 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobCaps: Evaluating the Robustness of Capsule Networks against Affine Transformations and Adversarial Attacks
Apr 25, 2023Capsule Networks (CapsNets) are able to hierarchically preserve the pose relationships between multiple objects for image classification tasks. Other than achieving high accuracy, another relevant factor in deploying CapsNets in safety-critical applications is the robustness against input transformations and malicious adversarial attacks. In this paper, we systematically analyze and evaluate different factors affecting the robustness of CapsNets, compared to traditional Convolutional Neural Networks (CNNs). Towards a comprehensive comparison, we test two CapsNet models and two CNN models on the MNIST, GTSRB, and CIFAR10 datasets, as well as on the affine-transformed versions of such datasets. With a thorough analysis, we show which properties of these architectures better contribute to increasing the robustness and their limitations. Overall, CapsNets achieve better robustness against adversarial examples and affine transformations, compared to a traditional CNN with a similar number of parameters. Similar conclusions have been derived for deeper versions of CapsNets and CNNs. Moreover, our results unleash a key finding that the dynamic routing does not contribute much to improving the CapsNets' robustness. Indeed, the main generalization contribution is due to the hierarchical feature learning through capsules.
ISimDL: Importance Sampling-Driven Acceleration of Fault Injection Simulations for Evaluating the Robustness of Deep Learning
Mar 14, 2023Deep Learning (DL) systems have proliferated in many applications, requiring specialized hardware accelerators and chips. In the nano-era, devices have become increasingly more susceptible to permanent and transient faults. Therefore, we need an efficient methodology for analyzing the resilience of advanced DL systems against such faults, and understand how the faults in neural accelerator chips manifest as errors at the DL application level, where faults can lead to undetectable and unrecoverable errors. Using fault injection, we can perform resilience investigations of the DL system by modifying neuron weights and outputs at the software-level, as if the hardware had been affected by a transient fault. Existing fault models reduce the search space, allowing faster analysis, but requiring a-priori knowledge on the model, and not allowing further analysis of the filtered-out search space. Therefore, we propose ISimDL, a novel methodology that employs neuron sensitivity to generate importance sampling-based fault-scenarios. Without any a-priori knowledge of the model-under-test, ISimDL provides an equivalent reduction of the search space as existing works, while allowing long simulations to cover all the possible faults, improving on existing model requirements. Our experiments show that the importance sampling provides up to 15x higher precision in selecting critical faults than the random uniform sampling, reaching such precision in less than 100 faults. Additionally, we showcase another practical use-case for importance sampling for reliable DNN design, namely Fault Aware Training (FAT). By using ISimDL to select the faults leading to errors, we can insert the faults during the DNN training process to harden the DNN against such faults. Using importance sampling in FAT reduces the overhead required for finding faults that lead to a predetermined drop in accuracy by more than 12x.
