 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't be so Stief! Learning KV Cache low-rank approximation over the Stiefel manifold
Jan 29, 2026Key--value (KV) caching enables fast autoregressive decoding but at long contexts becomes a dominant bottleneck in High Bandwidth Memory (HBM) capacity and bandwidth. A common mitigation is to compress cached keys and values by projecting per-head matrixes to a lower rank, storing only the projections in the HBM. However, existing post-training approaches typically fit these projections using SVD-style proxy objectives, which may poorly reflect end-to-end reconstruction after softmax, value mixing, and subsequent decoder-layer transformations. For these reasons, we introduce StiefAttention, a post-training KV-cache compression method that learns \emph{orthonormal} projection bases by directly minimizing \emph{decoder-layer output reconstruction error}. StiefAttention additionally precomputes, for each layer, an error-rank profile over candidate ranks, enabling flexible layer-wise rank allocation under a user-specified error budget. Noteworthy, on Llama3-8B under the same conditions, StiefAttention outperforms EigenAttention by $11.9$ points on C4 perplexity and $5.4\%$ on 0-shot MMLU accuracy at iso-compression, yielding lower relative error and higher cosine similarity with respect to the original decoder-layer outputs.
MEbots: Integrating a RISC-V Virtual Platform with a Robotic Simulator for Energy-aware Design
May 22, 2025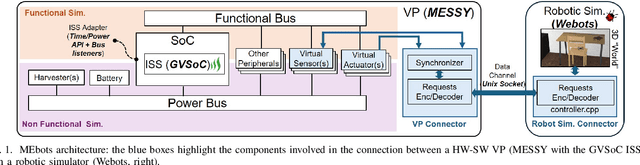
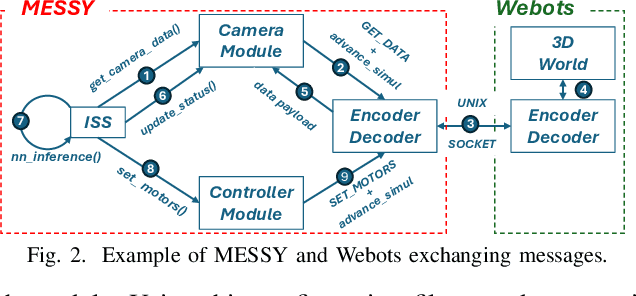
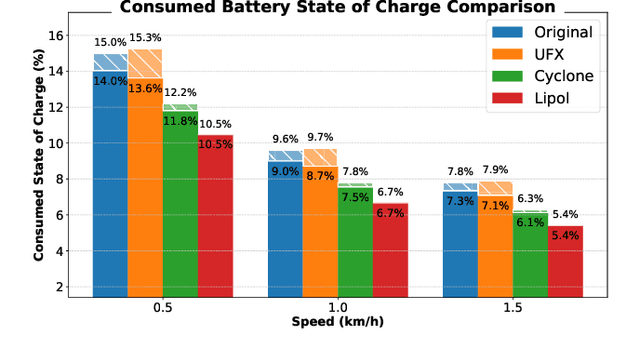
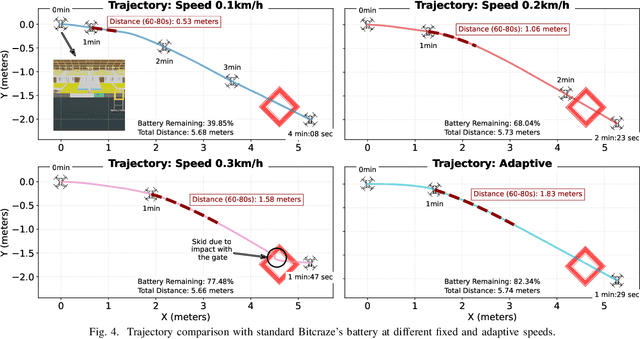
Virtual Platforms (VPs) enable early software validation of autonomous systems' electronics, reducing costs and time-to-market. While many VPs support both functional and non-functional simulation (e.g., timing, power), they lack the capability of simulating the environment in which the system operates. In contrast, robotics simulators lack accurate timing and power features. This twofold shortcoming limits the effectiveness of the design flow, as the designer can not fully evaluate the features of the solution under development. This paper presents a novel, fully open-source framework bridging this gap by integrating a robotics simulator (Webots) with a VP for RISC-V-based systems (MESSY). The framework enables a holistic, mission-level, energy-aware co-simulation of electronics in their surrounding environment, streamlining the exploration of design configurations and advanced power management policies.
