 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCareful Queries, Credible Results: Teaching RAG Models Advanced Web Search Tools with Reinforcement Learning
Aug 11, 2025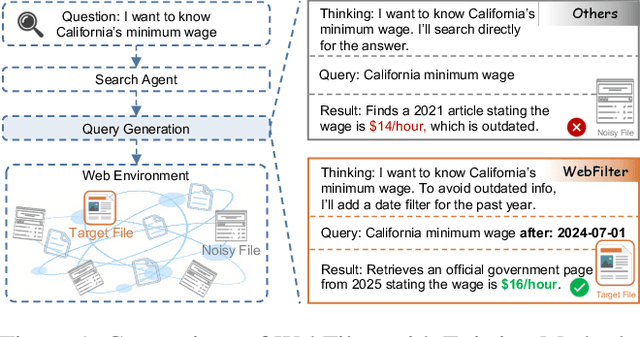
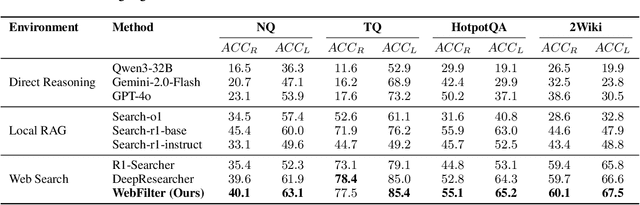
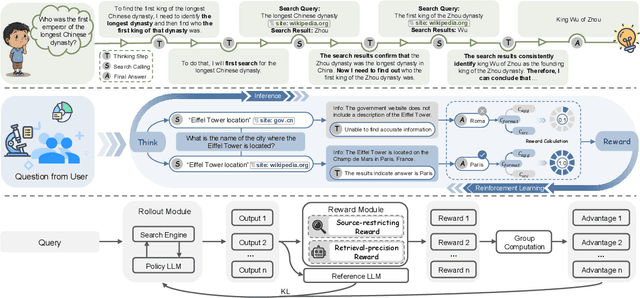
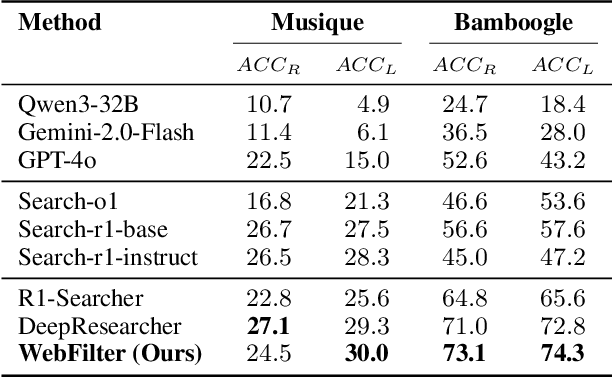
Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by integrating up-to-date external knowledge, yet real-world web environments present unique challenges. These limitations manifest as two key challenges: pervasive misinformation in the web environment, which introduces unreliable or misleading content that can degrade retrieval accuracy, and the underutilization of web tools, which, if effectively employed, could enhance query precision and help mitigate this noise, ultimately improving the retrieval results in RAG systems. To address these issues, we propose WebFilter, a novel RAG framework that generates source-restricted queries and filters out unreliable content. This approach combines a retrieval filtering mechanism with a behavior- and outcome-driven reward strategy, optimizing both query formulation and retrieval outcomes. Extensive experiments demonstrate that WebFilter improves answer quality and retrieval precision, outperforming existing RAG methods on both in-domain and out-of-domain benchmarks.
