 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing OpenTitan's Potential: a Silicon-Ready Embedded Secure Element for Root of Trust and Cryptographic Offloading
Jun 17, 2024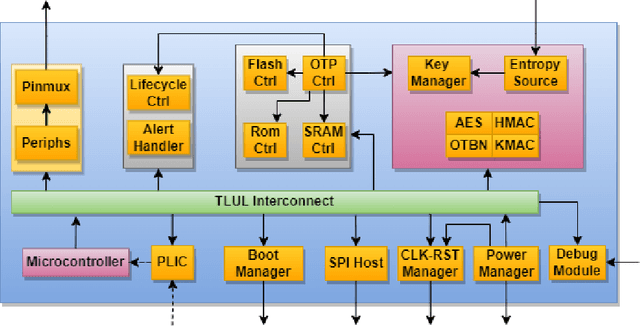

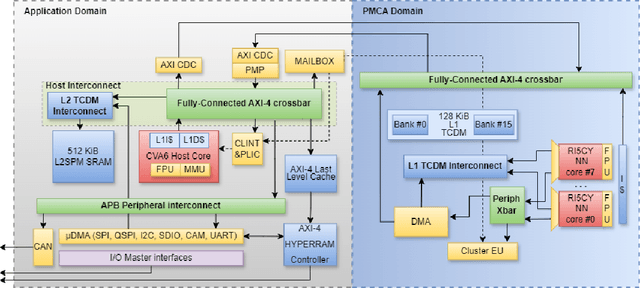
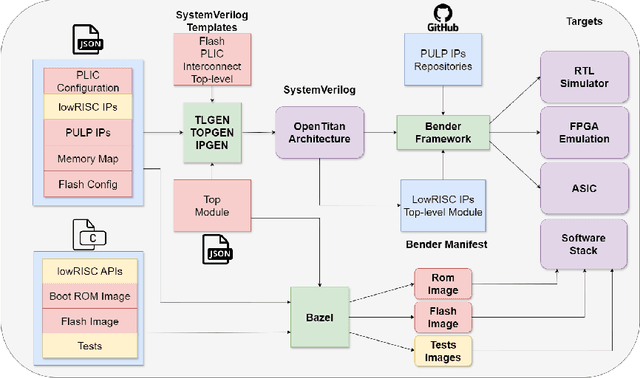
The rapid advancement and exploration of open-hardware RISC-V platforms are driving significant changes in sectors like autonomous vehicles, smart-city infrastructure, and medical devices. OpenTitan stands out as a groundbreaking open-source RISC-V design with a comprehensive security toolkit as a standalone system-on-chip (SoC). OpenTitan includes Earl Grey, a fully implemented and silicon-proven SoC, and Darjeeling, announced but not yet fully implemented. Earl Grey targets standalone SoC implementations, while Darjeeling is for integrable implementations. The literature lacks a silicon-ready embedded implementation of an open-source Root of Trust, despite lowRISC's efforts on Darjeeling. We address the limitations of existing implementations by optimizing data transfer latency between memory and cryptographic accelerators to prevent under-utilization and ensure efficient task acceleration. Our contributions include a comprehensive methodology for integrating custom extensions and IPs into the Earl Grey architecture, architectural enhancements for system-level integration, support for varied boot modes, and improved data movement across the platform. These advancements facilitate deploying OpenTitan in broader SoCs, even without specific technology-dependent IPs, providing a deployment-ready research vehicle for the community. We integrated the extended Earl Grey architecture into a reference architecture in a 22nm FDX technology node, benchmarking the enhanced architecture's performance. The results show significant improvements in cryptographic processing speed, achieving up to 2.7x speedup for SHA-256/HMAC and 1.6x for AES accelerators compared to the baseline Earl Grey architecture.
Foundation Models for Structural Health Monitoring
Apr 03, 2024



