 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallelization is All System Identification Needs: End-to-end Vibration Diagnostics on a multi-core RISC-V edge device
Apr 07, 2025The early detection of structural malfunctions requires the installation of real-time monitoring systems ensuring continuous access to the damage-sensitive information; nevertheless, it can generate bottlenecks in terms of bandwidth and storage. Deploying data reduction techniques at the edge is recognized as a proficient solution to reduce the system's network traffic. However, the most effective solutions currently employed for the purpose are based on memory and power-hungry algorithms, making their embedding on resource-constrained devices very challenging; this is the case of vibration data reduction based on System Identification models. This paper presents PARSY-VDD, a fully optimized PArallel end-to-end software framework based on SYstem identification for Vibration-based Damage Detection, as a suitable solution to perform damage detection at the edge in a time and energy-efficient manner, avoiding streaming raw data to the cloud. We evaluate the damage detection capabilities of PARSY-VDD with two benchmarks: a bridge and a wind turbine blade, showcasing the robustness of the end-to-end approach. Then, we deploy PARSY-VDD on both commercial single-core and a specific multi-core edge device. We introduce an architecture-agnostic algorithmic optimization for SysId, improving the execution by 90x and reducing the consumption by 85x compared with the state-of-the-art SysId implementation on GAP9. Results show that by utilizing the unique parallel computing capabilities of GAP9, the execution time is 751{\mu}s with the high-performance multi-core solution operating at 370MHz and 0.8V, while the energy consumption is 37{\mu}J with the low-power solution operating at 240MHz and 0.65V. Compared with other single-core implementations based on STM32 microcontrollers, the GAP9 high-performance configuration is 76x faster, while the low-power configuration is 360x more energy efficient.
Open-Source Heterogeneous SoCs for AI: The PULP Platform Experience
Dec 29, 2024