Building Damage Assessment in Conflict Zones: A Deep Learning Approach Using Geospatial Sub-Meter Resolution Data
Oct 07, 2024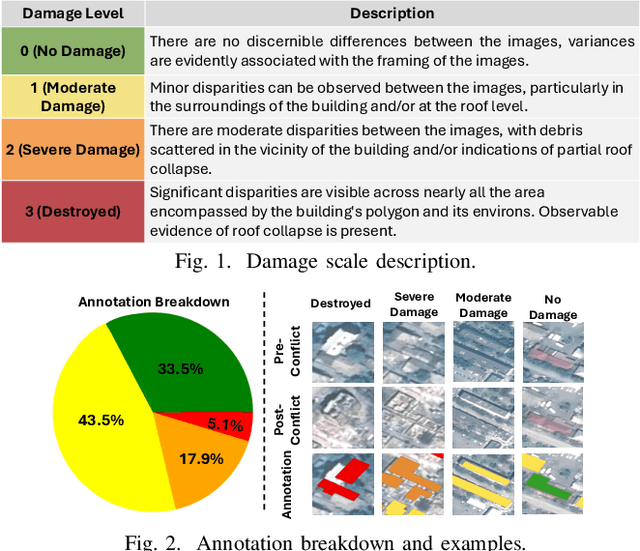
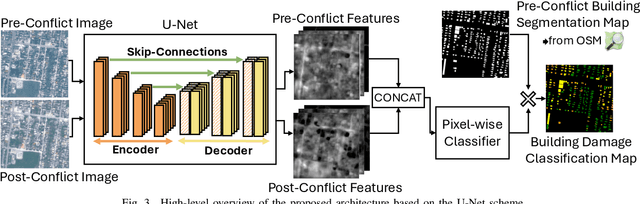
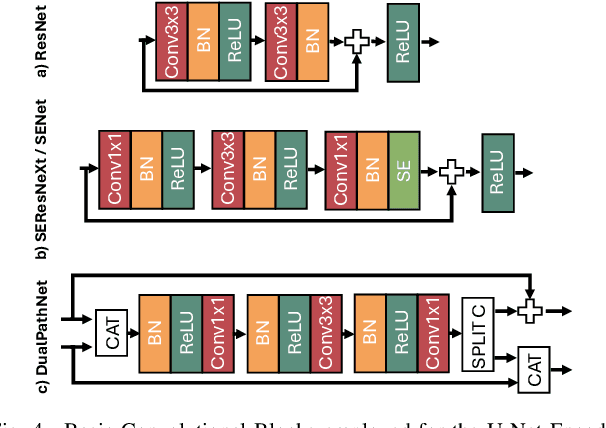
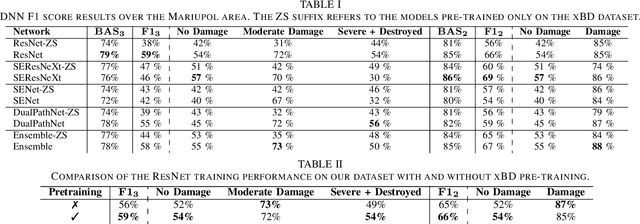
Very High Resolution (VHR) geospatial image analysis is crucial for humanitarian assistance in both natural and anthropogenic crises, as it allows to rapidly identify the most critical areas that need support. Nonetheless, manually inspecting large areas is time-consuming and requires domain expertise. Thanks to their accuracy, generalization capabilities, and highly parallelizable workload, Deep Neural Networks (DNNs) provide an excellent way to automate this task. Nevertheless, there is a scarcity of VHR data pertaining to conflict situations, and consequently, of studies on the effectiveness of DNNs in those scenarios. Motivated by this, our work extensively studies the applicability of a collection of state-of-the-art Convolutional Neural Networks (CNNs) originally developed for natural disasters damage assessment in a war scenario. To this end, we build an annotated dataset with pre- and post-conflict images of the Ukrainian city of Mariupol. We then explore the transferability of the CNN models in both zero-shot and learning scenarios, demonstrating their potential and limitations. To the best of our knowledge, this is the first study to use sub-meter resolution imagery to assess building damage in combat zones.