enpheeph: A Fault Injection Framework for Spiking and Compressed Deep Neural Networks
Jul 31, 2022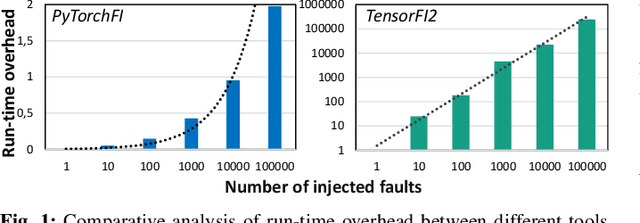
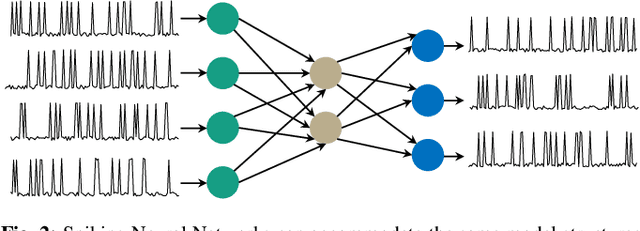
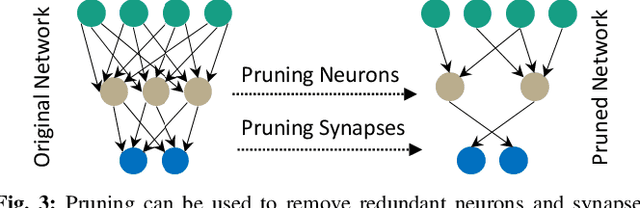
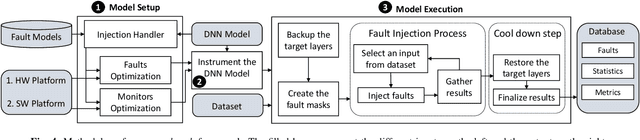
Research on Deep Neural Networks (DNNs) has focused on improving performance and accuracy for real-world deployments, leading to new models, such as Spiking Neural Networks (SNNs), and optimization techniques, e.g., quantization and pruning for compressed networks. However, the deployment of these innovative models and optimization techniques introduces possible reliability issues, which is a pillar for DNNs to be widely used in safety-critical applications, e.g., autonomous driving. Moreover, scaling technology nodes have the associated risk of multiple faults happening at the same time, a possibility not addressed in state-of-the-art resiliency analyses. Towards better reliability analysis for DNNs, we present enpheeph, a Fault Injection Framework for Spiking and Compressed DNNs. The enpheeph framework enables optimized execution on specialized hardware devices, e.g., GPUs, while providing complete customizability to investigate different fault models, emulating various reliability constraints and use-cases. Hence, the faults can be executed on SNNs as well as compressed networks with minimal-to-none modifications to the underlying code, a feat that is not achievable by other state-of-the-art tools. To evaluate our enpheeph framework, we analyze the resiliency of different DNN and SNN models, with different compression techniques. By injecting a random and increasing number of faults, we show that DNNs can show a reduction in accuracy with a fault rate as low as 7 x 10 ^ (-7) faults per parameter, with an accuracy drop higher than 40%. Run-time overhead when executing enpheeph is less than 20% of the baseline execution time when executing 100 000 faults concurrently, at least 10x lower than state-of-the-art frameworks, making enpheeph future-proof for complex fault injection scenarios. We release enpheeph at https://github.com/Alexei95/enpheeph.
NeuroUnlock: Unlocking the Architecture of Obfuscated Deep Neural Networks
Jun 01, 2022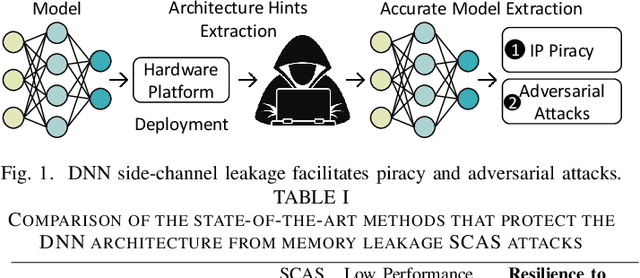

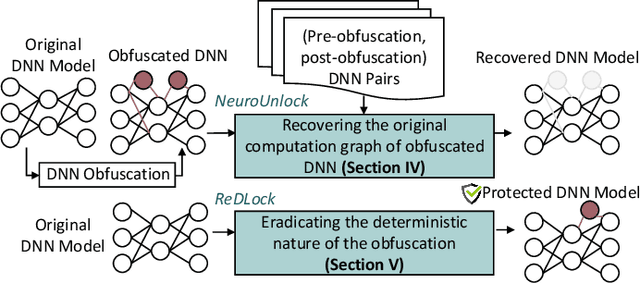
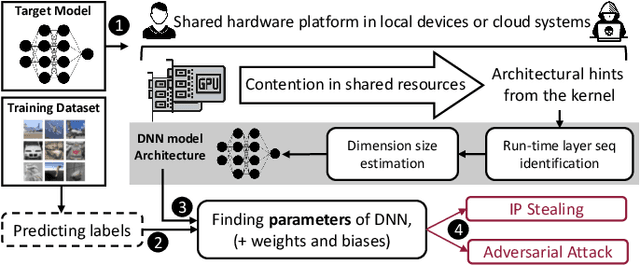