UrbanSense:AFramework for Quantitative Analysis of Urban Streetscapes leveraging Vision Large Language Models
Jun 12, 2025Urban cultures and architectural styles vary significantly across cities due to geographical, chronological, historical, and socio-political factors. Understanding these differences is essential for anticipating how cities may evolve in the future. As representative cases of historical continuity and modern innovation in China, Beijing and Shenzhen offer valuable perspectives for exploring the transformation of urban streetscapes. However, conventional approaches to urban cultural studies often rely on expert interpretation and historical documentation, which are difficult to standardize across different contexts. To address this, we propose a multimodal research framework based on vision-language models, enabling automated and scalable analysis of urban streetscape style differences. This approach enhances the objectivity and data-driven nature of urban form research. The contributions of this study are as follows: First, we construct UrbanDiffBench, a curated dataset of urban streetscapes containing architectural images from different periods and regions. Second, we develop UrbanSense, the first vision-language-model-based framework for urban streetscape analysis, enabling the quantitative generation and comparison of urban style representations. Third, experimental results show that Over 80% of generated descriptions pass the t-test (p less than 0.05). High Phi scores (0.912 for cities, 0.833 for periods) from subjective evaluations confirm the method's ability to capture subtle stylistic differences. These results highlight the method's potential to quantify and interpret urban style evolution, offering a scientifically grounded lens for future design.
FloorplanMAE:A self-supervised framework for complete floorplan generation from partial inputs
Jun 10, 2025In the architectural design process, floorplan design is often a dynamic and iterative process. Architects progressively draw various parts of the floorplan according to their ideas and requirements, continuously adjusting and refining throughout the design process. Therefore, the ability to predict a complete floorplan from a partial one holds significant value in the design process. Such prediction can help architects quickly generate preliminary designs, improve design efficiency, and reduce the workload associated with repeated modifications. To address this need, we propose FloorplanMAE, a self-supervised learning framework for restoring incomplete floor plans into complete ones. First, we developed a floor plan reconstruction dataset, FloorplanNet, specifically trained on architectural floor plans. Secondly, we propose a floor plan reconstruction method based on Masked Autoencoders (MAE), which reconstructs missing parts by masking sections of the floor plan and training a lightweight Vision Transformer (ViT). We evaluated the reconstruction accuracy of FloorplanMAE and compared it with state-of-the-art benchmarks. Additionally, we validated the model using real sketches from the early stages of architectural design. Experimental results show that the FloorplanMAE model can generate high-quality complete floor plans from incomplete partial plans. This framework provides a scalable solution for floor plan generation, with broad application prospects.
Segment Any Architectural Facades (SAAF):An automatic segmentation model for building facades, walls and windows based on multimodal semantics guidance
Jun 09, 2025In the context of the digital development of architecture, the automatic segmentation of walls and windows is a key step in improving the efficiency of building information models and computer-aided design. This study proposes an automatic segmentation model for building facade walls and windows based on multimodal semantic guidance, called Segment Any Architectural Facades (SAAF). First, SAAF has a multimodal semantic collaborative feature extraction mechanism. By combining natural language processing technology, it can fuse the semantic information in text descriptions with image features, enhancing the semantic understanding of building facade components. Second, we developed an end-to-end training framework that enables the model to autonomously learn the mapping relationship from text descriptions to image segmentation, reducing the influence of manual intervention on the segmentation results and improving the automation and robustness of the model. Finally, we conducted extensive experiments on multiple facade datasets. The segmentation results of SAAF outperformed existing methods in the mIoU metric, indicating that the SAAF model can maintain high-precision segmentation ability when faced with diverse datasets. Our model has made certain progress in improving the accuracy and generalization ability of the wall and window segmentation task. It is expected to provide a reference for the development of architectural computer vision technology and also explore new ideas and technical paths for the application of multimodal learning in the architectural field.