Optimizing DNN Inference on Multi-Accelerator SoCs at Training-time
Sep 27, 2024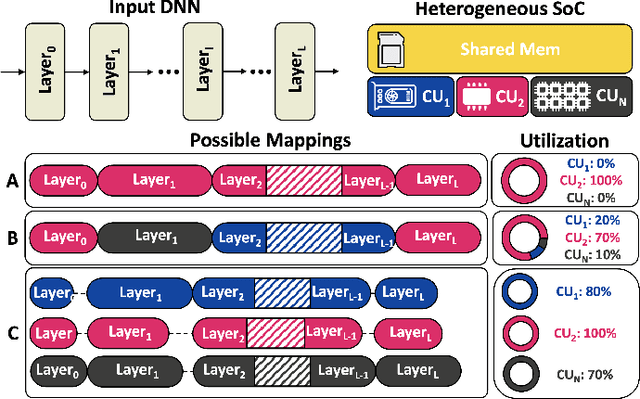
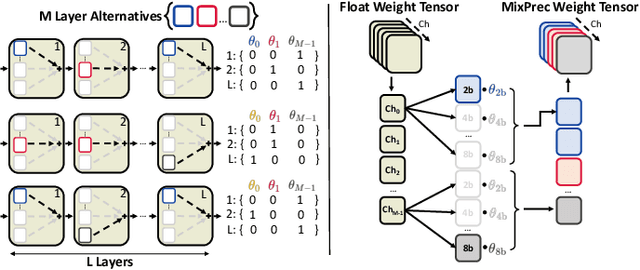
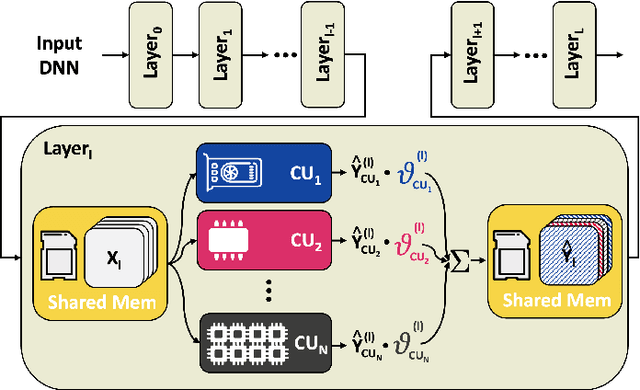
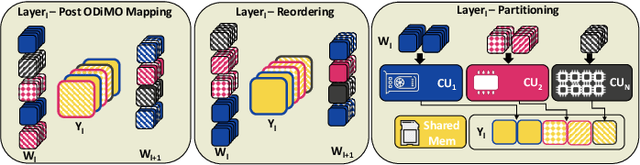
The demand for executing Deep Neural Networks (DNNs) with low latency and minimal power consumption at the edge has led to the development of advanced heterogeneous Systems-on-Chips (SoCs) that incorporate multiple specialized computing units (CUs), such as accelerators. Offloading DNN computations to a specific CU from the available set often exposes accuracy vs efficiency trade-offs, due to differences in their supported operations (e.g., standard vs. depthwise convolution) or data representations (e.g., more/less aggressively quantized). A challenging yet unresolved issue is how to map a DNN onto these multi-CU systems to maximally exploit the parallelization possibilities while taking accuracy into account. To address this problem, we present ODiMO, a hardware-aware tool that efficiently explores fine-grain mapping of DNNs among various on-chip CUs, during the training phase. ODiMO strategically splits individual layers of the neural network and executes them in parallel on the multiple available CUs, aiming to balance the total inference energy consumption or latency with the resulting accuracy, impacted by the unique features of the different hardware units. We test our approach on CIFAR-10, CIFAR-100, and ImageNet, targeting two open-source heterogeneous SoCs, i.e., DIANA and Darkside. We obtain a rich collection of Pareto-optimal networks in the accuracy vs. energy or latency space. We show that ODiMO reduces the latency of a DNN executed on the Darkside SoC by up to 8x at iso-accuracy, compared to manual heuristic mappings. When targeting energy, on the same SoC, ODiMO produced up to 50.8x more efficient mappings, with minimal accuracy drop (< 0.3%).