The advancements of deep neural networks (DNNs) have led to their deployment in diverse settings, including safety and security-critical applications. As a result, the characteristics of these models have become sensitive intellectual properties that require protection from malicious users. Extracting the architecture of a DNN through leaky side-channels (e.g., memory access) allows adversaries to (i) clone the model, and (ii) craft adversarial attacks. DNN obfuscation thwarts side-channel-based architecture stealing (SCAS) attacks by altering the run-time traces of a given DNN while preserving its functionality. In this work, we expose the vulnerability of state-of-the-art DNN obfuscation methods to these attacks. We present NeuroUnlock, a novel SCAS attack against obfuscated DNNs. Our NeuroUnlock employs a sequence-to-sequence model that learns the obfuscation procedure and automatically reverts it, thereby recovering the original DNN architecture. We demonstrate the effectiveness of NeuroUnlock by recovering the architecture of 200 randomly generated and obfuscated DNNs running on the Nvidia RTX 2080 TI graphics processing unit (GPU). Moreover, NeuroUnlock recovers the architecture of various other obfuscated DNNs, such as the VGG-11, VGG-13, ResNet-20, and ResNet-32 networks. After recovering the architecture, NeuroUnlock automatically builds a near-equivalent DNN with only a 1.4% drop in the testing accuracy. We further show that launching a subsequent adversarial attack on the recovered DNNs boosts the success rate of the adversarial attack by 51.7% in average compared to launching it on the obfuscated versions. Additionally, we propose a novel methodology for DNN obfuscation, ReDLock, which eradicates the deterministic nature of the obfuscation and achieves 2.16X more resilience to the NeuroUnlock attack. We release the NeuroUnlock and the ReDLock as open-source frameworks.
MLComp: A Methodology for Machine Learning-based Performance Estimation and Adaptive Selection of Pareto-Optimal Compiler Optimization Sequences
Dec 11, 2020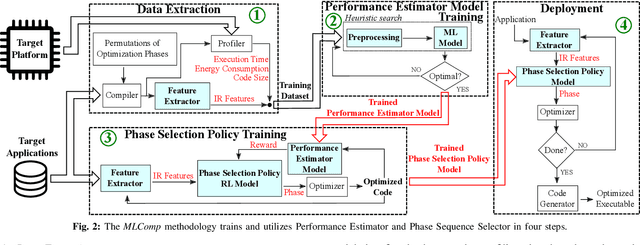
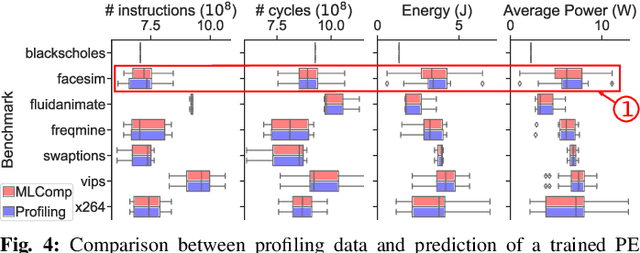
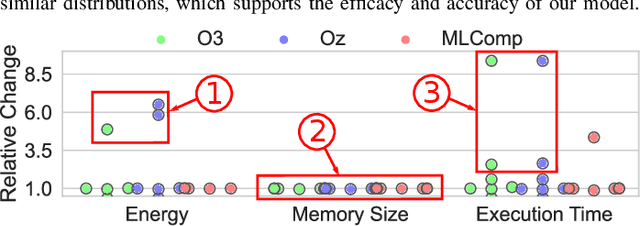
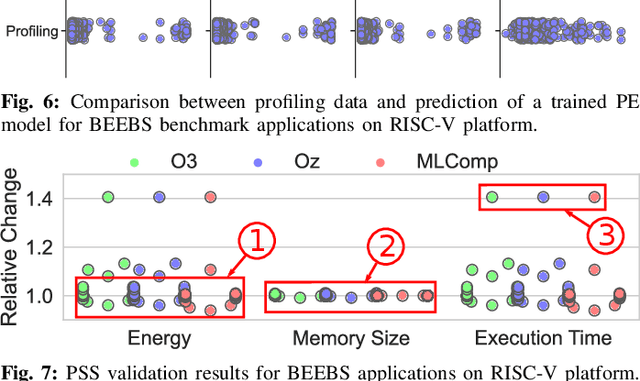
