 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNN is not all you need: Parallelizing Non-Neural ML Algorithms on Ultra-Low-Power IoT Processors
Jul 16, 2021
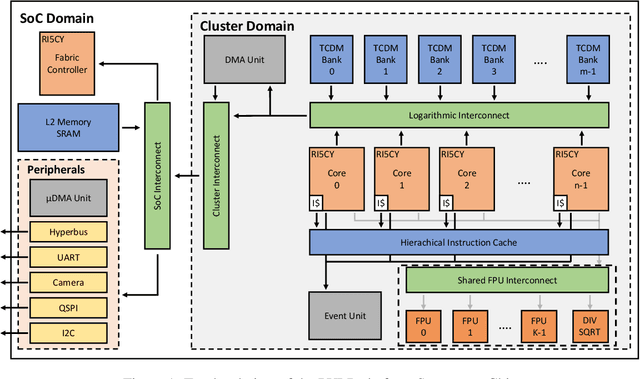
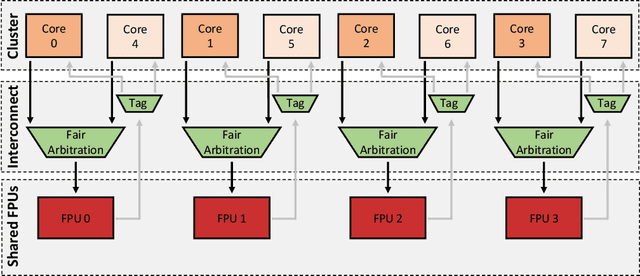
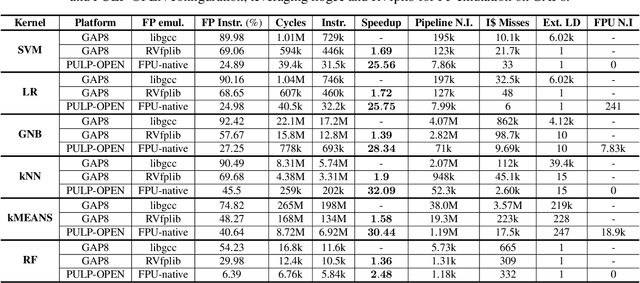
Machine Learning (ML) functions are becoming ubiquitous in latency- and privacy-sensitive IoT applications, prompting for a shift toward near-sensor processing at the extreme edge and the consequent increasing adoption of Parallel Ultra-Low Power (PULP) IoT processors. These compute- and memory-constrained parallel architectures need to run efficiently a wide range of algorithms, including key Non-Neural ML kernels that compete favorably with Deep Neural Networks (DNNs) in terms of accuracy under severe resource constraints. In this paper, we focus on enabling efficient parallel execution of Non-Neural ML algorithms on two RISCV-based PULP platforms, namely GAP8, a commercial chip, and PULP-OPEN, a research platform running on an FPGA emulator. We optimized the parallel algorithms through a fine-grained analysis and intensive optimization to maximize the speedup, considering two alternative Floating-Point (FP) emulation libraries on GAP8 and the native FPU support on PULP-OPEN. Experimental results show that a target-optimized emulation library can lead to an average 1.61x runtime improvement compared to a standard emulation library, while the native FPU support reaches up to 32.09x. In terms of parallel speedup, our design improves the sequential execution by 7.04x on average on the targeted octa-core platforms. Lastly, we present a comparison with the ARM Cortex-M4 microcontroller (MCU), a widely adopted commercial solution for edge deployments, which is 12.87$x slower than PULP-OPEN.
Towards Long-term Non-invasive Monitoring for Epilepsy via Wearable EEG Devices
Jun 17, 2021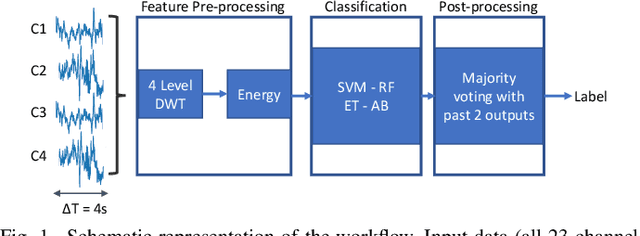
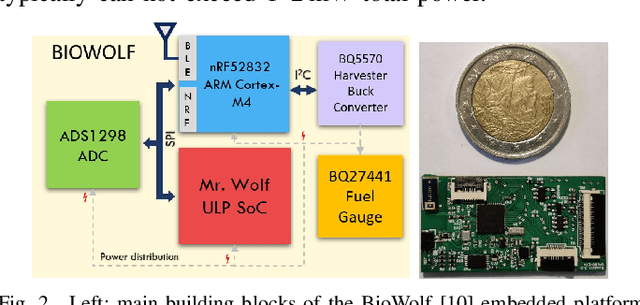
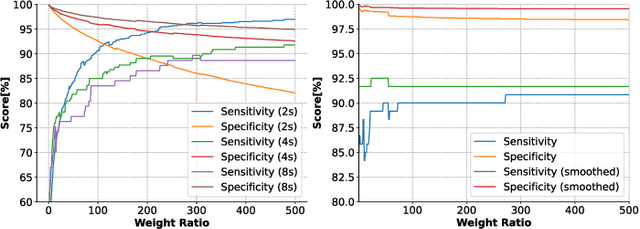
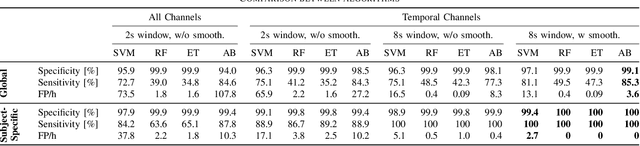
We present the implementation of seizure detection algorithms based on a minimal number of EEG channels on a parallel ultra-low-power embedded platform. The analyses are based on the CHB-MIT dataset, and include explorations of different classification approaches (Support Vector Machines, Random Forest, Extra Trees, AdaBoost) and different pre/post-processing techniques to maximize sensitivity while guaranteeing no false alarms. We analyze global and subject-specific approaches, considering all 23-electrodes or only 4 temporal channels. For 8s window size and subject-specific approach, we report zero false positives and 100% sensitivity. These algorithms are parallelized and optimized for a parallel ultra-low power (PULP) platform, enabling 300h of continuous monitoring on a 300 mAh battery, in a wearable form factor and power budget. These results pave the way for the implementation of affordable, wearable, long-term epilepsy monitoring solutions with low false-positive rates and high sensitivity, meeting both patient and caregiver requirements.
