 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEbots: Integrating a RISC-V Virtual Platform with a Robotic Simulator for Energy-aware Design
May 22, 2025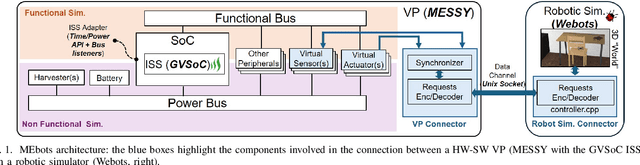
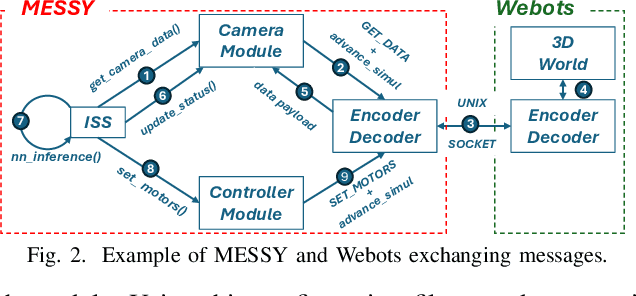
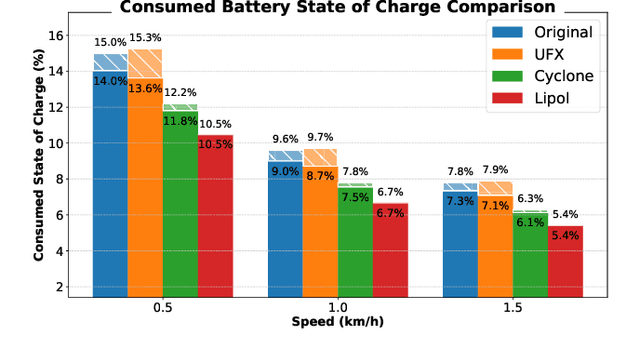
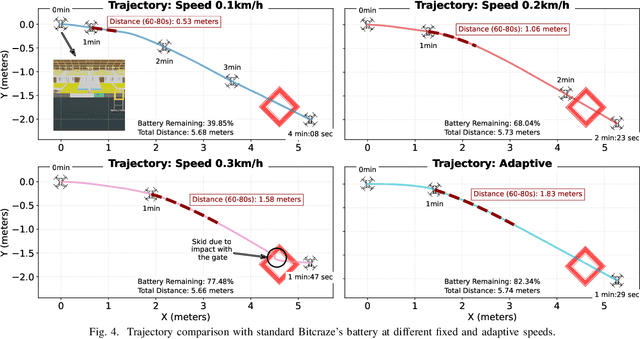
Virtual Platforms (VPs) enable early software validation of autonomous systems' electronics, reducing costs and time-to-market. While many VPs support both functional and non-functional simulation (e.g., timing, power), they lack the capability of simulating the environment in which the system operates. In contrast, robotics simulators lack accurate timing and power features. This twofold shortcoming limits the effectiveness of the design flow, as the designer can not fully evaluate the features of the solution under development. This paper presents a novel, fully open-source framework bridging this gap by integrating a robotics simulator (Webots) with a VP for RISC-V-based systems (MESSY). The framework enables a holistic, mission-level, energy-aware co-simulation of electronics in their surrounding environment, streamlining the exploration of design configurations and advanced power management policies.
SAfEPaTh: A System-Level Approach for Efficient Power and Thermal Estimation of Convolutional Neural Network Accelerator
Jul 24, 2024The design of energy-efficient, high-performance, and reliable Convolutional Neural Network (CNN) accelerators involves significant challenges due to complex power and thermal management issues. This paper introduces SAfEPaTh, a novel system-level approach for accurately estimating power and temperature in tile-based CNN accelerators. By addressing both steady-state and transient-state scenarios, SAfEPaTh effectively captures the dynamic effects of pipeline bubbles in interlayer pipelines, utilizing real CNN workloads for comprehensive evaluation. Unlike traditional methods, it eliminates the need for circuit-level simulations or on-chip measurements. Our methodology leverages TANIA, a cutting-edge hybrid digital-analog tile-based accelerator featuring analog-in-memory computing cores alongside digital cores. Through rigorous simulation results using the ResNet18 model, we demonstrate SAfEPaTh's capability to accurately estimate power and temperature within 500 seconds, encompassing CNN model accelerator mapping exploration and detailed power and thermal estimations. This efficiency and accuracy make SAfEPaTh an invaluable tool for designers, enabling them to optimize performance while adhering to stringent power and thermal constraints. Furthermore, SAfEPaTh's adaptability extends its utility across various CNN models and accelerator architectures, underscoring its broad applicability in the field. This study contributes significantly to the advancement of energy-efficient and reliable CNN accelerator designs, addressing critical challenges in dynamic power and thermal management.