Embedded systems have proliferated in various consumer and industrial applications with the evolution of Cyber-Physical Systems and the Internet of Things. These systems are subjected to stringent constraints so that embedded software must be optimized for multiple objectives simultaneously, namely reduced energy consumption, execution time, and code size. Compilers offer optimization phases to improve these metrics. However, proper selection and ordering of them depends on multiple factors and typically requires expert knowledge. State-of-the-art optimizers facilitate different platforms and applications case by case, and they are limited by optimizing one metric at a time, as well as requiring a time-consuming adaptation for different targets through dynamic profiling. To address these problems, we propose the novel MLComp methodology, in which optimization phases are sequenced by a Reinforcement Learning-based policy. Training of the policy is supported by Machine Learning-based analytical models for quick performance estimation, thereby drastically reducing the time spent for dynamic profiling. In our framework, different Machine Learning models are automatically tested to choose the best-fitting one. The trained Performance Estimator model is leveraged to efficiently devise Reinforcement Learning-based multi-objective policies for creating quasi-optimal phase sequences. Compared to state-of-the-art estimation models, our Performance Estimator model achieves lower relative error (<2%) with up to 50x faster training time over multiple platforms and application domains. Our Phase Selection Policy improves execution time and energy consumption of a given code by up to 12% and 6%, respectively. The Performance Estimator and the Phase Selection Policy can be trained efficiently for any target platform and application domain.
Q-CapsNets: A Specialized Framework for Quantizing Capsule Networks
Apr 17, 2020
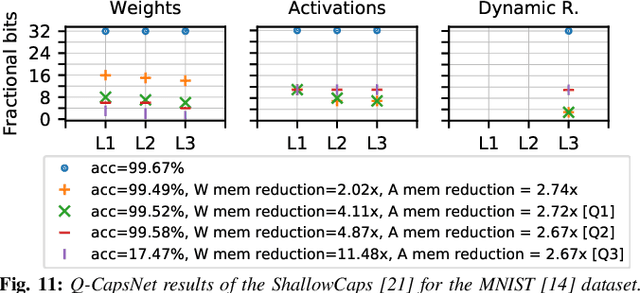
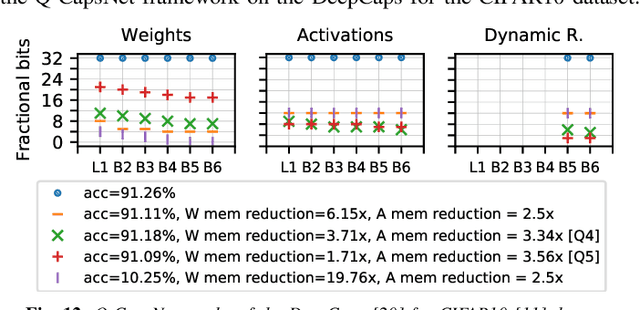
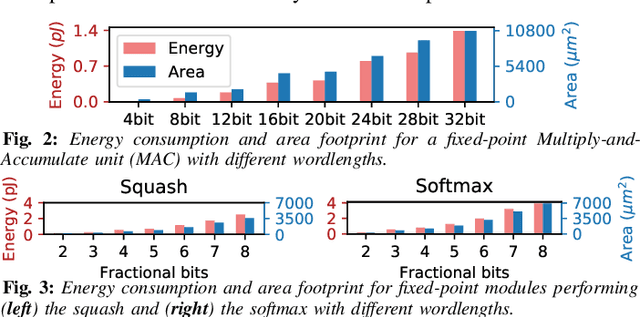
Capsule Networks (CapsNets), recently proposed by the Google Brain team, have superior learning capabilities in machine learning tasks, like image classification, compared to the traditional CNNs. However, CapsNets require extremely intense computations and are difficult to be deployed in their original form at the resource-constrained edge devices. This paper makes the first attempt to quantize CapsNet models, to enable their efficient edge implementations, by developing a specialized quantization framework for CapsNets. We evaluate our framework for several benchmarks. On a deep CapsNet model for the CIFAR10 dataset, the framework reduces the memory footprint by 6.2x, with only 0.15% accuracy loss. We will open-source our framework at https://git.io/JvDIF in August 2020.