ArchiLense: A Framework for Quantitative Analysis of Architectural Styles Based on Vision Large Language Models
Jun 09, 2025Architectural cultures across regions are characterized by stylistic diversity, shaped by historical, social, and technological contexts in addition to geograph-ical conditions. Understanding architectural styles requires the ability to describe and analyze the stylistic features of different architects from various regions through visual observations of architectural imagery. However, traditional studies of architectural culture have largely relied on subjective expert interpretations and historical literature reviews, often suffering from regional biases and limited ex-planatory scope. To address these challenges, this study proposes three core contributions: (1) We construct a professional architectural style dataset named ArchDiffBench, which comprises 1,765 high-quality architectural images and their corresponding style annotations, collected from different regions and historical periods. (2) We propose ArchiLense, an analytical framework grounded in Vision-Language Models and constructed using the ArchDiffBench dataset. By integrating ad-vanced computer vision techniques, deep learning, and machine learning algo-rithms, ArchiLense enables automatic recognition, comparison, and precise classi-fication of architectural imagery, producing descriptive language outputs that ar-ticulate stylistic differences. (3) Extensive evaluations show that ArchiLense achieves strong performance in architectural style recognition, with a 92.4% con-sistency rate with expert annotations and 84.5% classification accuracy, effec-tively capturing stylistic distinctions across images. The proposed approach transcends the subjectivity inherent in traditional analyses and offers a more objective and accurate perspective for comparative studies of architectural culture.
A DSP-Free Carrier Phase Recovery System using 16-Offset-QAM Laser Forwarded Links for 400Gb/s and Beyond
May 24, 2025

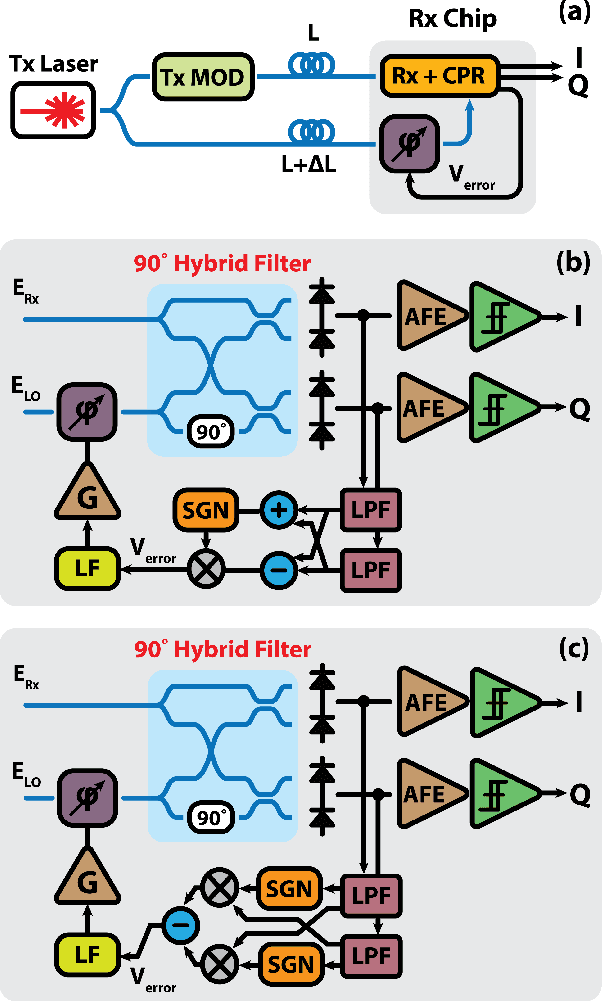

Optical interconnects are becoming a major bottleneck in scaling up future GPU racks and network switches within data centers. Although 200 Gb/s optical transceivers using PAM-4 modulation have been demonstrated, achieving higher data rates and energy efficiencies requires high-order coherent modulations like 16-QAM. Current coherent links rely on energy-intensive digital signal processing (DSP) for channel impairment compensation and carrier phase recovery (CPR), which consumes approximately 50pJ/b - 10x higher than future intra-data center requirements. For shorter links, simpler or DSP-free CPR methods can significantly reduce power and complexity. While Costas loops enable CPR for QPSK, they face challenges in scaling to higher-order modulations (e.g., 16/64-QAM) due to varying symbol amplitudes. In this work, we propose an optical coherent link architecture using laser forwarding and a novel DSP-free CPR system using offset-QAM modulation. The proposed analog CPR feedback loop is highly scalable, capable of supporting arbitrary offset-QAM modulations without requiring architectural modifications. This scalability is achieved through its phase error detection mechanism, which operates independently of the data rate and modulation type. We validated this method using GlobalFoundry's monolithic 45nm silicon photonics PDK models, with circuit- and system-level implementation at 100GBaud in the O-band. We will investigate the feedback loop dynamics, circuit-level implementations, and phase-noise performance of the proposed CPR loop. Our method can be adopted to realize low-power QAM optical interconnects for future coherent-lite pluggable transceivers as well as co-packaged optics (CPO) applications.
