 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSCnet: A Text-driven Semantic-level Controllable Framework for Customized Low-Light Image Enhancement
Paper and Code
Mar 11, 2025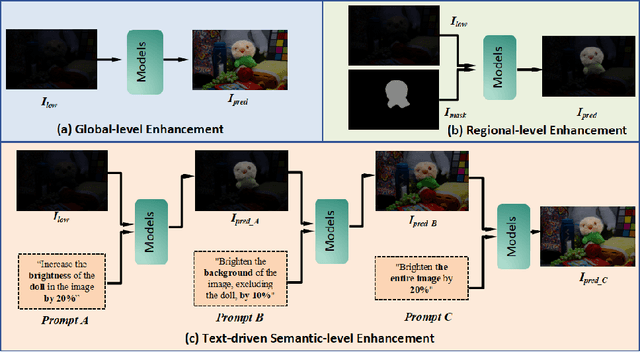
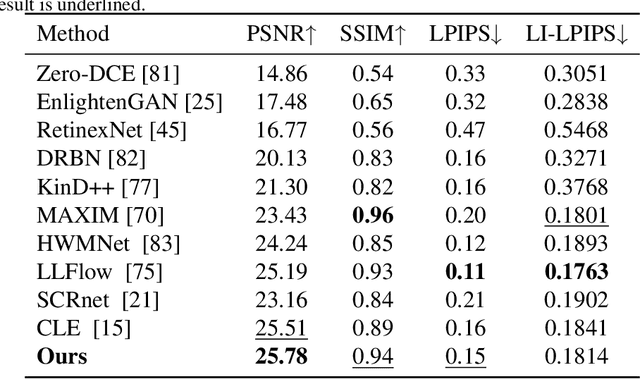
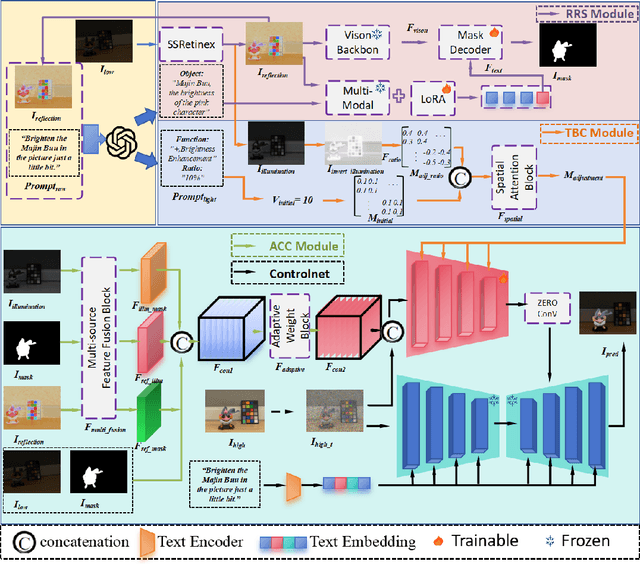
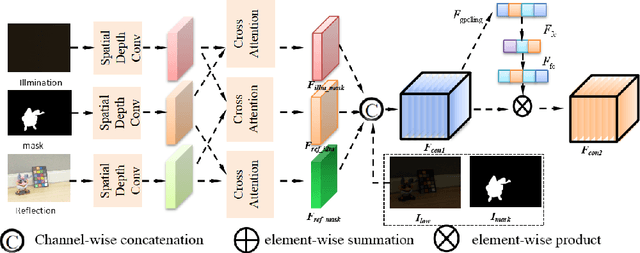
Deep learning-based image enhancement methods show significant advantages in reducing noise and improving visibility in low-light conditions. These methods are typically based on one-to-one mapping, where the model learns a direct transformation from low light to specific enhanced images. Therefore, these methods are inflexible as they do not allow highly personalized mapping, even though an individual's lighting preferences are inherently personalized. To overcome these limitations, we propose a new light enhancement task and a new framework that provides customized lighting control through prompt-driven, semantic-level, and quantitative brightness adjustments. The framework begins by leveraging a Large Language Model (LLM) to understand natural language prompts, enabling it to identify target objects for brightness adjustments. To localize these target objects, the Retinex-based Reasoning Segment (RRS) module generates precise target localization masks using reflection images. Subsequently, the Text-based Brightness Controllable (TBC) module adjusts brightness levels based on the generated illumination map. Finally, an Adaptive Contextual Compensation (ACC) module integrates multi-modal inputs and controls a conditional diffusion model to adjust the lighting, ensuring seamless and precise enhancements accurately. Experimental results on benchmark datasets demonstrate our framework's superior performance at increasing visibility, maintaining natural color balance, and amplifying fine details without creating artifacts. Furthermore, its robust generalization capabilities enable complex semantic-level lighting adjustments in diverse open-world environments through natural language interactions.