 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinyCL: An Efficient Hardware Architecture for Continual Learning on Autonomous Systems
Feb 15, 2024The Continuous Learning (CL) paradigm consists of continuously evolving the parameters of the Deep Neural Network (DNN) model to progressively learn to perform new tasks without reducing the performance on previous tasks, i.e., avoiding the so-called catastrophic forgetting. However, the DNN parameter update in CL-based autonomous systems is extremely resource-hungry. The existing DNN accelerators cannot be directly employed in CL because they only support the execution of the forward propagation. Only a few prior architectures execute the backpropagation and weight update, but they lack the control and management for CL. Towards this, we design a hardware architecture, TinyCL, to perform CL on resource-constrained autonomous systems. It consists of a processing unit that executes both forward and backward propagation, and a control unit that manages memory-based CL workload. To minimize the memory accesses, the sliding window of the convolutional layer moves in a snake-like fashion. Moreover, the Multiply-and-Accumulate units can be reconfigured at runtime to execute different operations. As per our knowledge, our proposed TinyCL represents the first hardware accelerator that executes CL on autonomous systems. We synthesize the complete TinyCL architecture in a 65 nm CMOS technology node with the conventional ASIC design flow. It executes 1 epoch of training on a Conv + ReLU + Dense model on the CIFAR10 dataset in 1.76 s, while 1 training epoch of the same model using an Nvidia Tesla P100 GPU takes 103 s, thus achieving a 58 x speedup, consuming 86 mW in a 4.74 mm2 die.
SwiftTron: An Efficient Hardware Accelerator for Quantized Transformers
Apr 25, 2023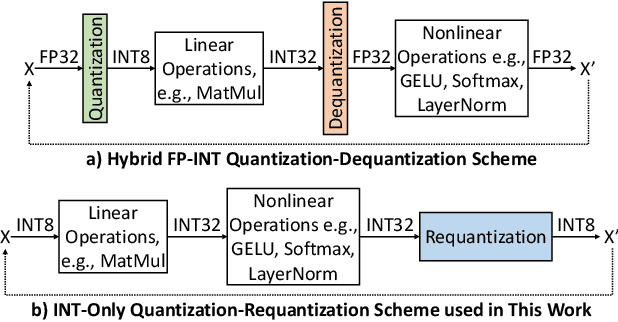
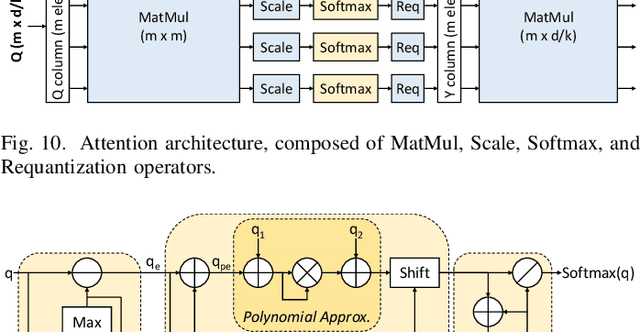
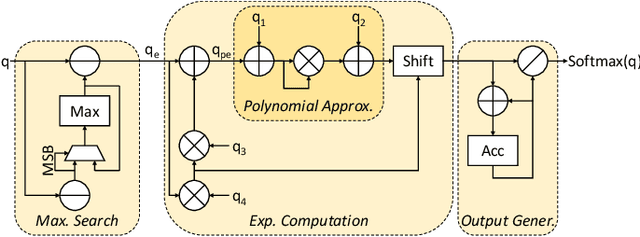

Transformers' compute-intensive operations pose enormous challenges for their deployment in resource-constrained EdgeAI / tinyML devices. As an established neural network compression technique, quantization reduces the hardware computational and memory resources. In particular, fixed-point quantization is desirable to ease the computations using lightweight blocks, like adders and multipliers, of the underlying hardware. However, deploying fully-quantized Transformers on existing general-purpose hardware, generic AI accelerators, or specialized architectures for Transformers with floating-point units might be infeasible and/or inefficient. Towards this, we propose SwiftTron, an efficient specialized hardware accelerator designed for Quantized Transformers. SwiftTron supports the execution of different types of Transformers' operations (like Attention, Softmax, GELU, and Layer Normalization) and accounts for diverse scaling factors to perform correct computations. We synthesize the complete SwiftTron architecture in a $65$ nm CMOS technology with the ASIC design flow. Our Accelerator executes the RoBERTa-base model in 1.83 ns, while consuming 33.64 mW power, and occupying an area of 273 mm^2. To ease the reproducibility, the RTL of our SwiftTron architecture is released at https://github.com/albertomarchisio/SwiftTron.
