 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP3-LLM: An Integrated NPU-PIM Accelerator for LLM Inference Using Hybrid Numerical Formats
Nov 16, 2025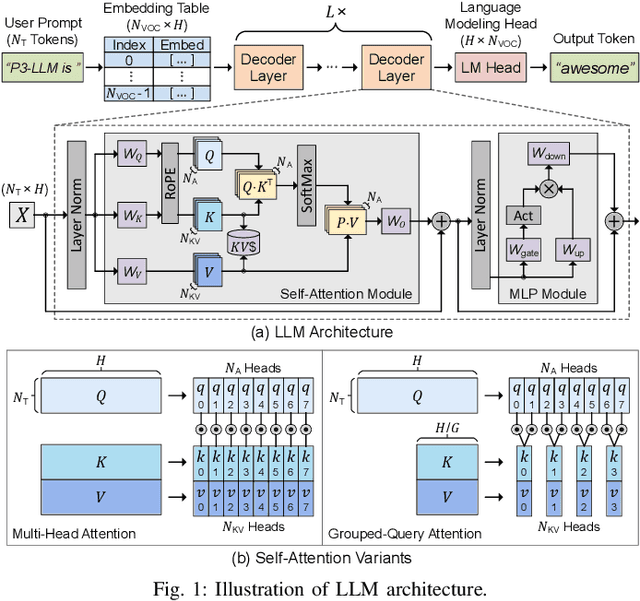
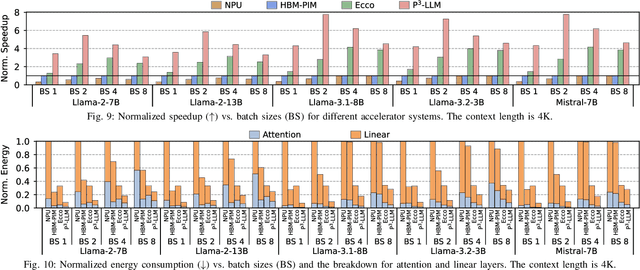
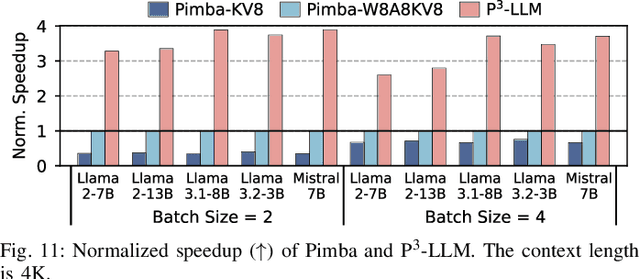
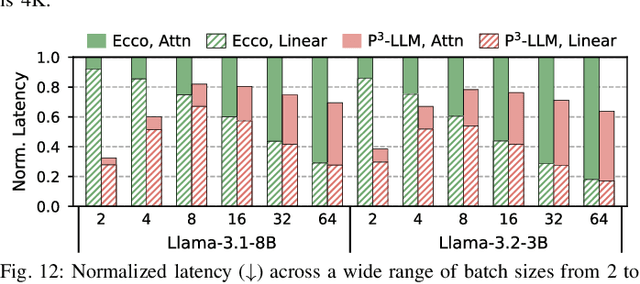
The substantial memory bandwidth and computational demands of large language models (LLMs) present critical challenges for efficient inference. To tackle this, the literature has explored heterogeneous systems that combine neural processing units (NPUs) with DRAM-based processing-in-memory (PIM) for LLM acceleration. However, existing high-precision (e.g., FP16) PIM compute units incur significant area and power overhead in DRAM technology, limiting the effective computation throughput. In this paper, we introduce P3-LLM, a novel NPU-PIM integrated accelerator for LLM inference using hybrid numerical formats. Our approach is threefold: First, we propose a flexible mixed-precision quantization scheme, which leverages hybrid numerical formats to quantize different LLM operands with high compression efficiency and minimal accuracy loss. Second, we architect an efficient PIM accelerator for P3-LLM, featuring enhanced compute units to support hybrid numerical formats. Our careful choice of numerical formats allows to co-design low-precision PIM compute units that significantly boost the computation throughput under iso-area constraints. Third, we optimize the low-precision dataflow of different LLM modules by applying operator fusion to minimize the overhead of runtime dequantization. Evaluation on a diverse set of representative LLMs and tasks demonstrates that P3-LLM achieves state-of-the-art accuracy in terms of both KV-cache quantization and weight-activation quantization. Combining the proposed quantization scheme with PIM architecture co-design, P3-LLM yields an average of $4.9\times$, $2.0\times$, and $3.4\times$ speedups over the state-of-the-art LLM accelerators HBM-PIM, Ecco, and Pimba, respectively. Our quantization code is available at https://github.com/yc2367/P3-LLM.git
Precision-Scalable Microscaling Datapaths with Optimized Reduction Tree for Efficient NPU Integration
Nov 09, 2025Emerging continual learning applications necessitate next-generation neural processing unit (NPU) platforms to support both training and inference operations. The promising Microscaling (MX) standard enables narrow bit-widths for inference and large dynamic ranges for training. However, existing MX multiply-accumulate (MAC) designs face a critical trade-off: integer accumulation requires expensive conversions from narrow floating-point products, while FP32 accumulation suffers from quantization losses and costly normalization. To address these limitations, we propose a hybrid precision-scalable reduction tree for MX MACs that combines the benefits of both approaches, enabling efficient mixed-precision accumulation with controlled accuracy relaxation. Moreover, we integrate an 8x8 array of these MACs into the state-of-the-art (SotA) NPU integration platform, SNAX, to provide efficient control and data transfer to our optimized precision-scalable MX datapath. We evaluate our design both on MAC and system level and compare it to the SotA. Our integrated system achieves an energy efficiency of 657, 1438-1675, and 4065 GOPS/W, respectively, for MXINT8, MXFP8/6, and MXFP4, with a throughput of 64, 256, and 512 GOPS.
