 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Open-Source HW-SW Co-Development Framework Enabling Efficient Multi-Accelerator Systems
Aug 20, 2025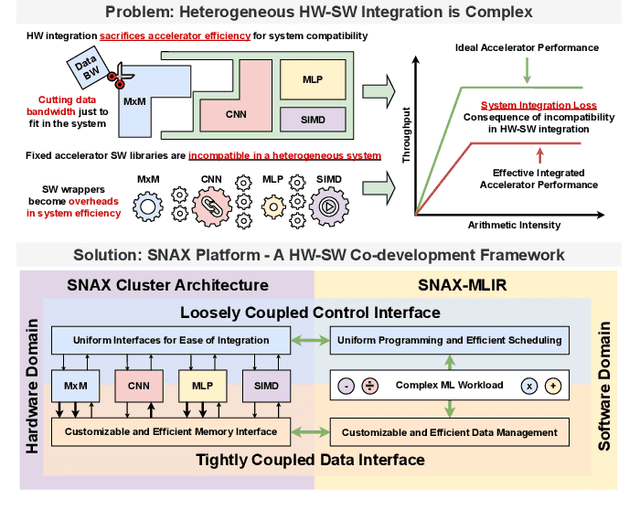
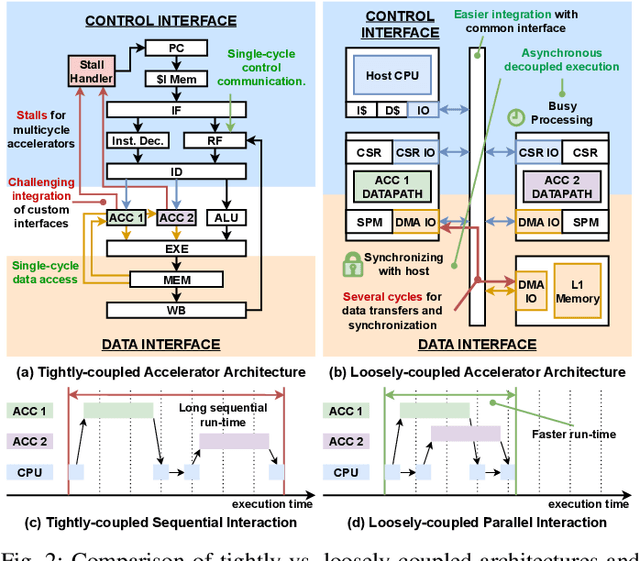
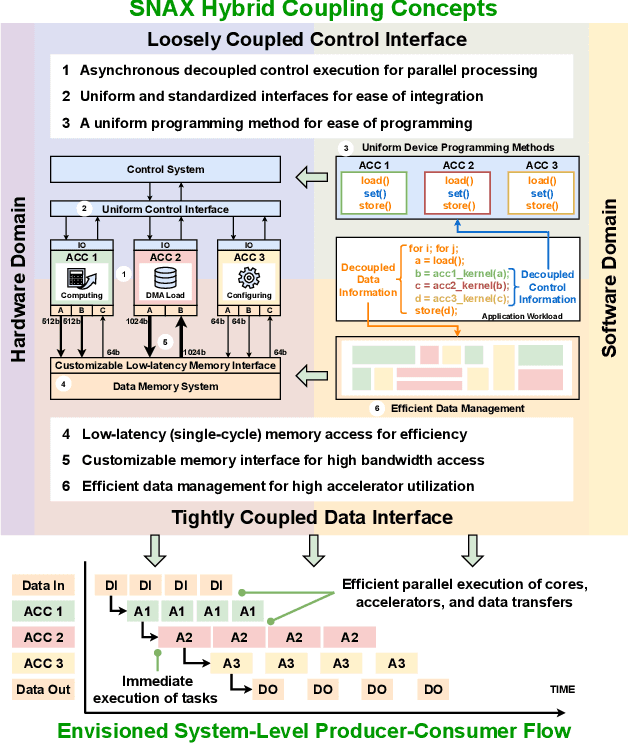
Heterogeneous accelerator-centric compute clusters are emerging as efficient solutions for diverse AI workloads. However, current integration strategies often compromise data movement efficiency and encounter compatibility issues in hardware and software. This prevents a unified approach that balances performance and ease of use. To this end, we present SNAX, an open-source integrated HW-SW framework enabling efficient multi-accelerator platforms through a novel hybrid-coupling scheme, consisting of loosely coupled asynchronous control and tightly coupled data access. SNAX brings reusable hardware modules designed to enhance compute accelerator utilization, and its customizable MLIR-based compiler to automate key system management tasks, jointly enabling rapid development and deployment of customized multi-accelerator compute clusters. Through extensive experimentation, we demonstrate SNAX's efficiency and flexibility in a low-power heterogeneous SoC. Accelerators can easily be integrated and programmed to achieve > 10x improvement in neural network performance compared to other accelerator systems while maintaining accelerator utilization of > 90% in full system operation.
