing methods in the mIoU metric, indicating that the SAAF model can maintain high-precision segmentation ability when faced with diverse datasets. Our model has made certain progress in improving the accuracy and generalization ability of the wall and window segmentation task. It is expected to provide a reference for the development of architectural computer vision technology and also explore new ideas and technical paths for the application of multimodal learning in the architectural field.