LaneSNNs: Spiking Neural Networks for Lane Detection on the Loihi Neuromorphic Processor
Aug 03, 2022


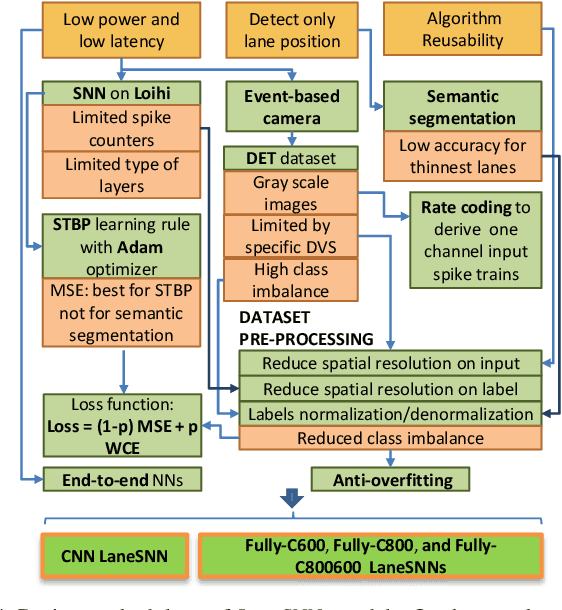
Autonomous Driving (AD) related features represent important elements for the next generation of mobile robots and autonomous vehicles focused on increasingly intelligent, autonomous, and interconnected systems. The applications involving the use of these features must provide, by definition, real-time decisions, and this property is key to avoid catastrophic accidents. Moreover, all the decision processes must require low power consumption, to increase the lifetime and autonomy of battery-driven systems. These challenges can be addressed through efficient implementations of Spiking Neural Networks (SNNs) on Neuromorphic Chips and the use of event-based cameras instead of traditional frame-based cameras. In this paper, we present a new SNN-based approach, called LaneSNN, for detecting the lanes marked on the streets using the event-based camera input. We develop four novel SNN models characterized by low complexity and fast response, and train them using an offline supervised learning rule. Afterward, we implement and map the learned SNNs models onto the Intel Loihi Neuromorphic Research Chip. For the loss function, we develop a novel method based on the linear composition of Weighted binary Cross Entropy (WCE) and Mean Squared Error (MSE) measures. Our experimental results show a maximum Intersection over Union (IoU) measure of about 0.62 and very low power consumption of about 1 W. The best IoU is achieved with an SNN implementation that occupies only 36 neurocores on the Loihi processor while providing a low latency of less than 8 ms to recognize an image, thereby enabling real-time performance. The IoU measures provided by our networks are comparable with the state-of-the-art, but at a much low power consumption of 1 W.