Since 2013, the PULP (Parallel Ultra-Low Power) Platform project has been one of the most active and successful initiatives in designing research IPs and releasing them as open-source. Its portfolio now ranges from processor cores to network-on-chips, peripherals, SoC templates, and full hardware accelerators. In this article, we focus on the PULP experience designing heterogeneous AI acceleration SoCs - an endeavour encompassing SoC architecture definition; development, verification, and integration of acceleration IPs; front- and back-end VLSI design; testing; development of AI deployment software.
Vega: A 10-Core SoC for IoT End-Nodes with DNN Acceleration and Cognitive Wake-Up From MRAM-Based State-Retentive Sleep Mode
Oct 18, 2021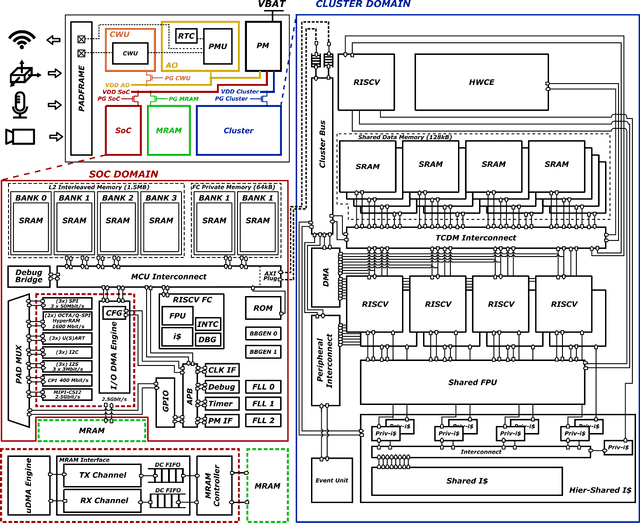
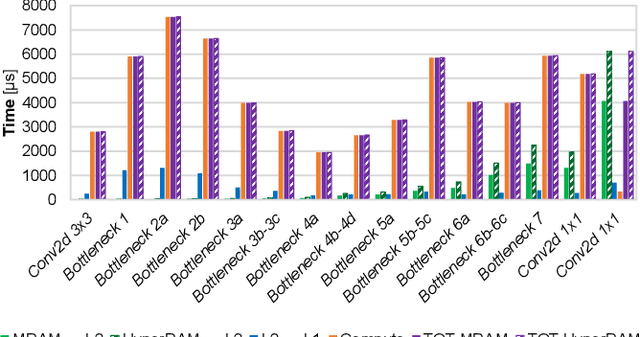
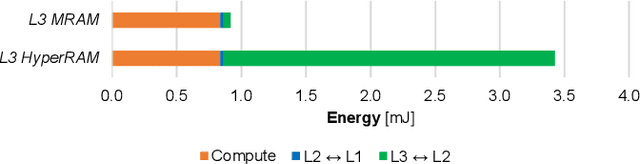
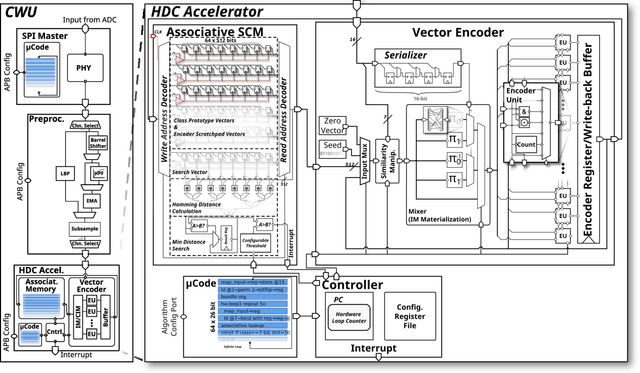
The Internet-of-Things requires end-nodes with ultra-low-power always-on capability for a long battery lifetime, as well as high performance, energy efficiency, and extreme flexibility to deal with complex and fast-evolving near-sensor analytics algorithms (NSAAs). We present Vega, an IoT end-node SoC capable of scaling from a 1.7 $\mathrm{\mu}$W fully retentive cognitive sleep mode up to 32.2 GOPS (@ 49.4 mW) peak performance on NSAAs, including mobile DNN inference, exploiting 1.6 MB of state-retentive SRAM, and 4 MB of non-volatile MRAM. To meet the performance and flexibility requirements of NSAAs, the SoC features 10 RISC-V cores: one core for SoC and IO management and a 9-cores cluster supporting multi-precision SIMD integer and floating-point computation. Vega achieves SoA-leading efficiency of 615 GOPS/W on 8-bit INT computation (boosted to 1.3TOPS/W for 8-bit DNN inference with hardware acceleration). On floating-point (FP) compuation, it achieves SoA-leading efficiency of 79 and 129 GFLOPS/W on 32- and 16-bit FP, respectively. Two programmable machine-learning (ML) accelerators boost energy efficiency in cognitive sleep and active states, respectively.
DNN is not all you need: Parallelizing Non-Neural ML Algorithms on Ultra-Low-Power IoT Processors
Jul 16, 2021
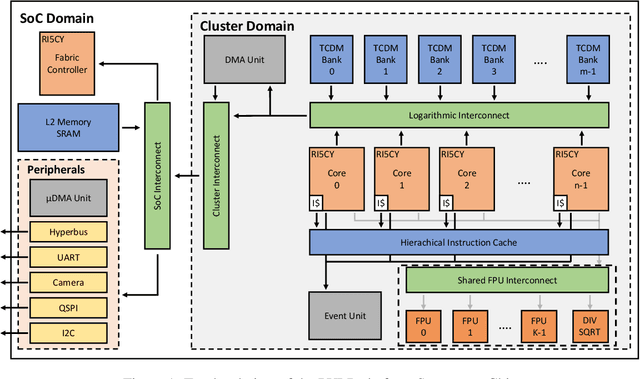
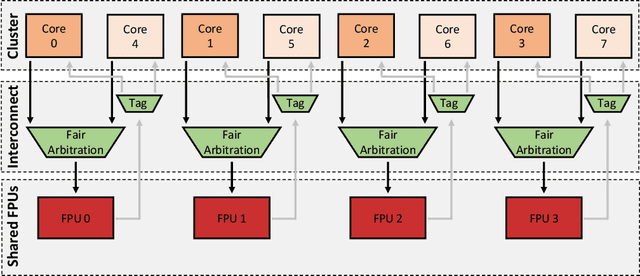
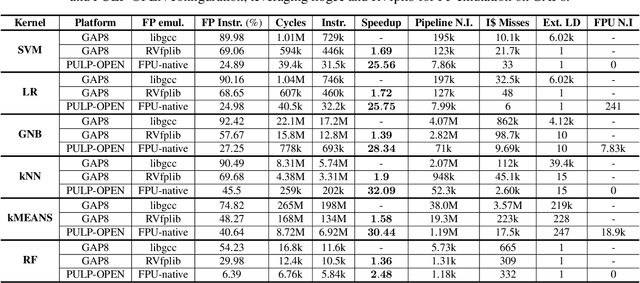
Machine Learning (ML) functions are becoming ubiquitous in latency- and privacy-sensitive IoT applications, prompting for a shift toward near-sensor processing at the extreme edge and the consequent increasing adoption of Parallel Ultra-Low Power (PULP) IoT processors. These compute- and memory-constrained parallel architectures need to run efficiently a wide range of algorithms, including