Trimming Feature Extraction and Inference for MCU-based Edge NILM: a Systematic Approach
May 21, 2021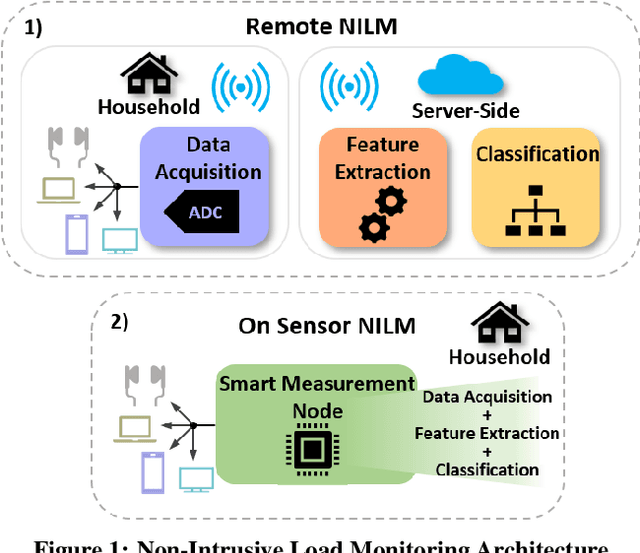
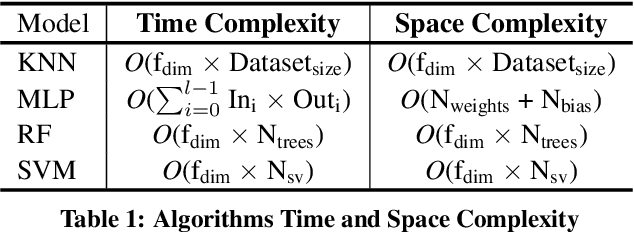

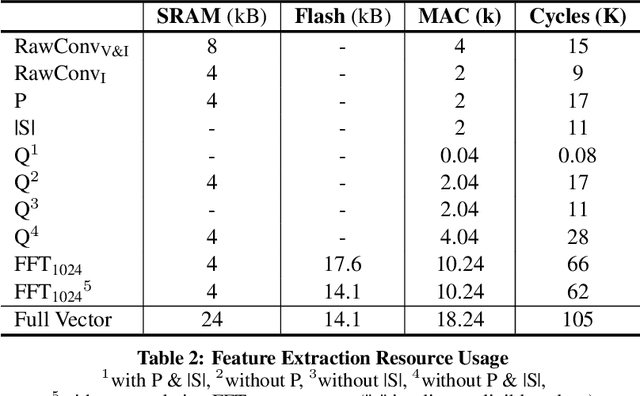
Non-Intrusive Load Monitoring (NILM) enables the disaggregation of the global power consumption of multiple loads, taken from a single smart electrical meter, into appliance-level details. State-of-the-Art approaches are based on Machine Learning methods and exploit the fusion of time- and frequency-domain features from current and voltage sensors. Unfortunately, these methods are compute-demanding and memory-intensive. Therefore, running low-latency NILM on low-cost, resource-constrained MCU-based meters is currently an open challenge. This paper addresses the optimization of the feature spaces as well as the computational and storage cost reduction needed for executing State-of-the-Art (SoA) NILM algorithms on memory- and compute-limited MCUs. We compare four supervised learning techniques on different classification scenarios and characterize the overall NILM pipeline's implementation on a MCU-based Smart Measurement Node. Experimental results demonstrate that optimizing the feature space enables edge MCU-based NILM with 95.15% accuracy, resulting in a small drop compared to the most-accurate feature vector deployment (96.19%) while achieving up to 5.45x speed-up and 80.56% storage reduction. Furthermore, we show that low-latency NILM relying only on current measurements reaches almost 80% accuracy, allowing a major cost reduction by removing voltage sensors from the hardware design.