CoNLoCNN: Exploiting Correlation and Non-Uniform Quantization for Energy-Efficient Low-precision Deep Convolutional Neural Networks
Jul 31, 2022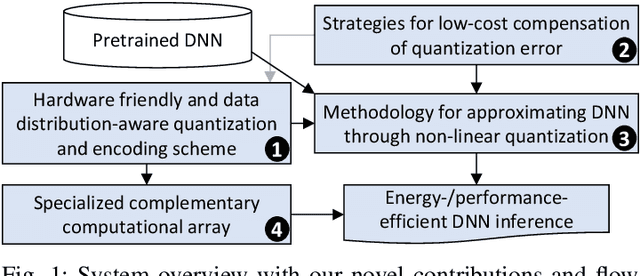



In today's era of smart cyber-physical systems, Deep Neural Networks (DNNs) have become ubiquitous due to their state-of-the-art performance in complex real-world applications. The high computational complexity of these networks, which translates to increased energy consumption, is the foremost obstacle towards deploying large DNNs in resource-constrained systems. Fixed-Point (FP) implementations achieved through post-training quantization are commonly used to curtail the energy consumption of these networks. However, the uniform quantization intervals in FP restrict the bit-width of data structures to large values due to the need to represent most of the numbers with sufficient resolution and avoid high quantization errors. In this paper, we leverage the key insight that (in most of the scenarios) DNN weights and activations are mostly concentrated near zero and only a few of them have large magnitudes. We propose CoNLoCNN, a framework to enable energy-efficient low-precision deep convolutional neural network inference by exploiting: (1) non-uniform quantization of weights enabling simplification of complex multiplication operations; and (2) correlation between activation values enabling partial compensation of quantization errors at low cost without any run-time overheads. To significantly benefit from non-uniform quantization, we also propose a novel data representation format, Encoded Low-Precision Binary Signed Digit, to compress the bit-width of weights while ensuring direct use of the encoded weight for processing using a novel multiply-and-accumulate (MAC) unit design.
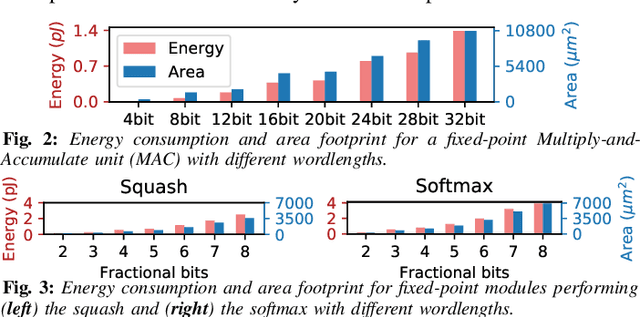
Enabling Capsule Networks at the Edge through Approximate Softmax and Squash Operations
Jun 21, 2022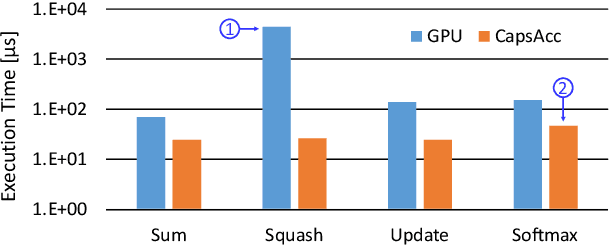
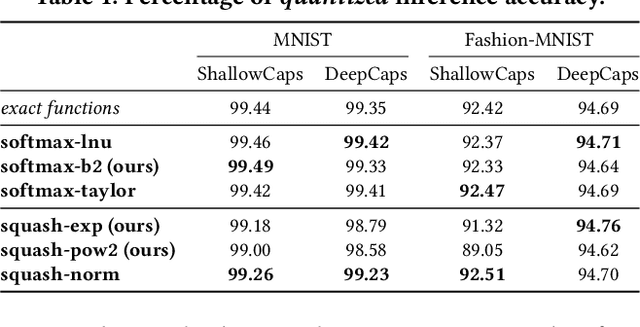
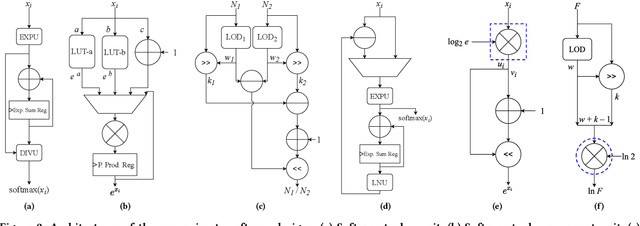
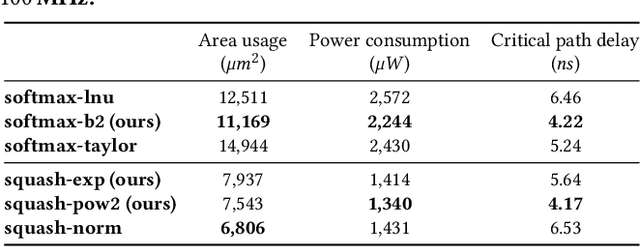
Complex Deep Neural Networks such as Capsule Networks (CapsNets) exhibit high learning capabilities at the cost of compute-intensive operations. To enable their deployment on edge devices, we propose to leverage approximate computing for designing approximate variants of the complex operations like softmax and squash. In our experiments, we evaluate tradeoffs between area, power consumption, and critical path delay of the designs implemented with the ASIC design flow, and the accuracy of the quantized CapsNets, compared to the exact functions.
