 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEbots: Integrating a RISC-V Virtual Platform with a Robotic Simulator for Energy-aware Design
May 22, 2025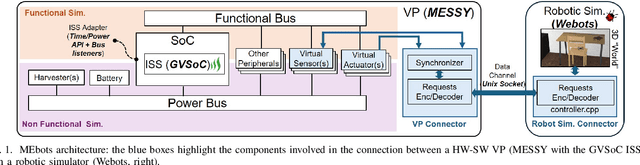
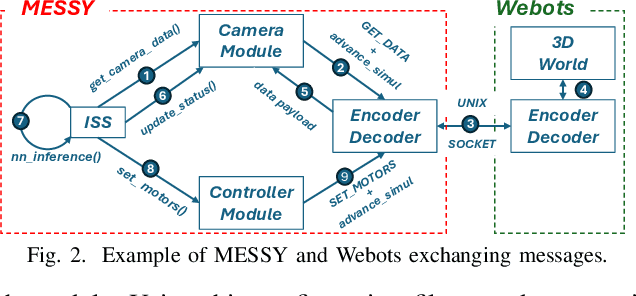
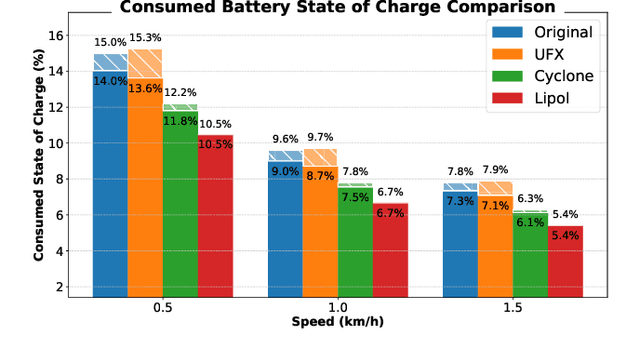
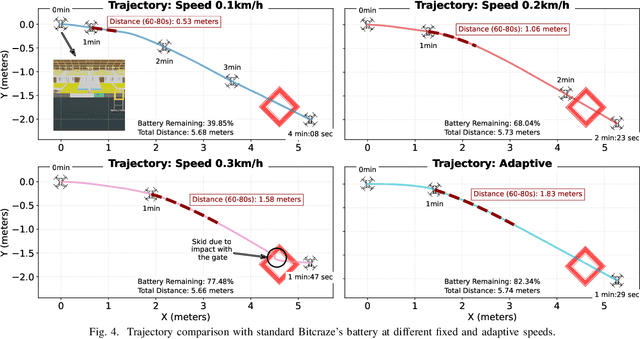
Virtual Platforms (VPs) enable early software validation of autonomous systems' electronics, reducing costs and time-to-market. While many VPs support both functional and non-functional simulation (e.g., timing, power), they lack the capability of simulating the environment in which the system operates. In contrast, robotics simulators lack accurate timing and power features. This twofold shortcoming limits the effectiveness of the design flow, as the designer can not fully evaluate the features of the solution under development. This paper presents a novel, fully open-source framework bridging this gap by integrating a robotics simulator (Webots) with a VP for RISC-V-based systems (MESSY). The framework enables a holistic, mission-level, energy-aware co-simulation of electronics in their surrounding environment, streamlining the exploration of design configurations and advanced power management policies.
Lightweight Software Kernels and Hardware Extensions for Efficient Sparse Deep Neural Networks on Microcontrollers
Mar 08, 2025The acceleration of pruned Deep Neural Networks (DNNs) on edge devices such as Microcontrollers (MCUs) is a challenging task, given the tight area- and power-constraints of these devices. In this work, we propose a three-fold contribution to address this problem. First, we design a set of optimized software kernels for N:M pruned layers, targeting ultra-low-power, multicore RISC-V MCUs, which are up to 2.1x and 3.4x faster than their dense counterparts at 1:8 and 1:16 sparsity, respectively. Then, we implement a lightweight Instruction-Set Architecture (ISA) extension to accelerate the indirect load and non-zero indices decompression operations required by our kernels, obtaining up to 1.9x extra speedup, at the cost of a 5% area overhead. Lastly, we extend an open-source DNN compiler to utilize our sparse kernels for complete networks, showing speedups of 3.21x and 1.81x on a ResNet18 and a Vision Transformer (ViT), with less than 1.5% accuracy drop compared to a dense baseline.