Structural Health Monitoring (SHM) is a critical task for ensuring the safety and reliability of civil infrastructures, typically realized on bridges and viaducts by means of vibration monitoring. In this paper, we propose for the first time the use of Transformer neural networks, with a Masked Auto-Encoder architecture, as Foundation Models for SHM. We demonstrate the ability of these models to learn generalizable representations from multiple large datasets through self-supervised pre-training, which, coupled with task-specific fine-tuning, allows them to outperform state-of-the-art traditional methods on diverse tasks, including Anomaly Detection (AD) and Traffic Load Estimation (TLE). We then extensively explore model size versus accuracy trade-offs and experiment with Knowledge Distillation (KD) to improve the performance of smaller Transformers, enabling their embedding directly into the SHM edge nodes. We showcase the effectiveness of our foundation models using data from three operational viaducts. For AD, we achieve a near-perfect 99.9% accuracy with a monitoring time span of just 15 windows. In contrast, a state-of-the-art method based on Principal Component Analysis (PCA) obtains its first good result (95.03% accuracy) only considering 120 windows. On two different TLE tasks, our models obtain state-of-the-art performance on multiple evaluation metrics (R$^2$ score, MAE% and MSE%). On the first benchmark, we achieve an R$^2$ score of 0.97 and 0.85 for light and heavy vehicle traffic, respectively, while the best previous approach stops at 0.91 and 0.84. On the second one, we achieve an R$^2$ score of 0.54 versus the 0.10 of the best existing method.
Trimming Feature Extraction and Inference for MCU-based Edge NILM: a Systematic Approach
May 21, 2021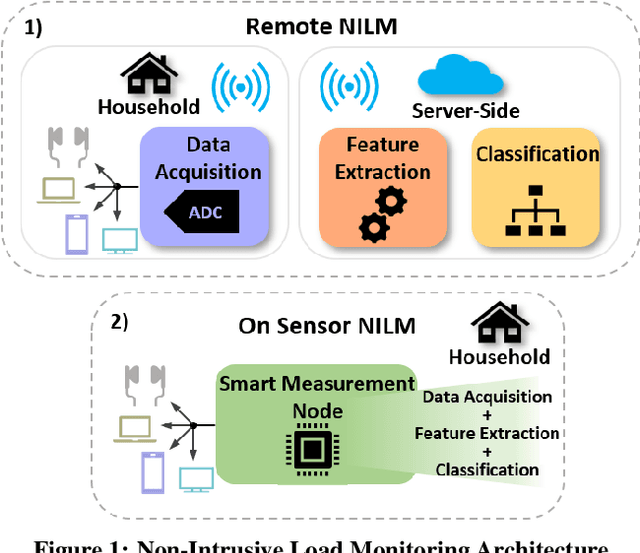
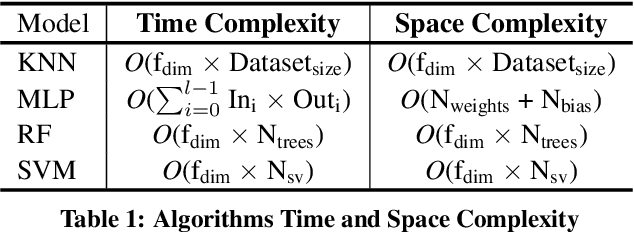

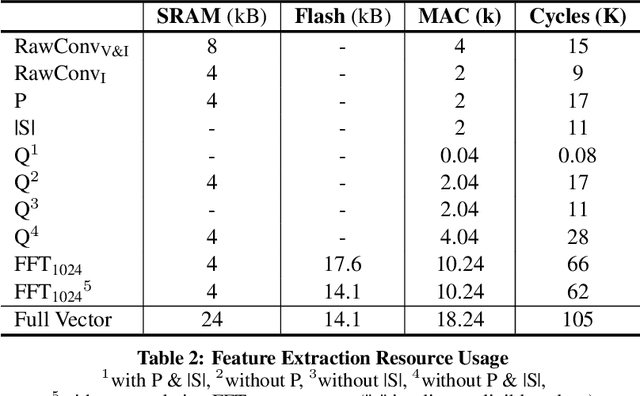
Non-Intrusive Load Monitoring (NILM) enables the disaggregation of the global power consumption of multiple loads, taken from a single smart electrical meter, into appliance-level details. State-of-the-Art approaches are based on Machine Learning methods and exploit the fusion of time- and frequency-domain features from current and voltage sensors. Unfortunately, these methods are compute-demanding and memory-intensive. Therefore, running low-latency NILM on low-cost, resource-constrained MCU-based meters is currently an open challenge. This paper addresses the optimization of the feature spaces as well as the computational and storage cost reduction needed for executing State-of-the-Art (SoA) NILM algorithms on memory- and compute-limited MCUs. We compare four supervised learning techniques on different classification scenarios and characterize the overall NILM pipeline's implementation on a MCU-based Smart Measurement Node. Experimental results demonstrate that optimizing the feature space enables edge MCU-based NILM with 95.15% accuracy, resulting in a small drop compared to the most-accurate feature vector deployment (96.19%) while achieving up to 5.45x speed-up and 80.56% storage reduction. Furthermore, we show that low-latency NILM relying only on current measurements reaches almost 80% accuracy, allowing a major cost reduction by removing voltage sensors from the hardware design.
Source Code Classification for Energy Efficiency in Parallel Ultra Low-Power Microcontrollers
Dec 12, 2020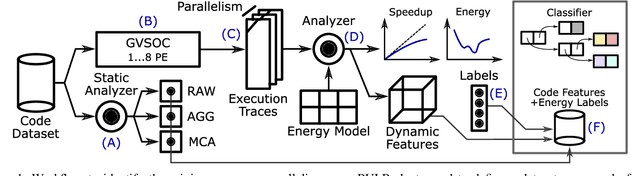
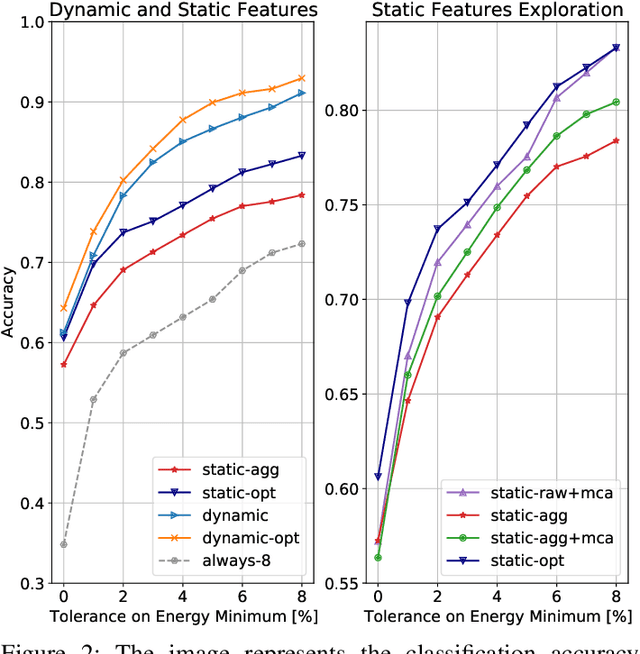
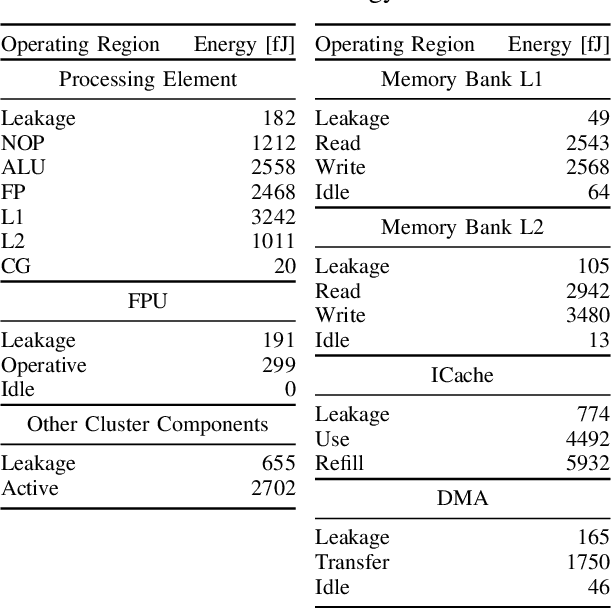