Joint Pruning and Channel-wise Mixed-Precision Quantization for Efficient Deep Neural Networks
Jul 01, 2024The resource requirements of deep neural networks (DNNs) pose significant challenges to their deployment on edge devices. Common approaches to address this issue are pruning and mixed-precision quantization, which lead to latency and memory occupation improvements. These optimization techniques are usually applied independently. We propose a novel methodology to apply them jointly via a lightweight gradient-based search, and in a hardware-aware manner, greatly reducing the time required to generate Pareto-optimal DNNs in terms of accuracy versus cost (i.e., latency or memory). We test our approach on three edge-relevant benchmarks, namely CIFAR-10, Google Speech Commands, and Tiny ImageNet. When targeting the optimization of the memory footprint, we are able to achieve a size reduction of 47.50% and 69.54% at iso-accuracy with the baseline networks with all weights quantized at 8 and 2-bit, respectively. Our method surpasses a previous state-of-the-art approach with up to 56.17% size reduction at iso-accuracy. With respect to the sequential application of state-of-the-art pruning and mixed-precision optimizations, we obtain comparable or superior results, but with a significantly lowered training time. In addition, we show how well-tailored cost models can improve the cost versus accuracy trade-offs when targeting specific hardware for deployment.
Optimized Deployment of Deep Neural Networks for Visual Pose Estimation on Nano-drones
Feb 23, 2024Miniaturized autonomous unmanned aerial vehicles (UAVs) are gaining popularity due to their small size, enabling new tasks such as indoor navigation or people monitoring. Nonetheless, their size and simple electronics pose severe challenges in implementing advanced onboard intelligence. This work proposes a new automatic optimization pipeline for visual pose estimation tasks using Deep Neural Networks (DNNs). The pipeline leverages two different Neural Architecture Search (NAS) algorithms to pursue a vast complexity-driven exploration in the DNNs' architectural space. The obtained networks are then deployed on an off-the-shelf nano-drone equipped with a parallel ultra-low power System-on-Chip leveraging a set of novel software kernels for the efficient fused execution of critical DNN layer sequences. Our results improve the state-of-the-art reducing inference latency by up to 3.22x at iso-error.
HW-SW Optimization of DNNs for Privacy-preserving People Counting on Low-resolution Infrared Arrays
Feb 02, 2024



Low-resolution infrared (IR) array sensors enable people counting applications such as monitoring the occupancy of spaces and people flows while preserving privacy and minimizing energy consumption. Deep Neural Networks (DNNs) have been shown to be well-suited to process these sensor data in an accurate and efficient manner. Nevertheless, the space of DNNs' architectures is huge and its manual exploration is burdensome and often leads to sub-optimal solutions. To overcome this problem, in this work, we propose a highly automated full-stack optimization flow for DNNs that goes from neural architecture search, mixed-precision quantization, and post-processing, down to the realization of a new smart sensor prototype, including a Microcontroller with a customized instruction set. Integrating these cross-layer optimizations, we obtain a large set of Pareto-optimal solutions in the 3D-space of energy, memory, and accuracy. Deploying such solutions on our hardware platform, we improve the state-of-the-art achieving up to 4.2x model size reduction, 23.8x code size reduction, and 15.38x energy reduction at iso-accuracy.
