 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMATCH: Model-Aware TVM-based Compilation for Heterogeneous Edge Devices
Oct 11, 2024



Streamlining the deployment of Deep Neural Networks (DNNs) on heterogeneous edge platforms, coupling within the same micro-controller unit (MCU) instruction processors and hardware accelerators for tensor computations, is becoming one of the crucial challenges of the TinyML field. The best-performing DNN compilation toolchains are usually deeply customized for a single MCU family, and porting to a different heterogeneous MCU family implies labor-intensive re-development of almost the entire compiler. On the opposite side, retargetable toolchains, such as TVM, fail to exploit the capabilities of custom accelerators, resulting in the generation of general but unoptimized code. To overcome this duality, we introduce MATCH, a novel TVM-based DNN deployment framework designed for easy agile retargeting across different MCU processors and accelerators, thanks to a customizable model-based hardware abstraction. We show that a general and retargetable mapping framework enhanced with hardware cost models can compete with and even outperform custom toolchains on diverse targets while only needing the definition of an abstract hardware model and a SoC-specific API. We tested MATCH on two state-of-the-art heterogeneous MCUs, GAP9 and DIANA. On the four DNN models of the MLPerf Tiny suite MATCH reduces inference latency by up to 60.88 times on DIANA, compared to using the plain TVM, thanks to the exploitation of the on-board HW accelerator. Compared to HTVM, a fully customized toolchain for DIANA, we still reduce the latency by 16.94%. On GAP9, using the same benchmarks, we improve the latency by 2.15 times compared to the dedicated DORY compiler, thanks to our heterogeneous DNN mapping approach that synergically exploits the DNN accelerator and the eight-cores cluster available on board.
Precision-aware Latency and Energy Balancing on Multi-Accelerator Platforms for DNN Inference
Jun 08, 2023



The need to execute Deep Neural Networks (DNNs) at low latency and low power at the edge has spurred the development of new heterogeneous Systems-on-Chips (SoCs) encapsulating a diverse set of hardware accelerators. How to optimally map a DNN onto such multi-accelerator systems is an open problem. We propose ODiMO, a hardware-aware tool that performs a fine-grain mapping across different accelerators on-chip, splitting individual layers and executing them in parallel, to reduce inference energy consumption or latency, while taking into account each accelerator's quantization precision to maintain accuracy. Pareto-optimal networks in the accuracy vs. energy or latency space are pursued for three popular dataset/DNN pairs, and deployed on the DIANA heterogeneous ultra-low power edge AI SoC. We show that ODiMO reduces energy/latency by up to 33%/31% with limited accuracy drop (-0.53%/-0.32%) compared to manual heuristic mappings.
CoNLoCNN: Exploiting Correlation and Non-Uniform Quantization for Energy-Efficient Low-precision Deep Convolutional Neural Networks
Jul 31, 2022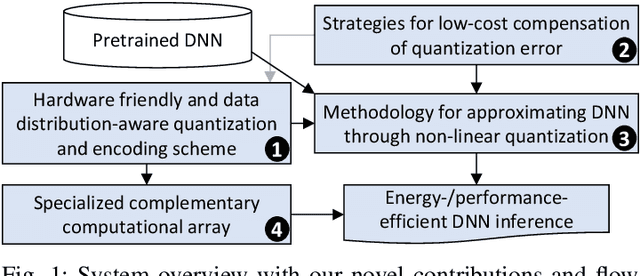



In today's era of smart cyber-physical systems, Deep Neural Networks (DNNs) have become ubiquitous due to their state-of-the-art performance in complex real-world applications. The high computational complexity of these networks, which translates to increased energy consumption, is the foremost obstacle towards deploying large DNNs in resource-constrained systems. Fixed-Point (FP) implementations achieved through post-training quantization are commonly used to curtail the energy consumption of these networks. However, the uniform quantization intervals in FP restrict the bit-width of data structures to large values due to the need to represent most of the numbers with sufficient resolution and avoid high quantization errors. In this paper, we leverage the key insight that (in most of the scenarios) DNN weights and activations are mostly concentrated near zero and only a few of them have large magnitudes. We propose CoNLoCNN, a framework to enable energy-efficient low-precision deep convolutional neural network inference by exploiting: (1) non-uniform quantization of weights enabling simplification of complex multiplication operations; and (2) correlation between activation values enabling partial compensation of quantization errors at low cost without any run-time overheads. To significantly benefit from non-uniform quantization, we also propose a novel data representation format, Encoded Low-Precision Binary Signed Digit, to compress the bit-width of weights while ensuring direct use of the encoded weight for processing using a novel multiply-and-accumulate (MAC) unit design.