 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenGeMM: A High-Utilization GeMM Accelerator Generator with Lightweight RISC-V Control and Tight Memory Coupling
Nov 14, 2024


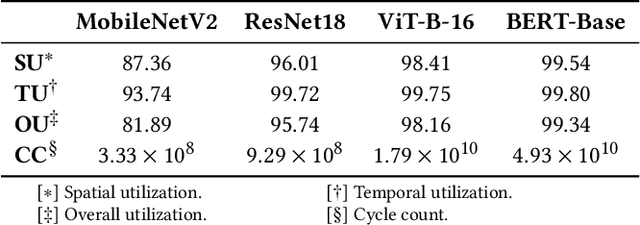
Deep neural networks (DNNs) face significant challenges when deployed on resource-constrained extreme edge devices due to their computational and data-intensive nature. While standalone accelerators tailored for specific application scenarios suffer from inflexible control and limited programmability, generic hardware acceleration platforms coupled with RISC-V CPUs can enable high reusability and flexibility, yet typically at the expense of system level efficiency and low utilization. To fill this gap, we propose OpenGeMM, an open-source acceleration platform, jointly demonstrating high efficiency and utilization, as well as ease of configurability and programmability. OpenGeMM encompasses a parameterized Chisel-coded GeMM accelerator, a lightweight RISC-V processor, and a tightly coupled multi-banked scratchpad memory. The GeMM core utilization and system efficiency are boosted through three mechanisms: configuration pre-loading, input pre-fetching with output buffering, and programmable strided memory access. Experimental results show that OpenGeMM can consistently achieve hardware utilization ranging from 81.89% to 99.34% across diverse CNN and Transformer workloads. Compared to the SotA open-source Gemmini accelerator, OpenGeMM demonstrates a 3.58x to 16.40x speedup on normalized throughput across a wide variety ofGeMM workloads, while achieving 4.68 TOPS/W system efficiency.
Analog or Digital In-memory Computing? Benchmarking through Quantitative Modeling
May 23, 2024
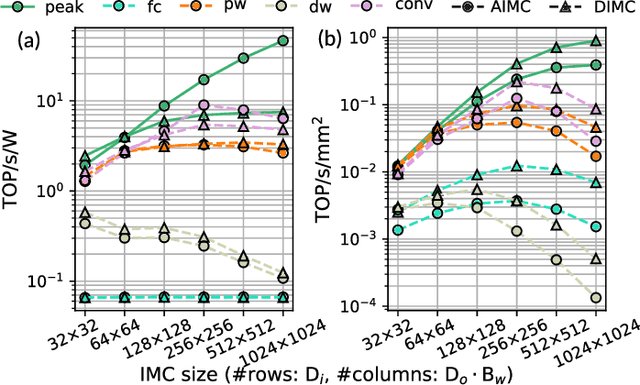
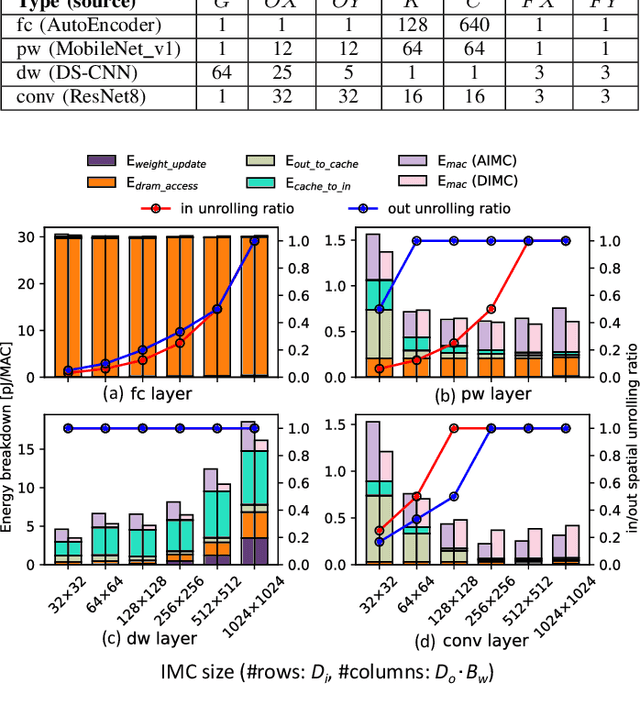
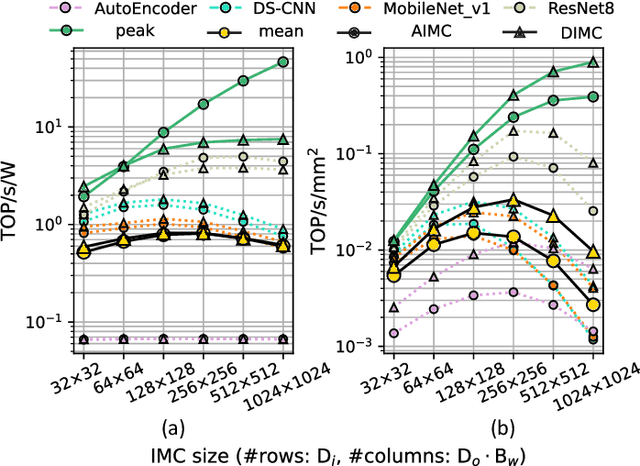
In-Memory Computing (IMC) has emerged as a promising paradigm for energy-efficient, throughput-efficient and area-efficient machine learning at the edge. However, the differences in hardware architectures, array dimensions, and fabrication technologies among published IMC realizations have made it difficult to grasp their relative strengths. Moreover, previous studies have primarily focused on exploring and benchmarking the peak performance of a single IMC macro rather than full system performance on real workloads. This paper aims to address the lack of a quantitative comparison of Analog In-Memory Computing (AIMC) and Digital In-Memory Computing (DIMC) processor architectures. We propose an analytical IMC performance model that is validated against published implementations and integrated into a system-level exploration framework for comprehensive performance assessments on different workloads with varying IMC configurations. Our experiments show that while DIMC generally has higher computational density than AIMC, AIMC with large macro sizes may have better energy efficiency than DIMC on convolutional-layers and pointwise-layers, which can exploit high spatial unrolling. On the other hand, DIMC with small macro size outperforms AIMC on depthwise-layers, which feature limited spatial unrolling opportunities inside a macro.