key Non-Neural ML kernels that compete favorably with Deep Neural Networks (DNNs) in terms of accuracy under severe resource constraints. In this paper, we focus on enabling efficient parallel execution of Non-Neural ML algorithms on two RISCV-based PULP platforms, namely GAP8, a commercial chip, and PULP-OPEN, a research platform running on an FPGA emulator. We optimized the parallel algorithms through a fine-grained analysis and intensive optimization to maximize the speedup, considering two alternative Floating-Point (FP) emulation libraries on GAP8 and the native FPU support on PULP-OPEN. Experimental results show that a target-optimized emulation library can lead to an average 1.61x runtime improvement compared to a standard emulation library, while the native FPU support reaches up to 32.09x. In terms of parallel speedup, our design improves the sequential execution by 7.04x on average on the targeted octa-core platforms. Lastly, we present a comparison with the ARM Cortex-M4 microcontroller (MCU), a widely adopted commercial solution for edge deployments, which is 12.87$x slower than PULP-OPEN.
Towards Long-term Non-invasive Monitoring for Epilepsy via Wearable EEG Devices
Jun 17, 2021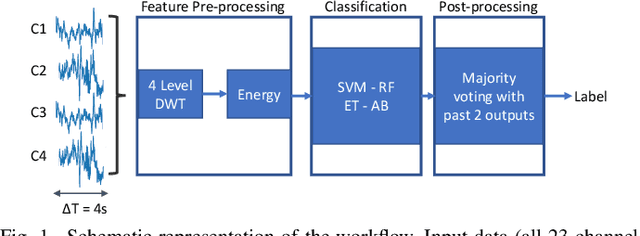
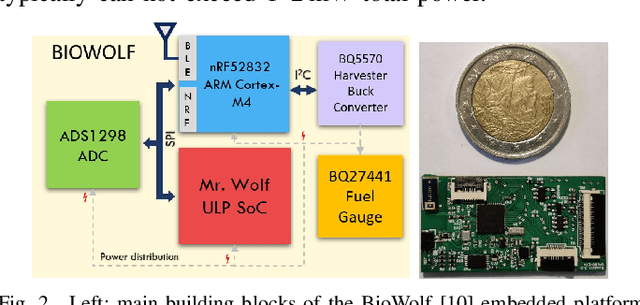
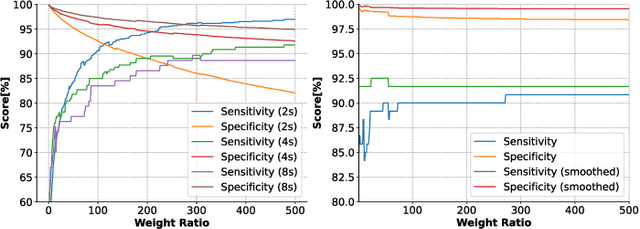
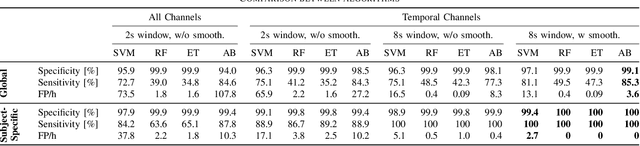
We present the implementation of seizure detection algorithms based on a minimal number of EEG channels on a parallel ultra-low-power embedded platform. The analyses are based on the CHB-MIT dataset, and include explorations of different classification approaches (Support Vector Machines, Random Forest, Extra Trees, AdaBoost) and different pre/post-processing techniques to maximize sensitivity while guaranteeing no false alarms. We analyze global and subject-specific approaches, considering all 23-electrodes or only 4 temporal channels. For 8s window size and subject-specific approach, we report zero false positives and 100% sensitivity. These algorithms are parallelized and optimized for a parallel ultra-low power (PULP) platform, enabling 300h of continuous monitoring on a 300 mAh battery, in a wearable form factor and power budget. These results pave the way for the implementation of affordable, wearable, long-term epilepsy monitoring solutions with low false-positive rates and high sensitivity, meeting both patient and caregiver requirements.