Coupling Neural Networks and Physics Equations For Li-Ion Battery State-of-Charge Prediction
Dec 21, 2024



Estimating the evolution of the battery's State of Charge (SoC) in response to its usage is critical for implementing effective power management policies and for ultimately improving the system's lifetime. Most existing estimation methods are either physics-based digital twins of the battery or data-driven models such as Neural Networks (NNs). In this work, we propose two new contributions in this domain. First, we introduce a novel NN architecture formed by two cascaded branches: one to predict the current SoC based on sensor readings, and one to estimate the SoC at a future time as a function of the load behavior. Second, we integrate battery dynamics equations into the training of our NN, merging the physics-based and data-driven approaches, to improve the models' generalization over variable prediction horizons. We validate our approach on two publicly accessible datasets, showing that our Physics-Informed Neural Networks (PINNs) outperform purely data-driven ones while also obtaining superior prediction accuracy with a smaller architecture with respect to the state-of-the-art.
EnhancePPG: Improving PPG-based Heart Rate Estimation with Self-Supervision and Augmentation
Dec 20, 2024



Heart rate (HR) estimation from photoplethysmography (PPG) signals is a key feature of modern wearable devices for health and wellness monitoring. While deep learning models show promise, their performance relies on the availability of large datasets. We present EnhancePPG, a method that enhances state-of-the-art models by integrating self-supervised learning with data augmentation (DA). Our approach combines self-supervised pre-training with DA, allowing the model to learn more generalizable features, without needing more labelled data. Inspired by a U-Net-like autoencoder architecture, we utilize unsupervised PPG signal reconstruction, taking advantage of large amounts of unlabeled data during the pre-training phase combined with data augmentation, to improve state-of-the-art models' performance. Thanks to our approach and minimal modification to the state-of-the-art model, we improve the best HR estimation by 12.2%, lowering from 4.03 Beats-Per-Minute (BPM) to 3.54 BPM the error on PPG-DaLiA. Importantly, our EnhancePPG approach focuses exclusively on the training of the selected deep learning model, without significantly increasing its inference latency
Building Damage Assessment in Conflict Zones: A Deep Learning Approach Using Geospatial Sub-Meter Resolution Data
Oct 07, 2024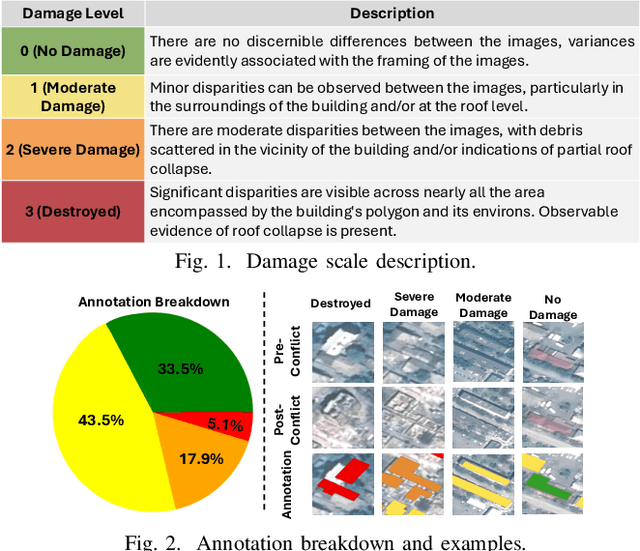
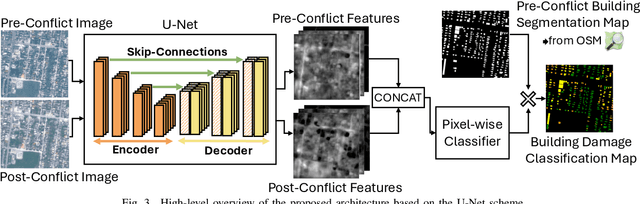
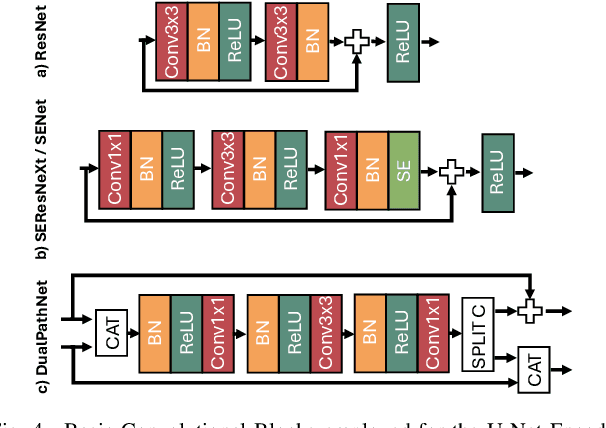
