 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePack my weights and run! Minimizing overheads for in-memory computing accelerators
Sep 15, 2024



In-memory computing hardware accelerators allow more than 10x improvements in peak efficiency and performance for matrix-vector multiplications (MVM) compared to conventional digital designs. For this, they have gained great interest for the acceleration of neural network workloads. Nevertheless, these potential gains are only achieved when the utilization of the computational resources is maximized and the overhead from loading operands in the memory array minimized. To this aim, this paper proposes a novel mapping algorithm for the weights in the IMC macro, based on efficient packing of the weights of network layers in the available memory. The algorithm realizes 1) minimization of weight loading times while at the same time 2) maximally exploiting the parallelism of the IMC computational fabric. A set of case studies are carried out to show achievable trade-offs for the MLPerf Tiny benchmark \cite{mlperftiny} on IMC architectures, with potential $10-100\times$ EDP improvements.
Analog or Digital In-memory Computing? Benchmarking through Quantitative Modeling
May 23, 2024
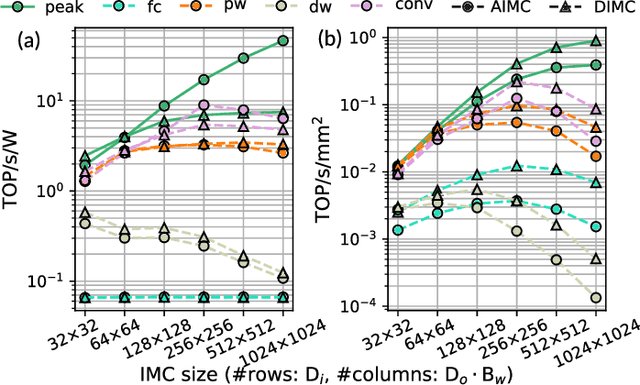
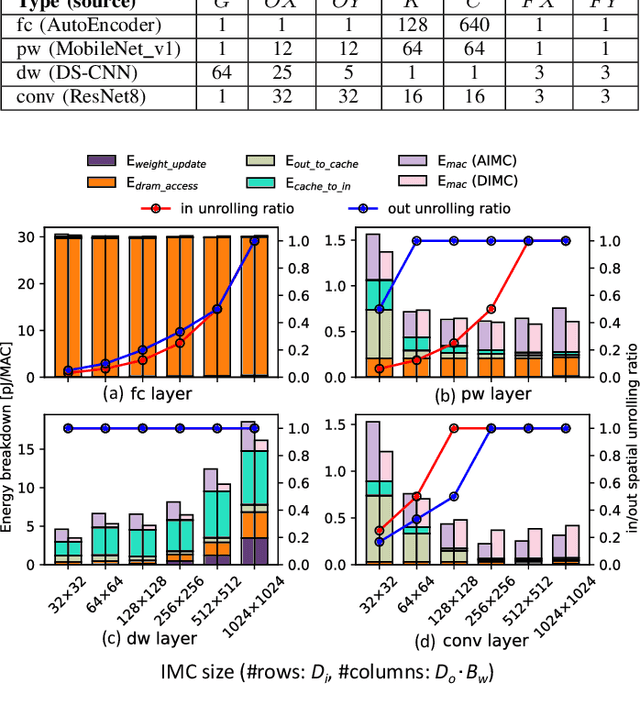
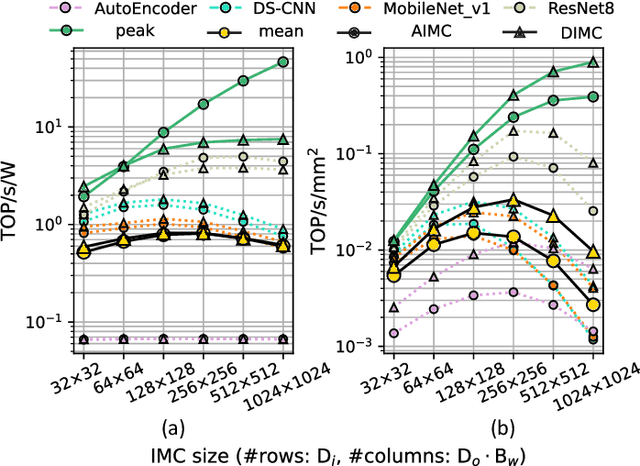
In-Memory Computing (IMC) has emerged as a promising paradigm for energy-efficient, throughput-efficient and area-efficient machine learning at the edge. However, the differences in hardware architectures, array dimensions, and fabrication technologies among published IMC realizations have made it difficult to grasp their relative strengths. Moreover, previous studies have primarily focused on exploring and benchmarking the peak performance of a single IMC macro rather than full system performance on real workloads. This paper aims to address the lack of a quantitative comparison of Analog In-Memory Computing (AIMC) and Digital In-Memory Computing (DIMC) processor architectures. We propose an analytical IMC performance model that is validated against published implementations and integrated into a system-level exploration framework for comprehensive performance assessments on different workloads with varying IMC configurations. Our experiments show that while DIMC generally has higher computational density than AIMC, AIMC with large macro sizes may have better energy efficiency than DIMC on convolutional-layers and pointwise-layers, which can exploit high spatial unrolling. On the other hand, DIMC with small macro size outperforms AIMC on depthwise-layers, which feature limited spatial unrolling opportunities inside a macro.