 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Driven Dataset Generation for Data-Driven Battery SOH Models
Jan 10, 2024



Estimating the State of Health (SOH) of batteries is crucial for ensuring the reliable operation of battery systems. Since there is no practical way to instantaneously measure it at run time, a model is required for its estimation. Recently, several data-driven SOH models have been proposed, whose accuracy heavily relies on the quality of the datasets used for their training. Since these datasets are obtained from measurements, they are limited in the variety of the charge/discharge profiles. To address this scarcity issue, we propose generating datasets by simulating a traditional battery model (e.g., a circuit-equivalent one). The primary advantage of this approach is the ability to use a simulatable battery model to evaluate a potentially infinite number of workload profiles for training the data-driven model. Furthermore, this general concept can be applied using any simulatable battery model, providing a fine spectrum of accuracy/complexity tradeoffs. Our results indicate that using simulated data achieves reasonable accuracy in SOH estimation, with a 7.2% error relative to the simulated model, in exchange for a 27X memory reduction and a =2000X speedup.
A Machine Learning-based Digital Twin for Electric Vehicle Battery Modeling
Jun 16, 2022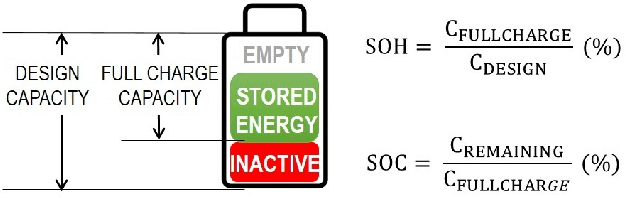
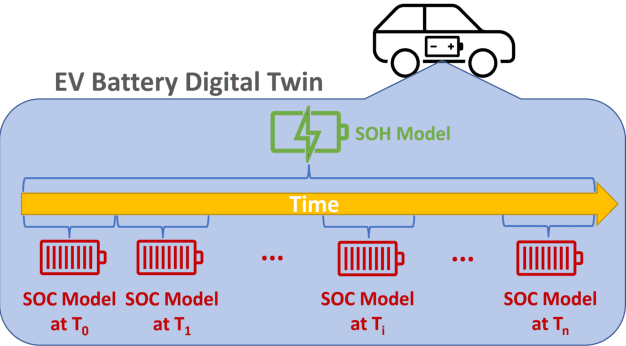
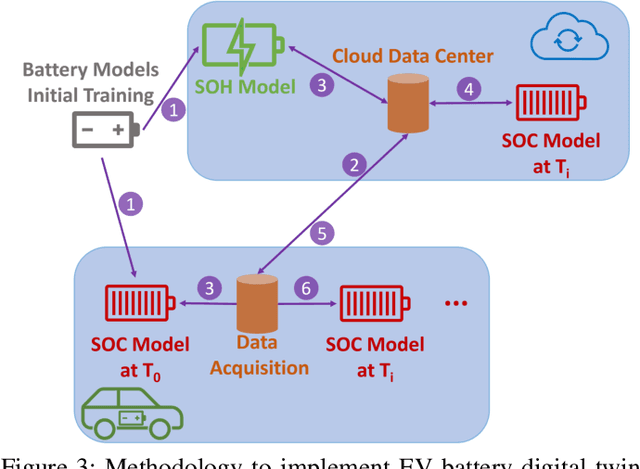
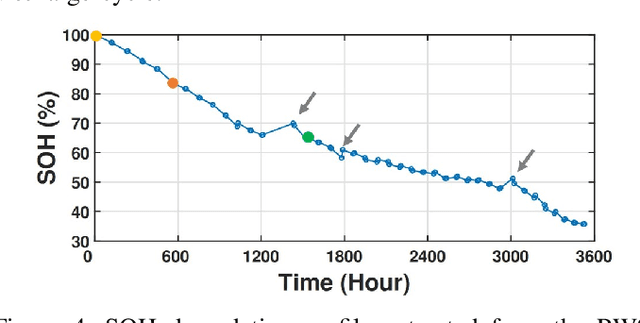
The widespread adoption of Electric Vehicles (EVs) is limited by their reliance on batteries with presently low energy and power densities compared to liquid fuels and are subject to aging and performance deterioration over time. For this reason, monitoring the battery State Of Charge (SOC) and State Of Health (SOH) during the EV lifetime is a very relevant problem. This work proposes a battery digital twin structure designed to accurately reflect battery dynamics at the run time. To ensure a high degree of correctness concerning non-linear phenomena, the digital twin relies on data-driven models trained on traces of battery evolution over time: a SOH model, repeatedly executed to estimate the degradation of maximum battery capacity, and a SOC model, retrained periodically to reflect the impact of aging. The proposed digital twin structure will be exemplified on a public dataset to motivate its adoption and prove its effectiveness, with high accuracy and inference and retraining times compatible with onboard execution.