PromptLNet: Region-Adaptive Aesthetic Enhancement via Prompt Guidance in Low-Light Enhancement Net
Mar 11, 2025Learning and improving large language models through human preference feedback has become a mainstream approach, but it has rarely been applied to the field of low-light image enhancement. Existing low-light enhancement evaluations typically rely on objective metrics (such as FID, PSNR, etc.), which often result in models that perform well objectively but lack aesthetic quality. Moreover, most low-light enhancement models are primarily designed for global brightening, lacking detailed refinement. Therefore, the generated images often require additional local adjustments, leading to research gaps in practical applications. To bridge this gap, we propose the following innovations: 1) We collect human aesthetic evaluation text pairs and aesthetic scores from multiple low-light image datasets (e.g., LOL, LOL2, LOM, DCIM, MEF, etc.) to train a low-light image aesthetic evaluation model, supplemented by an optimization algorithm designed to fine-tune the diffusion model. 2) We propose a prompt-driven brightness adjustment module capable of performing fine-grained brightness and aesthetic adjustments for specific instances or regions. 3) We evaluate our method alongside existing state-of-the-art algorithms on mainstream benchmarks. Experimental results show that our method not only outperforms traditional methods in terms of visual quality but also provides greater flexibility and controllability, paving the way for improved aesthetic quality.
TSCnet: A Text-driven Semantic-level Controllable Framework for Customized Low-Light Image Enhancement
Mar 11, 2025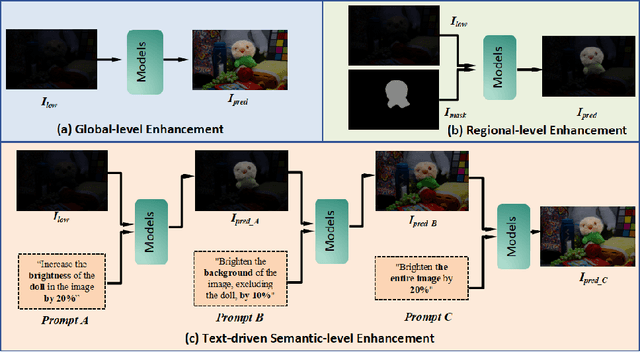
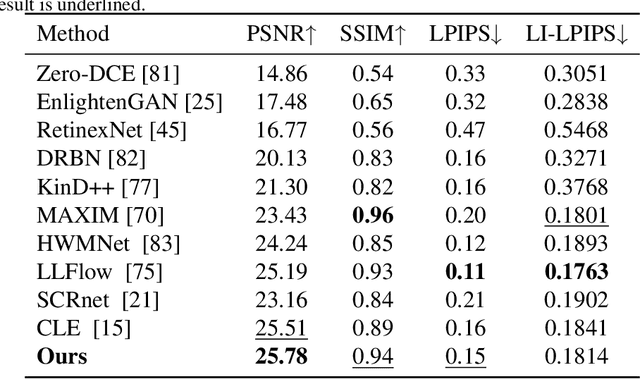
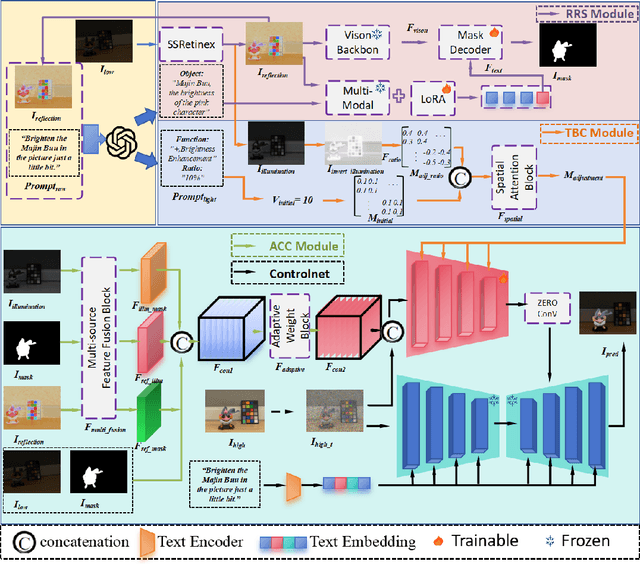
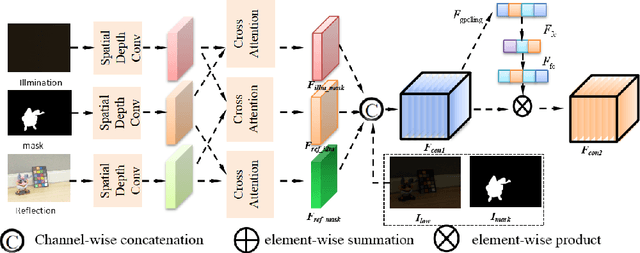
Deep learning-based image enhancement methods show significant advantages in reducing noise and improving visibility in low-light conditions. These methods are typically based on one-to-one mapping, where the model learns a direct transformation from low light to specific enhanced images. Therefore, these methods are inflexible as they do not allow highly personalized mapping, even though an individual's lighting preferences are inherently personalized. To overcome these limitations, we propose a new light enhancement task and a new framework that provides customized lighting control through prompt-driven, semantic-level, and quantitative brightness adjustments. The framework begins by leveraging a Large Language Model (LLM) to understand natural language prompts, enabling it to identify target objects