R-SNN: An Analysis and Design Methodology for Robustifying Spiking Neural Networks against Adversarial Attacks through Noise Filters for Dynamic Vision Sensors
Sep 01, 2021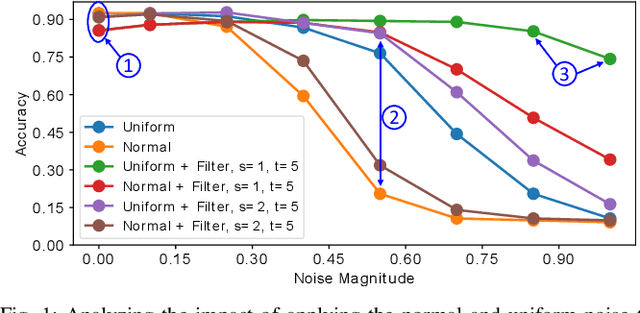

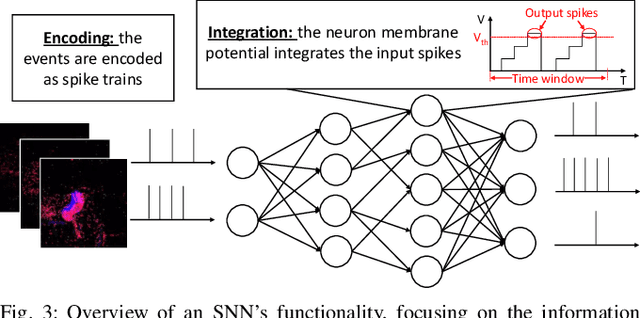
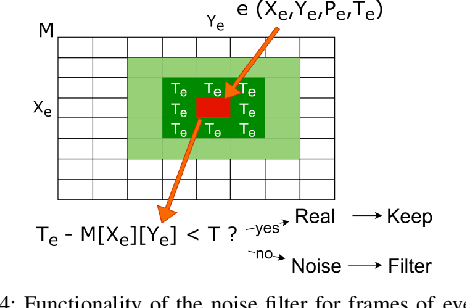
Spiking Neural Networks (SNNs) aim at providing energy-efficient learning capabilities when implemented on neuromorphic chips with event-based Dynamic Vision Sensors (DVS). This paper studies the robustness of SNNs against adversarial attacks on such DVS-based systems, and proposes R-SNN, a novel methodology for robustifying SNNs through efficient DVS-noise filtering. We are the first to generate adversarial attacks on DVS signals (i.e., frames of events in the spatio-temporal domain) and to apply noise filters for DVS sensors in the quest for defending against adversarial attacks. Our results show that the noise filters effectively prevent the SNNs from being fooled. The SNNs in our experiments provide more than 90% accuracy on the DVS-Gesture and NMNIST datasets under different adversarial threat models.