Source Code Classification for Energy Efficiency in Parallel Ultra Low-Power Microcontrollers
Dec 12, 2020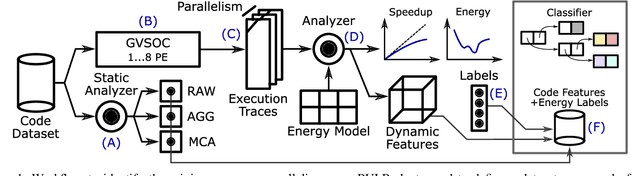
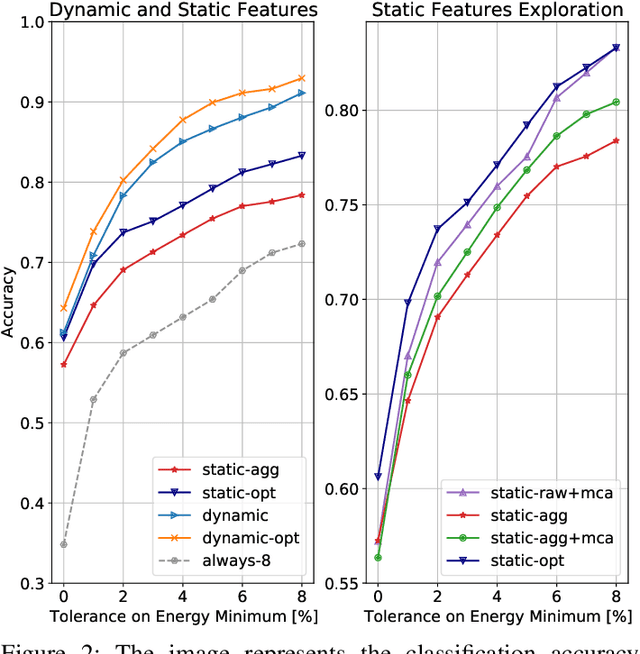
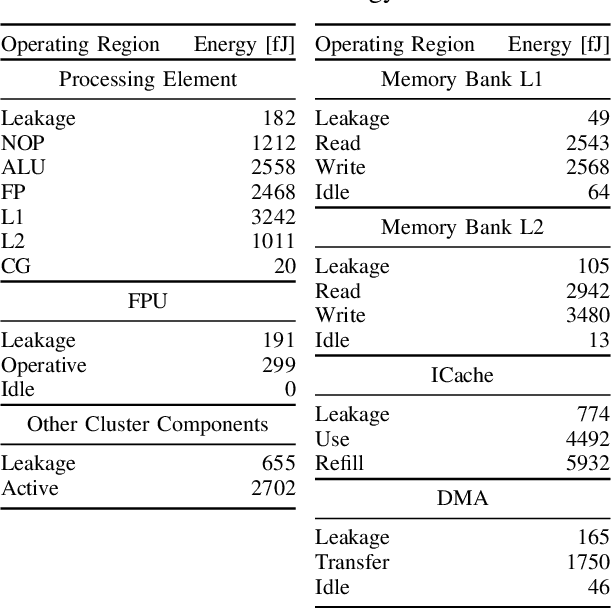

The analysis of source code through machine learning techniques is an increasingly explored research topic aiming at increasing smartness in the software toolchain to exploit modern architectures in the best possible way. In the case of low-power, parallel embedded architectures, this means finding the configuration, for instance in terms of the number of cores, leading to minimum energy consumption. Depending on the kernel to be executed, the energy optimal scaling configuration is not trivial. While recent work has focused on general-purpose systems to learn and predict the best execution target in terms of the execution time of a snippet of code or kernel (e.g. offload OpenCL kernel on multicore CPU or GPU), in this work we focus on static compile-time features to assess if they can be successfully used to predict the minimum energy configuration on PULP, an ultra-low-power architecture featuring an on-chip cluster of RISC-V processors. Experiments show that using machine learning models on the source code to select the best energy scaling configuration automatically is viable and has the potential to be used in the context of automatic system configuration for energy minimisation.