Adaptive Deep Learning for Efficient Visual Pose Estimation aboard Ultra-low-power Nano-drones
Jan 26, 2024



Sub-10cm diameter nano-drones are gaining momentum thanks to their applicability in scenarios prevented to bigger flying drones, such as in narrow environments and close to humans. However, their tiny form factor also brings their major drawback: ultra-constrained memory and processors for the onboard execution of their perception pipelines. Therefore, lightweight deep learning-based approaches are becoming increasingly popular, stressing how computational efficiency and energy-saving are paramount as they can make the difference between a fully working closed-loop system and a failing one. In this work, to maximize the exploitation of the ultra-limited resources aboard nano-drones, we present a novel adaptive deep learning-based mechanism for the efficient execution of a vision-based human pose estimation task. We leverage two State-of-the-Art (SoA) convolutional neural networks (CNNs) with different regression performance vs. computational costs trade-offs. By combining these CNNs with three novel adaptation strategies based on the output's temporal consistency and on auxiliary tasks to swap the CNN being executed proactively, we present six different systems. On a real-world dataset and the actual nano-drone hardware, our best-performing system, compared to executing only the bigger and most accurate SoA model, shows 28% latency reduction while keeping the same mean absolute error (MAE), 3% MAE reduction while being iso-latency, and the absolute peak performance, i.e., 6% better than SoA model.
Enhancing Neural Architecture Search with Multiple Hardware Constraints for Deep Learning Model Deployment on Tiny IoT Devices
Oct 11, 2023The rapid proliferation of computing domains relying on Internet of Things (IoT) devices has created a pressing need for efficient and accurate deep-learning (DL) models that can run on low-power devices. However, traditional DL models tend to be too complex and computationally intensive for typical IoT end-nodes. To address this challenge, Neural Architecture Search (NAS) has emerged as a popular design automation technique for co-optimizing the accuracy and complexity of deep neural networks. Nevertheless, existing NAS techniques require many iterations to produce a network that adheres to specific hardware constraints, such as the maximum memory available on the hardware or the maximum latency allowed by the target application. In this work, we propose a novel approach to incorporate multiple constraints into so-called Differentiable NAS optimization methods, which allows the generation, in a single shot, of a model that respects user-defined constraints on both memory and latency in a time comparable to a single standard training. The proposed approach is evaluated on five IoT-relevant benchmarks, including the MLPerf Tiny suite and Tiny ImageNet, demonstrating that, with a single search, it is possible to reduce memory and latency by 87.4% and 54.2%, respectively (as defined by our targets), while ensuring non-inferior accuracy on state-of-the-art hand-tuned deep neural networks for TinyML.
PLiNIO: A User-Friendly Library of Gradient-based Methods for Complexity-aware DNN Optimization
Jul 18, 2023



Accurate yet efficient Deep Neural Networks (DNNs) are in high demand, especially for applications that require their execution on constrained edge devices. Finding such DNNs in a reasonable time for new applications requires automated optimization pipelines since the huge space of hyper-parameter combinations is impossible to explore extensively by hand. In this work, we propose PLiNIO, an open-source library implementing a comprehensive set of state-of-the-art DNN design automation techniques, all based on lightweight gradient-based optimization, under a unified and user-friendly interface. With experiments on several edge-relevant tasks, we show that combining the various optimizations available in PLiNIO leads to rich sets of solutions that Pareto-dominate the considered baselines in terms of accuracy vs model size. Noteworthy, PLiNIO achieves up to 94.34% memory reduction for a <1% accuracy drop compared to a baseline architecture.