X-TrainCaps: Accelerated Training of Capsule Nets through Lightweight Software Optimizations
May 24, 2019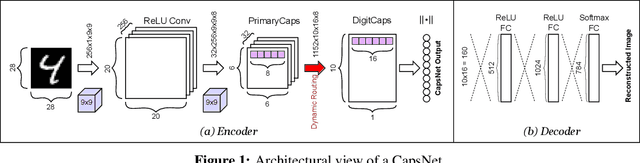
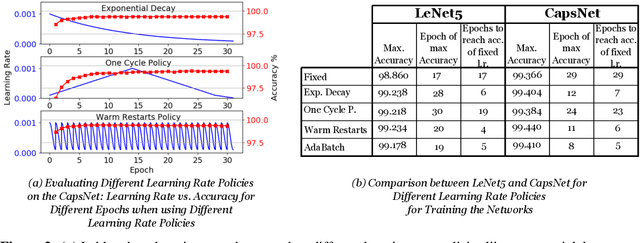
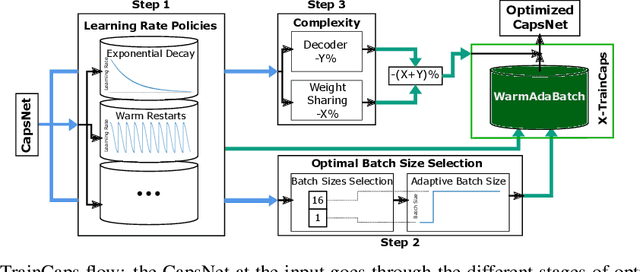
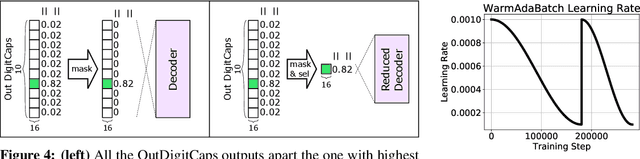
Convolutional Neural Networks (CNNs) are extensively in use due to their excellent results in various machine learning (ML) tasks like image classification and object detection. Recently, Capsule Networks (CapsNets) have shown improved performances compared to the traditional CNNs, by encoding and preserving spatial relationships between the detected features in a better way. This is achieved through the so-called Capsules (i.e., groups of neurons) that encode both the instantiation probability and the spatial information. However, one of the major hurdles in the wide adoption of CapsNets is its gigantic training time, which is primarily due to the relatively higher complexity of its constituting elements. In this paper, we illustrate how can we devise new optimizations in the training process to achieve fast training of CapsNets, and if such optimizations affect the network accuracy or not. Towards this, we propose a novel framework "X-TrainCaps" that employs lightweight software-level optimizations, including a novel learning rate policy called WarmAdaBatch that jointly performs warm restarts and adaptive batch size, as well as weight sharing for capsule layers to reduce the hardware requirements of CapsNets by removing unused/redundant connections and capsules, while keeping high accuracy through tests of different learning rate policies and batch sizes. We demonstrate that one of the solutions generated by X-TrainCaps framework can achieve 58.6% training time reduction while preserving the accuracy (even 0.9% accuracy improvement), compared to the CapsNet in the original paper by Sabour et al. (2017), while other Pareto-optimal solutions can be leveraged to realize trade-offs between training time and achieved accuracy.