An Open-Source HW-SW Co-Development Framework Enabling Efficient Multi-Accelerator Systems
Aug 20, 2025Heterogeneous accelerator-centric compute clusters are emerging as efficient solutions for diverse AI workloads. However, current integration strategies often compromise data movement efficiency and encounter compatibility issues in hardware and software. This prevents a unified approach that balances performance and ease of use. To this end, we present SNAX, an open-source integrated HW-SW framework enabling efficient multi-accelerator platforms through a novel hybrid-coupling scheme, consisting of loosely coupled asynchronous control and tightly coupled data access. SNAX brings reusable hardware modules designed to enhance compute accelerator utilization, and its customizable MLIR-based compiler to automate key system management tasks, jointly enabling rapid development and deployment of customized multi-accelerator compute clusters. Through extensive experimentation, we demonstrate SNAX's efficiency and flexibility in a low-power heterogeneous SoC. Accelerators can easily be integrated and programmed to achieve > 10x improvement in neural network performance compared to other accelerator systems while maintaining accelerator utilization of > 90% in full system operation.
Efficient Precision-Scalable Hardware for Microscaling (MX) Processing in Robotics Learning
May 28, 2025



Autonomous robots require efficient on-device learning to adapt to new environments without cloud dependency. For this edge training, Microscaling (MX) data types offer a promising solution by combining integer and floating-point representations with shared exponents, reducing energy consumption while maintaining accuracy. However, the state-of-the-art continuous learning processor, namely Dacapo, faces limitations with its MXINT-only support and inefficient vector-based grouping during backpropagation. In this paper, we present, to the best of our knowledge, the first work that addresses these limitations with two key innovations: (1) a precision-scalable arithmetic unit that supports all six MX data types by exploiting sub-word parallelism and unified integer and floating-point processing; and (2) support for square shared exponent groups to enable efficient weight handling during backpropagation, removing storage redundancy and quantization overhead. We evaluate our design against Dacapo under iso-peak-throughput on four robotics workloads in TSMC 16nm FinFET technology at 500MHz, reaching a 25.6% area reduction, a 51% lower memory footprint, and 4x higher effective training throughput while achieving comparable energy-efficiency, enabling efficient robotics continual learning at the edge.