OpenGeMM: A High-Utilization GeMM Accelerator Generator with Lightweight RISC-V Control and Tight Memory Coupling
Nov 14, 2024


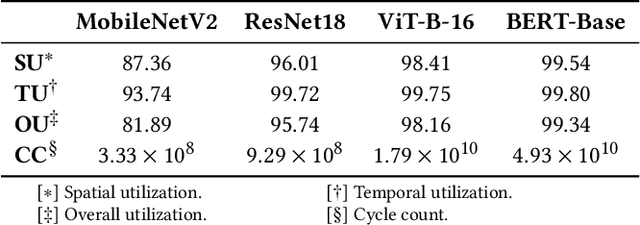
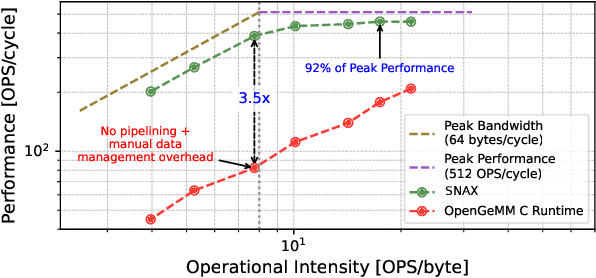
Deep neural networks (DNNs) face significant challenges when deployed on resource-constrained extreme edge devices due to their computational and data-intensive nature. While standalone accelerators tailored for specific application scenarios suffer from inflexible control and limited programmability, generic hardware acceleration platforms coupled with RISC-V CPUs can enable high reusability and flexibility, yet typically at the expense of system level efficiency and low utilization. To fill this gap, we propose OpenGeMM, an open-source acceleration platform, jointly demonstrating high efficiency and utilization, as well as ease of configurability and programmability. OpenGeMM encompasses a parameterized Chisel-coded GeMM accelerator, a lightweight RISC-V processor, and a tightly coupled multi-banked scratchpad memory. The GeMM core utilization and system efficiency are boosted through three mechanisms: configuration pre-loading, input pre-fetching with output buffering, and programmable strided memory access. Experimental results show that OpenGeMM can consistently achieve hardware utilization ranging from 81.89% to 99.34% across diverse CNN and Transformer workloads. Compared to the SotA open-source Gemmini accelerator, OpenGeMM demonstrates a 3.58x to 16.40x speedup on normalized throughput across a wide variety ofGeMM workloads, while achieving 4.68 TOPS/W system efficiency.
MATCH: Model-Aware TVM-based Compilation for Heterogeneous Edge Devices
Oct 11, 2024



Streamlining the deployment of Deep Neural Networks (DNNs) on heterogeneous edge platforms, coupling within the same micro-controller unit (MCU) instruction processors and hardware accelerators for tensor computations, is becoming one of the crucial challenges of the TinyML field. The best-performing DNN compilation toolchains are usually deeply customized for a single MCU family, and porting to a different heterogeneous MCU family implies labor-intensive re-development of almost the entire compiler. On the opposite side, retargetable toolchains, such as TVM, fail to exploit the capabilities of custom accelerators, resulting in the generation of general but unoptimized code. To overcome this duality, we introduce MATCH, a novel TVM-based DNN deployment framework designed for easy agile retargeting across different MCU processors and accelerators, thanks to a customizable model-based hardware abstraction. We show that a general and retargetable mapping framework enhanced with hardware cost models can compete with and even outperform custom toolchains on diverse targets while only needing the definition of an abstract hardware model and a SoC-specific API. We tested MATCH on two state-of-the-art heterogeneous MCUs, GAP9 and DIANA. On the four DNN models of the MLPerf Tiny suite MATCH reduces inference latency by up to 60.88 times on DIANA, compared to using the plain TVM, thanks to the exploitation of the on-board HW accelerator. Compared to HTVM, a fully customized toolchain for DIANA, we still reduce the latency by 16.94%. On GAP9, using the same benchmarks, we improve the latency by 2.15 times compared to the dedicated DORY compiler, thanks to our heterogeneous DNN mapping approach that synergically exploits the DNN accelerator and the eight-cores cluster available on board.