DVS-Attacks: Adversarial Attacks on Dynamic Vision Sensors for Spiking Neural Networks
Jul 01, 2021
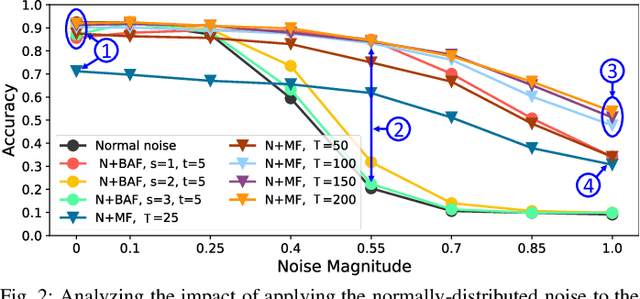


Spiking Neural Networks (SNNs), despite being energy-efficient when implemented on neuromorphic hardware and coupled with event-based Dynamic Vision Sensors (DVS), are vulnerable to security threats, such as adversarial attacks, i.e., small perturbations added to the input for inducing a misclassification. Toward this, we propose DVS-Attacks, a set of stealthy yet efficient adversarial attack methodologies targeted to perturb the event sequences that compose the input of the SNNs. First, we show that noise filters for DVS can be used as defense mechanisms against adversarial attacks. Afterwards, we implement several attacks and test them in the presence of two types of noise filters for DVS cameras. The experimental results show that the filters can only partially defend the SNNs against our proposed DVS-Attacks. Using the best settings for the noise filters, our proposed Mask Filter-Aware Dash Attack reduces the accuracy by more than 20% on the DVS-Gesture dataset and by more than 65% on the MNIST dataset, compared to the original clean frames. The source code of all the proposed DVS-Attacks and noise filters is released at https://github.com/albertomarchisio/DVS-Attacks.
CarSNN: An Efficient Spiking Neural Network for Event-Based Autonomous Cars on the Loihi Neuromorphic Research Processor
Jul 01, 2021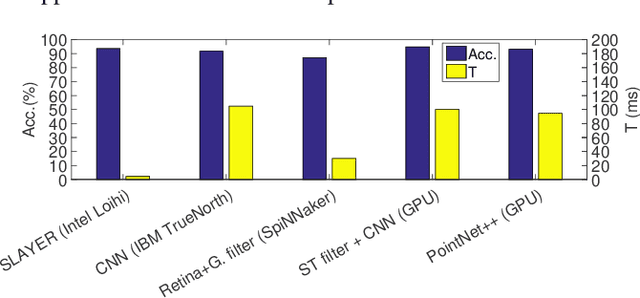

Autonomous Driving (AD) related features provide new forms of mobility that are also beneficial for other kind of intelligent and autonomous systems like robots, smart transportation, and smart industries. For these applications, the decisions need to be made fast and in real-time. Moreover, in the quest for electric mobility, this task must follow low power policy, without affecting much the autonomy of the mean of transport or the robot. These two challenges can be tackled using the emerging Spiking Neural Networks (SNNs). When deployed on a specialized neuromorphic hardware, SNNs can achieve high performance with low latency and low power consumption. In this paper, we use an SNN connected to an event-based camera for facing one of the key problems for AD, i.e., the classification between cars and other objects. To consume less power than traditional frame-based cameras, we use a Dynamic Vision Sensor (DVS). The experiments are made following an offline supervised learning rule, followed by mapping the learnt SNN model on the Intel Loihi Neuromorphic Research Chip. Our best experiment achieves an accuracy on offline implementation of 86%, that drops to 83% when it is ported onto the Loihi Chip. The Neuromorphic Hardware implementation has maximum 0.72 ms of latency for every sample, and consumes only 310 mW. To the best of our knowledge, this work is the first implementation of an event-based car classifier on a Neuromorphic Chip.