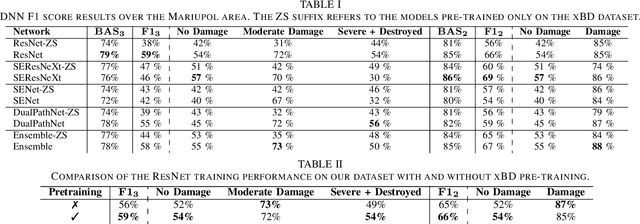
Very High Resolution (VHR) geospatial image analysis is crucial for humanitarian assistance in both natural and anthropogenic crises, as it allows to rapidly identify the most critical areas that need support. Nonetheless, manually inspecting large areas is time-consuming and requires domain expertise. Thanks to their accuracy, generalization capabilities, and highly parallelizable workload, Deep Neural Networks (DNNs) provide an excellent way to automate this task. Nevertheless, there is a scarcity of VHR data pertaining to conflict situations, and consequently, of studies on the effectiveness of DNNs in those scenarios. Motivated by this, our work extensively studies the applicability of a collection of state-of-the-art Convolutional Neural Networks (CNNs) originally developed for natural disasters damage assessment in a war scenario. To this end, we build an annotated dataset with pre- and post-conflict images of the Ukrainian city of Mariupol. We then explore the transferability of the CNN models in both zero-shot and learning scenarios, demonstrating their potential and limitations. To the best of our knowledge, this is the first study to use sub-meter resolution imagery to assess building damage in combat zones.
Joint Pruning and Channel-wise Mixed-Precision Quantization for Efficient Deep Neural Networks
Jul 01, 2024The resource requirements of deep neural networks (DNNs) pose significant challenges to their deployment on edge devices. Common approaches to address this issue are pruning and mixed-precision quantization, which lead to latency and memory occupation improvements. These optimization techniques are usually applied independently. We propose a novel methodology to apply them jointly via a lightweight gradient-based search, and in a hardware-aware manner, greatly reducing the time required to generate Pareto-optimal DNNs in terms of accuracy versus cost (i.e., latency or memory). We test our approach on three edge-relevant benchmarks, namely CIFAR-10, Google Speech Commands, and Tiny ImageNet. When targeting the optimization of the memory footprint, we are able to achieve a size reduction of 47.50% and 69.54% at iso-accuracy with the baseline networks with all weights quantized at 8 and 2-bit, respectively. Our method surpasses a previous state-of-the-art approach with up to 56.17% size reduction at iso-accuracy. With respect to the sequential application of state-of-the-art pruning and mixed-precision optimizations, we obtain comparable or superior results, but with a significantly lowered training time. In addition, we show how well-tailored cost models can improve the cost versus accuracy trade-offs when targeting specific hardware for deployment.