Model-Driven Dataset Generation for Data-Driven Battery SOH Models
Jan 10, 2024



Estimating the State of Health (SOH) of batteries is crucial for ensuring the reliable operation of battery systems. Since there is no practical way to instantaneously measure it at run time, a model is required for its estimation. Recently, several data-driven SOH models have been proposed, whose accuracy heavily relies on the quality of the datasets used for their training. Since these datasets are obtained from measurements, they are limited in the variety of the charge/discharge profiles. To address this scarcity issue, we propose generating datasets by simulating a traditional battery model (e.g., a circuit-equivalent one). The primary advantage of this approach is the ability to use a simulatable battery model to evaluate a potentially infinite number of workload profiles for training the data-driven model. Furthermore, this general concept can be applied using any simulatable battery model, providing a fine spectrum of accuracy/complexity tradeoffs. Our results indicate that using simulated data achieves reasonable accuracy in SOH estimation, with a 7.2% error relative to the simulated model, in exchange for a 27X memory reduction and a =2000X speedup.
Energy-efficient Wearable-to-Mobile Offload of ML Inference for PPG-based Heart-Rate Estimation
Jun 08, 2023Modern smartwatches often include photoplethysmographic (PPG) sensors to measure heartbeats or blood pressure through complex algorithms that fuse PPG data with other signals. In this work, we propose a collaborative inference approach that uses both a smartwatch and a connected smartphone to maximize the performance of heart rate (HR) tracking while also maximizing the smartwatch's battery life. In particular, we first analyze the trade-offs between running on-device HR tracking or offloading the work to the mobile. Then, thanks to an additional step to evaluate the difficulty of the upcoming HR prediction, we demonstrate that we can smartly manage the workload between smartwatch and smartphone, maintaining a low mean absolute error (MAE) while reducing energy consumption. We benchmark our approach on a custom smartwatch prototype, including the STM32WB55 MCU and Bluetooth Low-Energy (BLE) communication, and a Raspberry Pi3 as a proxy for the smartphone. With our Collaborative Heart Rate Inference System (CHRIS), we obtain a set of Pareto-optimal configurations demonstrating the same MAE as State-of-Art (SoA) algorithms while consuming less energy. For instance, we can achieve approximately the same MAE of TimePPG-Small (5.54 BPM MAE vs. 5.60 BPM MAE) while reducing the energy by 2.03x, with a configuration that offloads 80\% of the predictions to the phone. Furthermore, accepting a performance degradation to 7.16 BPM of MAE, we can achieve an energy consumption of 179 uJ per prediction, 3.03x less than running TimePPG-Small on the smartwatch, and 1.82x less than streaming all the input data to the phone.
* Published at 2023 Design, Automation \& Test in Europe Conference \& Exhibition (DATE)
Efficient Deep Learning Models for Privacy-preserving People Counting on Low-resolution Infrared Arrays
Apr 12, 2023

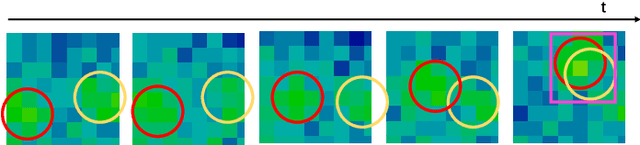

Ultra-low-resolution Infrared (IR) array sensors offer a low-cost, energy-efficient, and privacy-preserving solution for people counting, with applications such as occupancy monitoring. Previous work has shown that Deep Learning (DL) can yield superior performance on this task. However, the literature was missing an extensive comparative analysis of various efficient DL architectures for IR array-based people counting, that considers not only their accuracy, but also the cost of deploying them on memory- and energy-constrained Internet of Things (IoT) edge nodes. In this work, we address this need by comparing 6 different DL architectures on a novel dataset composed of IR images collected from a commercial 8x8 array, which we made openly available. With a wide architectural exploration of each model type, we obtain a rich set of Pareto-optimal solutions, spanning cross-validated balanced accuracy scores in the 55.70-82.70% range. When deployed on a commercial Microcontroller (MCU) by STMicroelectronics, the STM32L4A6ZG, these models occupy 0.41-9.28kB of memory, and require 1.10-7.74ms per inference, while consuming 17.18-120.43 $\mu$J of energy. Our models are significantly more accurate than a previous deterministic method (up to +39.9%), while being up to 3.53x faster and more energy efficient. Further, our models' accuracy is comparable to state-of-the-art DL solutions on similar resolution sensors, despite a much lower complexity. All our models enable continuous, real-time inference on a MCU-based IoT node, with years of autonomous operation without battery recharging.