for brightness adjustments. To localize these target objects, the Retinex-based Reasoning Segment (RRS) module generates precise target localization masks using reflection images. Subsequently, the Text-based Brightness Controllable (TBC) module adjusts brightness levels based on the generated illumination map. Finally, an Adaptive Contextual Compensation (ACC) module integrates multi-modal inputs and controls a conditional diffusion model to adjust the lighting, ensuring seamless and precise enhancements accurately. Experimental results on benchmark datasets demonstrate our framework's superior performance at increasing visibility, maintaining natural color balance, and amplifying fine details without creating artifacts. Furthermore, its robust generalization capabilities enable complex semantic-level lighting adjustments in diverse open-world environments through natural language interactions.
FECAM: Frequency Enhanced Channel Attention Mechanism for Time Series Forecasting
Dec 02, 2022Time series forecasting is a long-standing challenge due to the real-world information is in various scenario (e.g., energy, weather, traffic, economics, earthquake warning). However some mainstream forecasting model forecasting result is derailed dramatically from ground truth. We believe it's the reason that model's lacking ability of capturing frequency information which richly contains in real world datasets. At present, the mainstream frequency information extraction methods are Fourier transform(FT) based. However, use of FT is problematic due to Gibbs phenomenon. If the values on both sides of sequences differ significantly, oscillatory approximations are observed around both sides and high frequency noise will be introduced. Therefore We propose a novel frequency enhanced channel attention that adaptively modelling frequency interdependencies between channels based on Discrete Cosine Transform which would intrinsically avoid high frequency noise caused by problematic periodity during Fourier Transform, which is defined as Gibbs Phenomenon. We show that this network generalize extremely effectively across six real-world datasets and achieve state-of-the-art performance, we further demonstrate that frequency enhanced channel attention mechanism module can be flexibly applied to different networks. This module can improve the prediction ability of existing mainstream networks, which reduces 35.99% MSE on LSTM, 10.01% on Reformer, 8.71% on Informer, 8.29% on Autoformer, 8.06% on Transformer, etc., at a slight computational cost ,with just a few line of code. Our codes and data are available at https://github.com/Zero-coder/FECAM.