Hardware and Software Optimizations for Accelerating Deep Neural Networks: Survey of Current Trends, Challenges, and the Road Ahead
Dec 21, 2020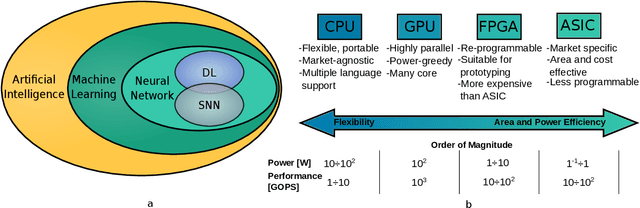


Currently, Machine Learning (ML) is becoming ubiquitous in everyday life. Deep Learning (DL) is already present in many applications ranging from computer vision for medicine to autonomous driving of modern cars as well as other sectors in security, healthcare, and finance. However, to achieve impressive performance, these algorithms employ very deep networks, requiring a significant computational power, both during the training and inference time. A single inference of a DL model may require billions of multiply-and-accumulated operations, making the DL extremely compute- and energy-hungry. In a scenario where several sophisticated algorithms need to be executed with limited energy and low latency, the need for cost-effective hardware platforms capable of implementing energy-efficient DL execution arises. This paper first introduces the key properties of two brain-inspired models like Deep Neural Network (DNN), and Spiking Neural Network (SNN), and then analyzes techniques to produce efficient and high-performance designs. This work summarizes and compares the works for four leading platforms for the execution of algorithms such as CPU, GPU, FPGA and ASIC describing the main solutions of the state-of-the-art, giving much prominence to the last two solutions since they offer greater design flexibility and bear the potential of high energy-efficiency, especially for the inference process. In addition to hardware solutions, this paper discusses some of the important security issues that these DNN and SNN models may have during their execution, and offers a comprehensive section on benchmarking, explaining how to assess the quality of different networks and hardware systems designed for them.
Q-CapsNets: A Specialized Framework for Quantizing Capsule Networks
Apr 17, 2020
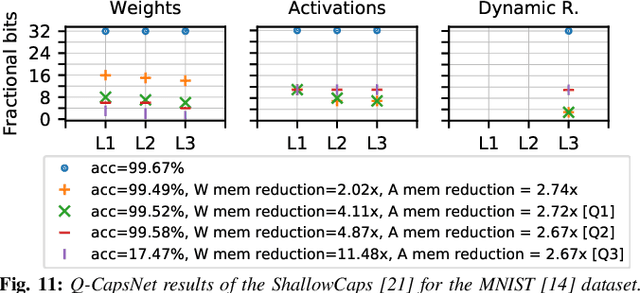
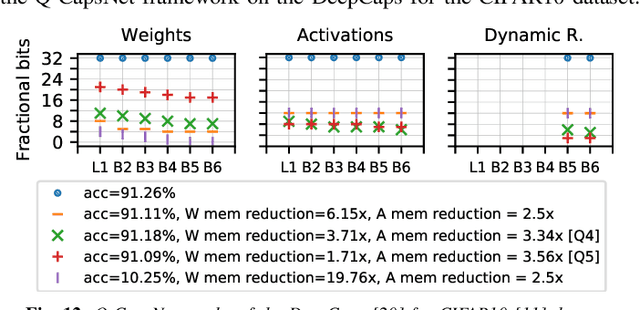
Capsule Networks (CapsNets), recently proposed by the Google Brain team, have superior learning capabilities in machine learning tasks, like image classification, compared to the traditional CNNs. However, CapsNets require extremely intense computations and are difficult to be deployed in their original form at the resource-constrained edge devices. This paper makes the first attempt to quantize CapsNet models, to enable their efficient edge implementations, by developing a specialized quantization framework for CapsNets. We evaluate our framework for several benchmarks. On a deep CapsNet model for the CIFAR10 dataset, the framework reduces the memory footprint by 6.2x, with only 0.15% accuracy loss. We will open-source our framework at https://git.io/JvDIF in August 2020.