The analysis of source code through machine learning techniques is an increasingly explored research topic aiming at increasing smartness in the software toolchain to exploit modern architectures in the best possible way. In the case of low-power, parallel embedded architectures, this means finding the configuration, for instance in terms of the number of cores, leading to minimum energy consumption. Depending on the kernel to be executed, the energy optimal scaling configuration is not trivial. While recent work has focused on general-purpose systems to learn and predict the best execution target in terms of the execution time of a snippet of code or kernel (e.g. offload OpenCL kernel on multicore CPU or GPU), in this work we focus on static compile-time features to assess if they can be successfully used to predict the minimum energy configuration on PULP, an ultra-low-power architecture featuring an on-chip cluster of RISC-V processors. Experiments show that using machine learning models on the source code to select the best energy scaling configuration automatically is viable and has the potential to be used in the context of automatic system configuration for energy minimisation.
Learning Behavioral Representations of Human Mobility
Sep 11, 2020

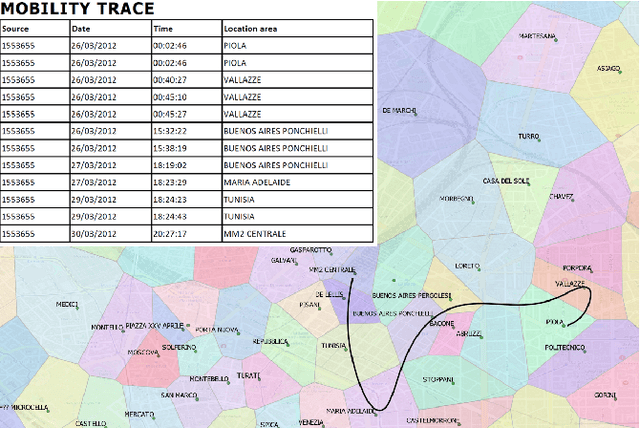

In this paper, we investigate the suitability of state-of-the-art representation learning methods to the analysis of behavioral similarity of moving individuals, based on CDR trajectories. The core of the contribution is a novel methodological framework, mob2vec, centered on the combined use of a recent symbolic trajectory segmentation method for the removal of noise, a novel trajectory generalization method incorporating behavioral information, and an unsupervised technique for the learning of vector representations from sequential data. Mob2vec is the result of an empirical study conducted on real CDR data through an extensive experimentation. As a result, it is shown that mob2vec generates vector representations of CDR trajectories in low dimensional spaces which preserve the similarity of the mobility behavior of individuals.