Lightweight Neural Architecture Search for Temporal Convolutional Networks at the Edge
Jan 24, 2023Neural Architecture Search (NAS) is quickly becoming the go-to approach to optimize the structure of Deep Learning (DL) models for complex tasks such as Image Classification or Object Detection. However, many other relevant applications of DL, especially at the edge, are based on time-series processing and require models with unique features, for which NAS is less explored. This work focuses in particular on Temporal Convolutional Networks (TCNs), a convolutional model for time-series processing that has recently emerged as a promising alternative to more complex recurrent architectures. We propose the first NAS tool that explicitly targets the optimization of the most peculiar architectural parameters of TCNs, namely dilation, receptive-field and number of features in each layer. The proposed approach searches for networks that offer good trade-offs between accuracy and number of parameters/operations, enabling an efficient deployment on embedded platforms. We test the proposed NAS on four real-world, edge-relevant tasks, involving audio and bio-signals. Results show that, starting from a single seed network, our method is capable of obtaining a rich collection of Pareto optimal architectures, among which we obtain models with the same accuracy as the seed, and 15.9-152x fewer parameters. Compared to three state-of-the-art NAS tools, ProxylessNAS, MorphNet and FBNetV2, our method explores a larger search space for TCNs (up to 10^12x) and obtains superior solutions, while requiring low GPU memory and search time. We deploy our NAS outputs on two distinct edge devices, the multicore GreenWaves Technology GAP8 IoT processor and the single-core STMicroelectronics STM32H7 microcontroller. With respect to the state-of-the-art hand-tuned models, we reduce latency and energy of up to 5.5x and 3.8x on the two targets respectively, without any accuracy loss.
A Machine Learning-based Digital Twin for Electric Vehicle Battery Modeling
Jun 16, 2022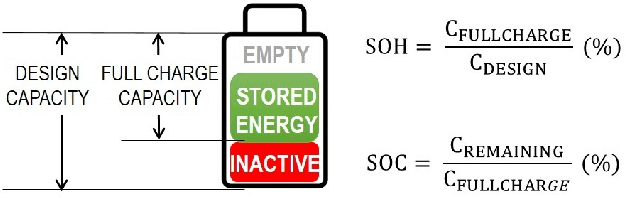
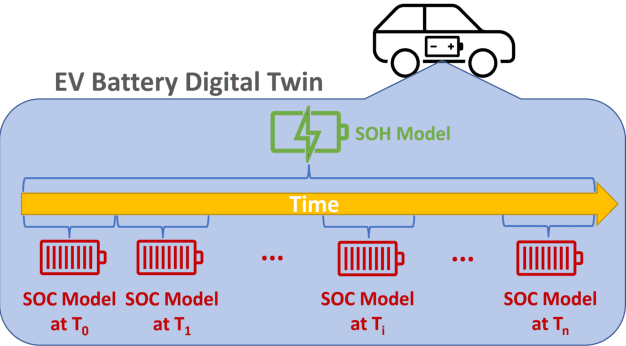
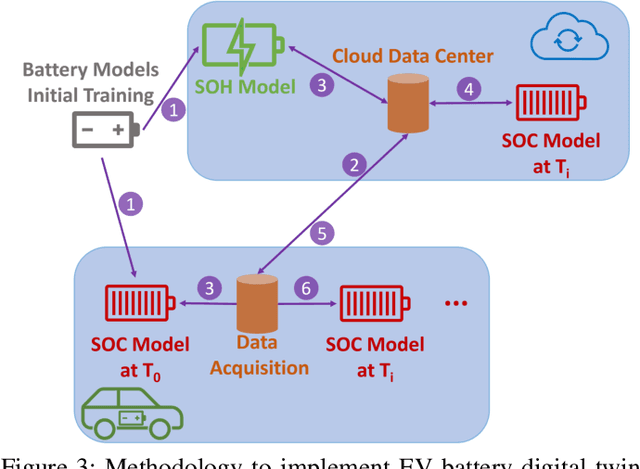
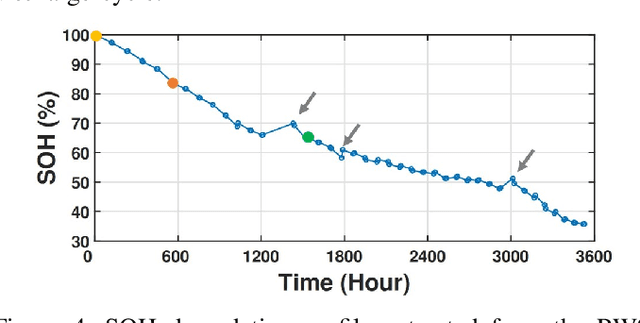