CNN-based Robust Sound Source Localization with SRP-PHAT for the Extreme Edge
Mar 03, 2025Robust sound source localization for environments with noise and reverberation are increasingly exploiting deep neural networks fed with various acoustic features. Yet, state-of-the-art research mainly focuses on optimizing algorithmic accuracy, resulting in huge models preventing edge-device deployment. The edge, however, urges for real-time low-footprint acoustic reasoning for applications such as hearing aids and robot interactions. Hence, we set off from a robust CNN-based model using SRP-PHAT features, Cross3D [16], to pursue an efficient yet compact model architecture for the extreme edge. For both the SRP feature representation and neural network, we propose respectively our scalable LC-SRP-Edge and Cross3D-Edge algorithms which are optimized towards lower hardware overhead. LC-SRP-Edge halves the complexity and on-chip memory overhead for the sinc interpolation compared to the original LC-SRP [19]. Over multiple SRP resolution cases, Cross3D-Edge saves 10.32~73.71% computational complexity and 59.77~94.66% neural network weights against the Cross3D baseline. In terms of the accuracy-efficiency tradeoff, the most balanced version (EM) requires only 127.1 MFLOPS computation, 3.71 MByte/s bandwidth, and 0.821 MByte on-chip memory in total, while still retaining competitiveness in state-of-the-art accuracy comparisons. It achieves 8.59 ms/frame end-to-end latency on a Rasberry Pi 4B, which is 7.26x faster than the corresponding baseline.
Anda: Unlocking Efficient LLM Inference with a Variable-Length Grouped Activation Data Format
Nov 24, 2024The widely-used, weight-only quantized large language models (LLMs), which leverage low-bit integer (INT) weights and retain floating-point (FP) activations, reduce storage requirements while maintaining accuracy. However, this shifts the energy and latency bottlenecks towards the FP activations that are associated with costly memory accesses and computations. Existing LLM accelerators focus primarily on computation optimizations, overlooking the potential of jointly optimizing FP computations and data movement, particularly for the dominant FP-INT GeMM operations in LLM inference. To address these challenges, we investigate the sensitivity of activation precision across various LLM modules and its impact on overall model accuracy. Based on our findings, we first propose the Anda data type: an adaptive data format with group-shared exponent bits and dynamic mantissa bit allocation. Secondly, we develop an iterative post-training adaptive precision search algorithm that optimizes the bit-width for different LLM modules to balance model accuracy, energy efficiency, and inference speed. Lastly, a suite of hardware optimization techniques is proposed to maximally exploit the benefits of the Anda format. These include a bit-plane-based data organization scheme, Anda-enhanced processing units with bit-serial computation, and a runtime bit-plane Anda compressor to simultaneously optimize storage, computation, and memory footprints. Our evaluations on FPINT GeMM operations show that Anda achieves a 2.4x speedup, 4.0x area efficiency, and 3.1x energy efficiency improvement on average for popular LLMs including OPT, LLaMA, and LLaMA-2 series over the GPU-like FP-FP baseline. Anda demonstrates strong adaptability across various application scenarios, accuracy requirements, and system performance, enabling efficient LLM inference across a wide range of deployment scenarios.
OpenGeMM: A High-Utilization GeMM Accelerator Generator with Lightweight RISC-V Control and Tight Memory Coupling
Nov 14, 2024


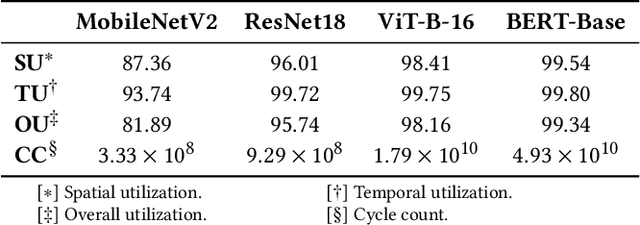
Deep neural networks (DNNs) face significant challenges when deployed on resource-constrained extreme edge devices due to their computational and data-intensive nature. While standalone accelerators tailored for specific application scenarios suffer from inflexible control and limited programmability, generic hardware acceleration platforms coupled with RISC-V CPUs can enable high reusability and flexibility, yet typically at the expense of system level efficiency and low utilization. To fill this gap, we propose OpenGeMM, an open-source acceleration platform, jointly demonstrating high efficiency and utilization, as well as ease of configurability and programmability. OpenGeMM encompasses a parameterized Chisel-coded GeMM accelerator, a lightweight RISC-V processor, and a tightly coupled multi-banked scratchpad memory. The GeMM core utilization and system efficiency are boosted through three mechanisms: configuration pre-loading, input pre-fetching with output buffering, and programmable strided memory access. Experimental results show that OpenGeMM can consistently achieve hardware utilization ranging from 81.89% to 99.34% across diverse CNN and Transformer workloads. Compared to the SotA open-source Gemmini accelerator, OpenGeMM demonstrates a 3.58x to 16.40x speedup on normalized throughput across a wide variety ofGeMM workloads, while achieving 4.68 TOPS/W system efficiency.