DORY: Automatic End-to-End Deployment of Real-World DNNs on Low-Cost IoT MCUs
Aug 17, 2020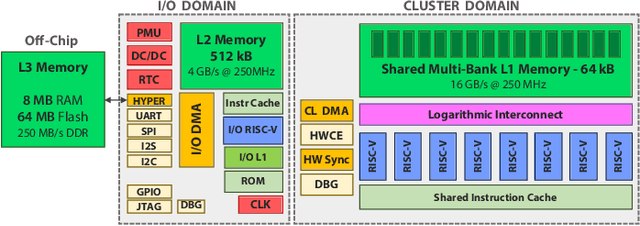


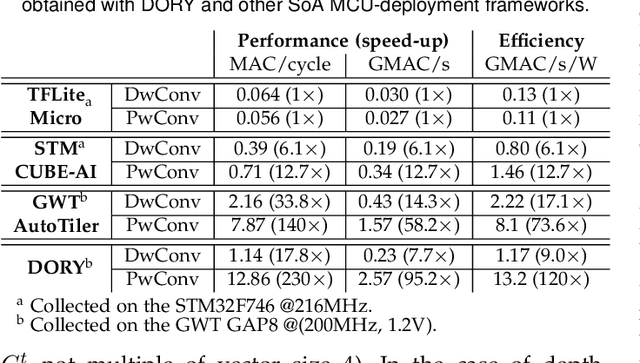
The deployment of Deep Neural Networks (DNNs) on end-nodes at the extreme edge of the Internet-of-Things is a critical enabler to support pervasive Deep Learning-enhanced applications. Low-Cost MCU-based end-nodes have limited on-chip memory and often replace caches with scratchpads, to reduce area overheads and increase energy efficiency -- requiring explicit DMA-based memory transfers between different levels of the memory hierarchy. Mapping modern DNNs on these systems requires aggressive topology-dependent tiling and double-buffering. In this work, we propose DORY (Deployment Oriented to memoRY) - an automatic tool to deploy DNNs on low cost MCUs with typically less than 1MB of on-chip SRAM memory. DORY abstracts tiling as a Constraint Programming (CP) problem: it maximizes L1 memory utilization under the topological constraints imposed by each DNN layer. Then, it generates ANSI C code to orchestrate off- and on-chip transfers and computation phases. Furthermore, to maximize speed, DORY augments the CP formulation with heuristics promoting performance-effective tile sizes. As a case study for DORY, we target GreenWaves Technologies GAP8, one of the most advanced parallel ultra-low power MCU-class devices on the market. On this device, DORY achieves up to 2.5x better MAC/cycle than the GreenWaves proprietary software solution and 18.1x better than the state-of-the-art result on an STM32-F746 MCU on single layers. Using our tool, GAP-8 can perform end-to-end inference of a 1.0-MobileNet-128 network consuming just 63 pJ/MAC on average @ 4.3 fps - 15.4x better than an STM32-F746. We release all our developments - the DORY framework, the optimized backend kernels, and the related heuristics - as open-source software.