The widespread adoption of Electric Vehicles (EVs) is limited by their reliance on batteries with presently low energy and power densities compared to liquid fuels and are subject to aging and performance deterioration over time. For this reason, monitoring the battery State Of Charge (SOC) and State Of Health (SOH) during the EV lifetime is a very relevant problem. This work proposes a battery digital twin structure designed to accurately reflect battery dynamics at the run time. To ensure a high degree of correctness concerning non-linear phenomena, the digital twin relies on data-driven models trained on traces of battery evolution over time: a SOH model, repeatedly executed to estimate the degradation of maximum battery capacity, and a SOC model, retrained periodically to reflect the impact of aging. The proposed digital twin structure will be exemplified on a public dataset to motivate its adoption and prove its effectiveness, with high accuracy and inference and retraining times compatible with onboard execution.
Privacy-preserving Social Distance Monitoring on Microcontrollers with Low-Resolution Infrared Sensors and CNNs
Apr 22, 2022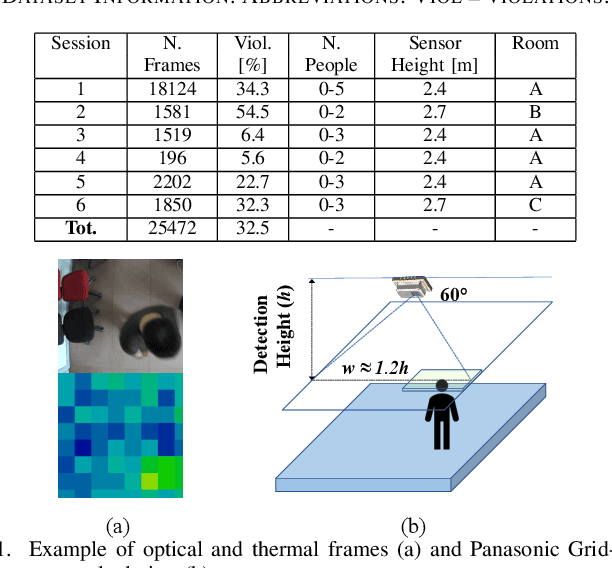


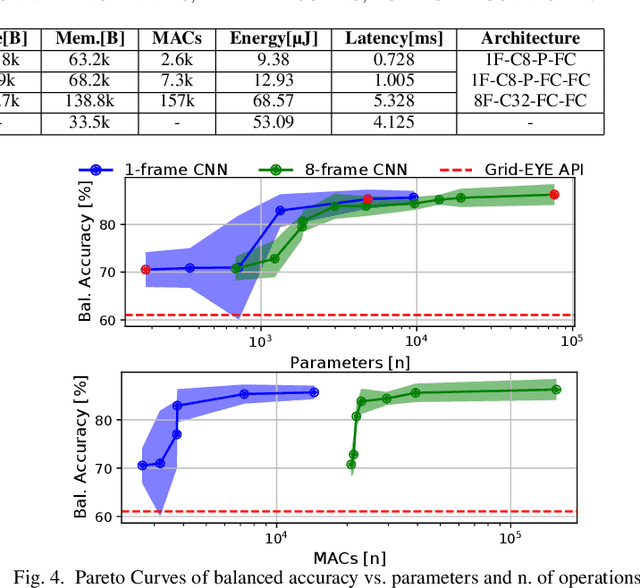
Low-resolution infrared (IR) array sensors offer a low-cost, low-power, and privacy-preserving alternative to optical cameras and smartphones/wearables for social distance monitoring in indoor spaces, permitting the recognition of basic shapes, without revealing the personal details of individuals. In this work, we demonstrate that an accurate detection of social distance violations can be achieved processing the raw output of a 8x8 IR array sensor with a small-sized Convolutional Neural Network (CNN). Furthermore, the CNN can be executed directly on a Microcontroller (MCU)-based sensor node. With results on a newly collected open dataset, we show that our best CNN achieves 86.3% balanced accuracy, significantly outperforming the 61% achieved by a state-of-the-art deterministic algorithm. Changing the architectural parameters of the CNN, we obtain a rich Pareto set of models, spanning 70.5-86.3% accuracy and 0.18-75k parameters. Deployed on a STM32L476RG MCU, these models have a latency of 0.73-5.33ms, with an energy consumption per inference of 9.38-68.57{\mu}J.
