 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeISimDL: Importance Sampling-Driven Acceleration of Fault Injection Simulations for Evaluating the Robustness of Deep Learning
Mar 14, 2023Deep Learning (DL) systems have proliferated in many applications, requiring specialized hardware accelerators and chips. In the nano-era, devices have become increasingly more susceptible to permanent and transient faults. Therefore, we need an efficient methodology for analyzing the resilience of advanced DL systems against such faults, and understand how the faults in neural accelerator chips manifest as errors at the DL application level, where faults can lead to undetectable and unrecoverable errors. Using fault injection, we can perform resilience investigations of the DL system by modifying neuron weights and outputs at the software-level, as if the hardware had been affected by a transient fault. Existing fault models reduce the search space, allowing faster analysis, but requiring a-priori knowledge on the model, and not allowing further analysis of the filtered-out search space. Therefore, we propose ISimDL, a novel methodology that employs neuron sensitivity to generate importance sampling-based fault-scenarios. Without any a-priori knowledge of the model-under-test, ISimDL provides an equivalent reduction of the search space as existing works, while allowing long simulations to cover all the possible faults, improving on existing model requirements. Our experiments show that the importance sampling provides up to 15x higher precision in selecting critical faults than the random uniform sampling, reaching such precision in less than 100 faults. Additionally, we showcase another practical use-case for importance sampling for reliable DNN design, namely Fault Aware Training (FAT). By using ISimDL to select the faults leading to errors, we can insert the faults during the DNN training process to harden the DNN against such faults. Using importance sampling in FAT reduces the overhead required for finding faults that lead to a predetermined drop in accuracy by more than 12x.
enpheeph: A Fault Injection Framework for Spiking and Compressed Deep Neural Networks
Jul 31, 2022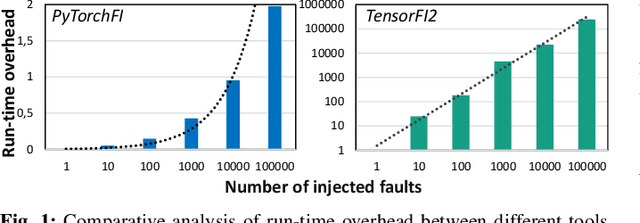
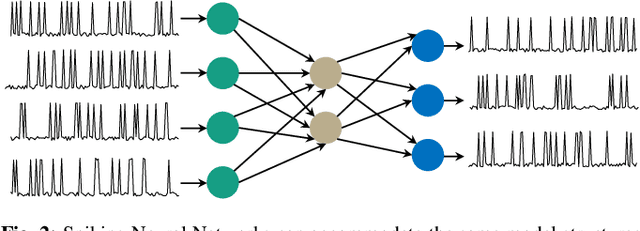
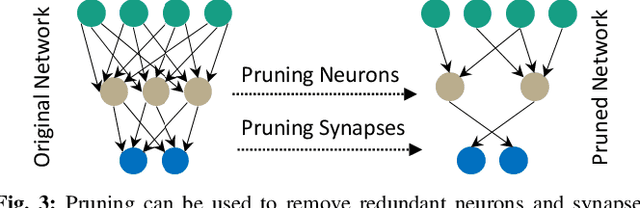
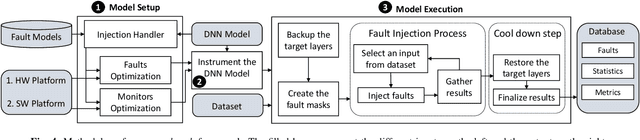
Research on Deep Neural Networks (DNNs) has focused on improving performance and accuracy for real-world deployments, leading to new models, such as Spiking Neural Networks (SNNs), and optimization techniques, e.g., quantization and pruning for compressed networks. However, the deployment of these innovative models and optimization techniques introduces possible reliability issues, which is a pillar for DNNs to be widely used in safety-critical applications, e.g., autonomous driving. Moreover, scaling technology nodes have the associated risk of multiple faults happening at the same time, a possibility not addressed in state-of-the-art resiliency analyses. Towards better reliability analysis for DNNs, we present enpheeph, a Fault Injection Framework for Spiking and Compressed DNNs. The enpheeph framework enables optimized execution on specialized hardware devices, e.g., GPUs, while providing complete customizability to investigate different fault models, emulating various reliability constraints and use-cases. Hence, the faults can be executed on SNNs as well as compressed networks with minimal-to-none modifications to the underlying code, a feat that is not achievable by other state-of-the-art tools. To evaluate our enpheeph framework, we analyze the resiliency of different DNN and SNN models, with different compression techniques. By injecting a random and increasing number of faults, we show that DNNs can show a reduction in accuracy with a fault rate as low as 7 x 10 ^ (-7) faults per parameter, with an accuracy drop higher than 40%. Run-time overhead when executing enpheeph is less than 20% of the baseline execution time when executing 100 000 faults concurrently, at least 10x lower than state-of-the-art frameworks, making enpheeph future-proof for complex fault injection scenarios. We release enpheeph at https://github.com/Alexei95/enpheeph.