 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwiftTron: An Efficient Hardware Accelerator for Quantized Transformers
Apr 25, 2023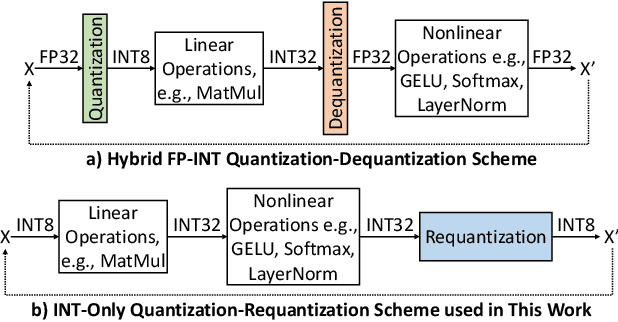
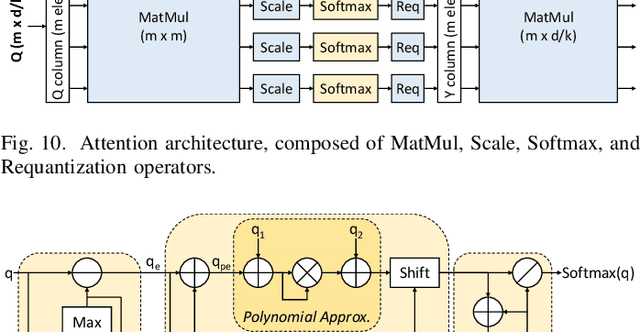
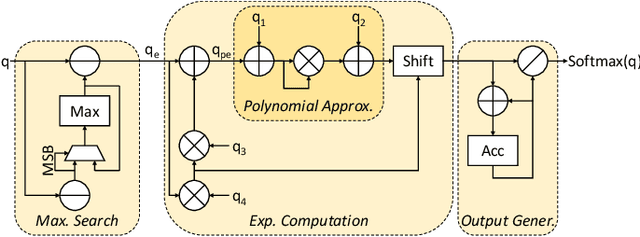

Transformers' compute-intensive operations pose enormous challenges for their deployment in resource-constrained EdgeAI / tinyML devices. As an established neural network compression technique, quantization reduces the hardware computational and memory resources. In particular, fixed-point quantization is desirable to ease the computations using lightweight blocks, like adders and multipliers, of the underlying hardware. However, deploying fully-quantized Transformers on existing general-purpose hardware, generic AI accelerators, or specialized architectures for Transformers with floating-point units might be infeasible and/or inefficient. Towards this, we propose SwiftTron, an efficient specialized hardware accelerator designed for Quantized Transformers. SwiftTron supports the execution of different types of Transformers' operations (like Attention, Softmax, GELU, and Layer Normalization) and accounts for diverse scaling factors to perform correct computations. We synthesize the complete SwiftTron architecture in a $65$ nm CMOS technology with the ASIC design flow. Our Accelerator executes the RoBERTa-base model in 1.83 ns, while consuming 33.64 mW power, and occupying an area of 273 mm^2. To ease the reproducibility, the RTL of our SwiftTron architecture is released at https://github.com/albertomarchisio/SwiftTron.