C-NMT: A Collaborative Inference Framework for Neural Machine Translation
Apr 08, 2022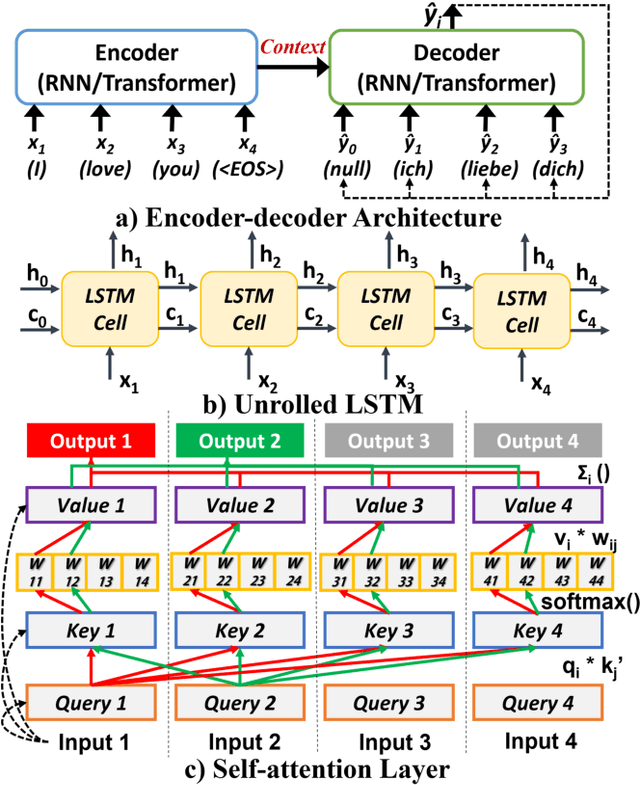
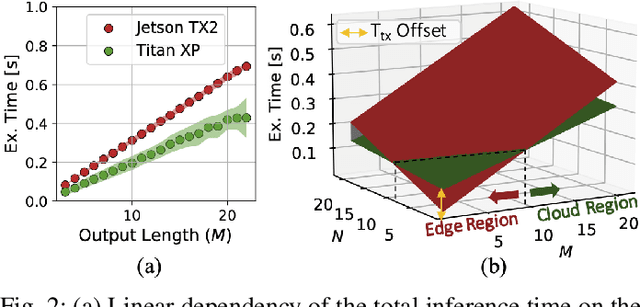
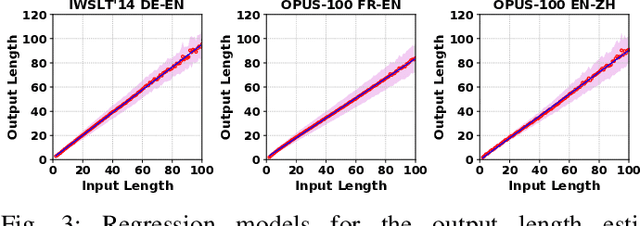

Collaborative Inference (CI) optimizes the latency and energy consumption of deep learning inference through the inter-operation of edge and cloud devices. Albeit beneficial for other tasks, CI has never been applied to the sequence- to-sequence mapping problem at the heart of Neural Machine Translation (NMT). In this work, we address the specific issues of collaborative NMT, such as estimating the latency required to generate the (unknown) output sequence, and show how existing CI methods can be adapted to these applications. Our experiments show that CI can reduce the latency of NMT by up to 44% compared to a non-collaborative approach.