Accelerating Depthwise Separable Convolutions on Ultra-Low-Power Devices
Jun 18, 2024Depthwise separable convolutions are a fundamental component in efficient Deep Neural Networks, as they reduce the number of parameters and operations compared to traditional convolutions while maintaining comparable accuracy. However, their low data reuse opportunities make deploying them notoriously difficult. In this work, we perform an extensive exploration of alternatives to fuse the depthwise and pointwise kernels that constitute the separable convolutional block. Our approach aims to minimize time-consuming memory transfers by combining different data layouts. When targeting a commercial ultra-low-power device with a three-level memory hierarchy, the GreenWaves GAP8 SoC, we reduce the latency of end-to-end network execution by up to 11.40%. Furthermore, our kernels reduce activation data movements between L2 and L1 memories by up to 52.97%.
Foundation Models for Structural Health Monitoring
Apr 03, 2024



Structural Health Monitoring (SHM) is a critical task for ensuring the safety and reliability of civil infrastructures, typically realized on bridges and viaducts by means of vibration monitoring. In this paper, we propose for the first time the use of Transformer neural networks, with a Masked Auto-Encoder architecture, as Foundation Models for SHM. We demonstrate the ability of these models to learn generalizable representations from multiple large datasets through self-supervised pre-training, which, coupled with task-specific fine-tuning, allows them to outperform state-of-the-art traditional methods on diverse tasks, including Anomaly Detection (AD) and Traffic Load Estimation (TLE). We then extensively explore model size versus accuracy trade-offs and experiment with Knowledge Distillation (KD) to improve the performance of smaller Transformers, enabling their embedding directly into the SHM edge nodes. We showcase the effectiveness of our foundation models using data from three operational viaducts. For AD, we achieve a near-perfect 99.9% accuracy with a monitoring time span of just 15 windows. In contrast, a state-of-the-art method based on Principal Component Analysis (PCA) obtains its first good result (95.03% accuracy) only considering 120 windows. On two different TLE tasks, our models obtain state-of-the-art performance on multiple evaluation metrics (R$^2$ score, MAE% and MSE%). On the first benchmark, we achieve an R$^2$ score of 0.97 and 0.85 for light and heavy vehicle traffic, respectively, while the best previous approach stops at 0.91 and 0.84. On the second one, we achieve an R$^2$ score of 0.54 versus the 0.10 of the best existing method.
Optimized Deployment of Deep Neural Networks for Visual Pose Estimation on Nano-drones
Feb 23, 2024Miniaturized autonomous unmanned aerial vehicles (UAVs) are gaining popularity due to their small size, enabling new tasks such as indoor navigation or people monitoring. Nonetheless, their size and simple electronics pose severe challenges in implementing advanced onboard intelligence. This work proposes a new automatic optimization pipeline for visual pose estimation tasks using Deep Neural Networks (DNNs). The pipeline leverages two different Neural Architecture Search (NAS) algorithms to pursue a vast complexity-driven exploration in the DNNs' architectural space. The obtained networks are then deployed on an off-the-shelf nano-drone equipped with a parallel ultra-low power System-on-Chip leveraging a set of novel software kernels for the efficient fused execution of critical DNN layer sequences. Our results improve the state-of-the-art reducing inference latency by up to 3.22x at iso-error.
HW-SW Optimization of DNNs for Privacy-preserving People Counting on Low-resolution Infrared Arrays
Feb 02, 2024



Low-resolution infrared (IR) array sensors enable people counting applications such as monitoring the occupancy of spaces and people flows while preserving privacy and minimizing energy consumption. Deep Neural Networks (DNNs) have been shown to be well-suited to process these sensor data in an accurate and efficient manner. Nevertheless, the space of DNNs' architectures is huge and its manual exploration is burdensome and often leads to sub-optimal solutions. To overcome this problem, in this work, we propose a highly automated full-stack optimization flow for DNNs that goes from neural architecture search, mixed-precision quantization, and post-processing, down to the realization of a new smart sensor prototype, including a Microcontroller with a customized instruction set. Integrating these cross-layer optimizations, we obtain a large set of Pareto-optimal solutions in the 3D-space of energy, memory, and accuracy. Deploying such solutions on our hardware platform, we improve the state-of-the-art achieving up to 4.2x model size reduction, 23.8x code size reduction, and 15.38x energy reduction at iso-accuracy.