 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoNLoCNN: Exploiting Correlation and Non-Uniform Quantization for Energy-Efficient Low-precision Deep Convolutional Neural Networks
Paper and Code
Jul 31, 2022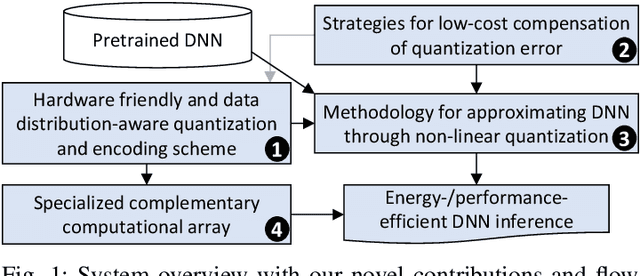



In today's era of smart cyber-physical systems, Deep Neural Networks (DNNs) have become ubiquitous due to their state-of-the-art performance in complex real-world applications. The high computational complexity of these networks, which translates to increased energy consumption, is the foremost obstacle towards deploying large DNNs in resource-constrained systems. Fixed-Point (FP) implementations achieved through post-training quantization are commonly used to curtail the energy consumption of these networks. However, the uniform quantization intervals in FP restrict the bit-width of data structures to large values due to the need to represent most of the numbers with sufficient resolution and avoid high quantization errors. In this paper, we leverage the key insight that (in most of the scenarios) DNN weights and activations are mostly concentrated near zero and only a few of them have large magnitudes. We propose CoNLoCNN, a framework to enable energy-efficient low-precision deep convolutional neural network inference by exploiting: (1) non-uniform quantization of weights enabling simplification of complex multiplication operations; and (2) correlation between activation values enabling partial compensation of quantization errors at low cost without any run-time overheads. To significantly benefit from non-uniform quantization, we also propose a novel data representation format, Encoded Low-Precision Binary Signed Digit, to compress the bit-width of weights while ensuring direct use of the encoded weight for processing using a novel multiply-and-accumulate (MAC) unit design.