MATCH: Model-Aware TVM-based Compilation for Heterogeneous Edge Devices
Oct 11, 2024



Streamlining the deployment of Deep Neural Networks (DNNs) on heterogeneous edge platforms, coupling within the same micro-controller unit (MCU) instruction processors and hardware accelerators for tensor computations, is becoming one of the crucial challenges of the TinyML field. The best-performing DNN compilation toolchains are usually deeply customized for a single MCU family, and porting to a different heterogeneous MCU family implies labor-intensive re-development of almost the entire compiler. On the opposite side, retargetable toolchains, such as TVM, fail to exploit the capabilities of custom accelerators, resulting in the generation of general but unoptimized code. To overcome this duality, we introduce MATCH, a novel TVM-based DNN deployment framework designed for easy agile retargeting across different MCU processors and accelerators, thanks to a customizable model-based hardware abstraction. We show that a general and retargetable mapping framework enhanced with hardware cost models can compete with and even outperform custom toolchains on diverse targets while only needing the definition of an abstract hardware model and a SoC-specific API. We tested MATCH on two state-of-the-art heterogeneous MCUs, GAP9 and DIANA. On the four DNN models of the MLPerf Tiny suite MATCH reduces inference latency by up to 60.88 times on DIANA, compared to using the plain TVM, thanks to the exploitation of the on-board HW accelerator. Compared to HTVM, a fully customized toolchain for DIANA, we still reduce the latency by 16.94%. On GAP9, using the same benchmarks, we improve the latency by 2.15 times compared to the dedicated DORY compiler, thanks to our heterogeneous DNN mapping approach that synergically exploits the DNN accelerator and the eight-cores cluster available on board.
Pack my weights and run! Minimizing overheads for in-memory computing accelerators
Sep 15, 2024In-memory computing hardware accelerators allow more than 10x improvements in peak efficiency and performance for matrix-vector multiplications (MVM) compared to conventional digital designs. For this, they have gained great interest for the acceleration of neural network workloads. Nevertheless, these potential gains are only achieved when the utilization of the computational resources is maximized and the overhead from loading operands in the memory array minimized. To this aim, this paper proposes a novel mapping algorithm for the weights in the IMC macro, based on efficient packing of the weights of network layers in the available memory. The algorithm realizes 1) minimization of weight loading times while at the same time 2) maximally exploiting the parallelism of the IMC computational fabric. A set of case studies are carried out to show achievable trade-offs for the MLPerf Tiny benchmark \cite{mlperftiny} on IMC architectures, with potential $10-100\times$ EDP improvements.
ACCO: Automated Causal CNN Scheduling Optimizer for Real-Time Edge Accelerators
Jun 11, 2024Spatio-Temporal Convolutional Neural Networks (ST-CNN) allow extending CNN capabilities from image processing to consecutive temporal-pattern recognition. Generally, state-of-the-art (SotA) ST-CNNs inflate the feature maps and weights from well-known CNN backbones to represent the additional time dimension. However, edge computing applications would suffer tremendously from such large computation or memory overhead. Fortunately, the overlapping nature of ST-CNN enables various optimizations, such as the dilated causal convolution structure and Depth-First (DF) layer fusion to reuse the computation between time steps and CNN sliding windows, respectively. Yet, no hardware-aware approach has been proposed that jointly explores the optimal strategy from a scheduling as well as a hardware point of view. To this end, we present ACCO, an automated optimizer that explores efficient Causal CNN transformation and DF scheduling for ST-CNNs on edge hardware accelerators. By cost-modeling the computation and data movement on the accelerator architecture, ACCO automatically selects the best scheduling strategy for the given hardware-algorithm target. Compared to the fixed dilated causal structure, ST-CNNs with ACCO reach an ~8.4x better Energy-Delay-Product. Meanwhile, ACCO improves ~20% in layer-fusion optimals compared to the SotA DF exploration toolchain. When jointly optimizing ST-CNN on the temporal and spatial dimension, ACCO's scheduling outcomes are on average 19x faster and 37x more energy-efficient than spatial DF schemes.